[논문 리뷰] RoBERTa-BiLSTM: A Context-Aware Hybrid Model for Sentiment Analysis
본 논문은 RoBERTa-BiLSTM으로, RoBERTa를 사용하여 단어 임베딩을 생성하고 BiLSTM으로 장거리 의존성을 포착하는 하이브리드 모델을 제안하며, 세 가지 데이터셋에서 최첨단 감정 분석 성능을 달성합니다.
Effectively analyzing the comments to uncover latent intentions holds immense value in making strategic decisions across various domains. However, several challenges hinder the process of sentiment analysis including the lexical diversity exhibited in comments, the presence of long dependencies within the text, encountering unknown symbols and words, and dealing with imbalanced datasets. Moreover, existing sentiment analysis tasks mostly leveraged sequential models to encode the long dependent texts and it requires longer execution time as it processes the text sequentially. In contrast, the Transformer requires less execution time due to its parallel processing nature. In this work, we introduce a novel hybrid deep learning model, RoBERTa-BiLSTM, which combines the Robustly Optimized BERT Pretraining Approach (RoBERTa) with Bidirectional Long Short-Term Memory (BiLSTM) networks. RoBERTa is utilized to generate meaningful word embedding vectors, while BiLSTM effectively captures the contextual semantics of long-dependent texts. The RoBERTa-BiLSTM hybrid model leverages the strengths of both sequential and Transformer models to enhance performance in sentiment analysis. We conducted experiments using datasets from IMDb, Twitter US Airline, and Sentiment140 to evaluate the proposed model against existing state-of-the-art methods. Our experimental findings demonstrate that the RoBERTa-BiLSTM model surpasses baseline models (e.g., BERT, RoBERTa-base, RoBERTa-GRU, and RoBERTa-LSTM), achieving accuracies of 80.74%, 92.36%, and 82.25% on the Twitter US Airline, IMDb, and Sentiment140 datasets, respectively. Additionally, the model achieves F1-scores of 80.73%, 92.35%, and 82.25% on the same datasets, respectively.
연구 동기 및 목표
- 다양한 온라인 댓글에서 어휘 다양성, 긴 의존성, 불균형 데이터 속에서 감정 분석의 필요성을 제고한다.
- RoBERTa 임베딩과 BiLSTM을 결합한 맥락 인식 하이브리드 모델을 제안하여 성능 향상을 도모한다.
- 다수의 데이터셋에서 RoBERTa-BiLSTM을 최첨단 기준선과 비교 평가한다.
- 데이터 전처리와 하이퍼파라미터 튜닝이 모델 성능에 미치는 영향을 분석한다.
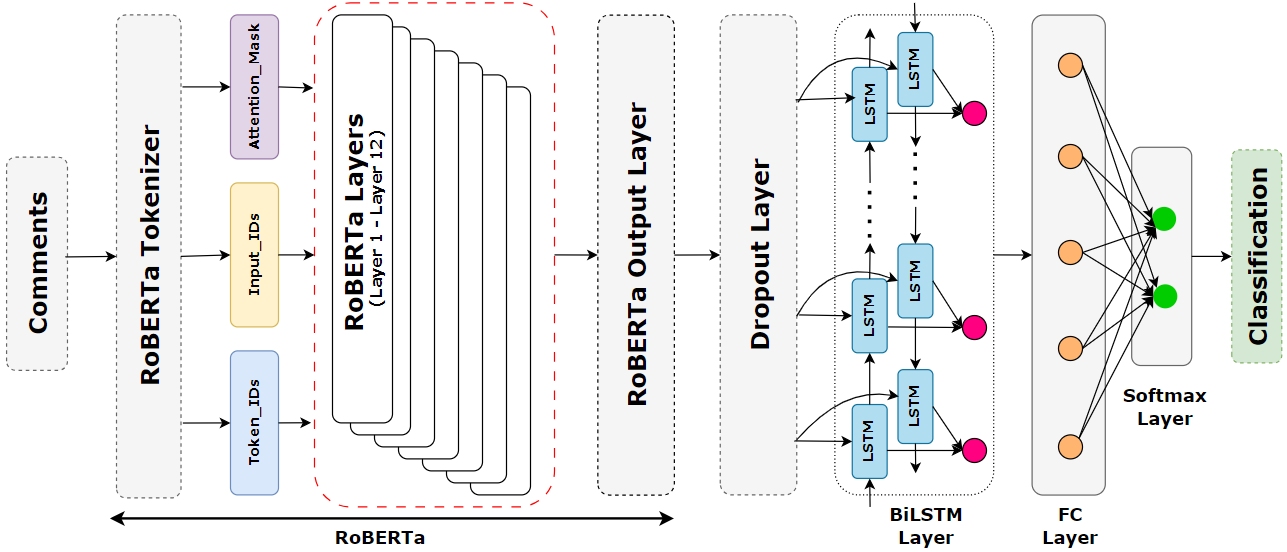
제안 방법
- encoder로 RoBERTa를 활용하여 맥락 단어 임베딩을 생성한다.
- RoBERTa 임베딩을 Dropout 층이 있는 BiLSTM으로 전달하여 긴 거리 의존성을 포착한다.
- BiLSTM 출력과 매핑하기 위한 Dense 층과 Softmax 분류기를 추가하여 감정 클래스로 매핑한다.
- RoBERTa 토큰화 전에 소문자화, 노이즈 제거, 어간추출(lematization) 등의 데이터 전처리를 적용한다.
- 학습률, 숨겨진 유닛 수 등 하이퍼파라미터를 튜닝하고 LSTM/GRU 변형과 비교한다.
- 다중 클래스 감정 분류를 위해 교차 엔트로피 손실을 사용한다.
실험 결과
연구 질문
- RQ1RoBERTa-BiLSTM 하이브리드 모델이 감정 분석 태스크에서 표준 RoBERTa 변형(base, GRU, LSTM)을 능가할 수 있는가?
- RQ2데이터 전처리 선택과 하이퍼파라미터 튜닝이 모델의 성능에 어떤 영향을 미치는가?
- RQ3다양한 클래스 분포를 갖는 IMDb, Twitter US Airline, Sentiment140 데이터셋에서 모델의 성능은 어떠한가?
주요 결과
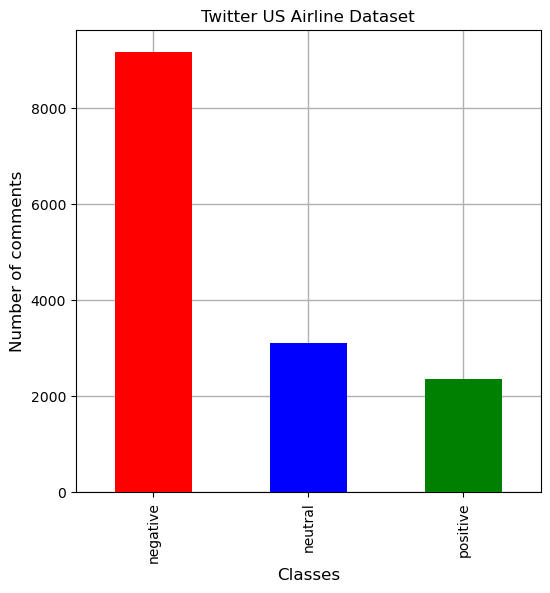
- RoBERTa-BiLSTM은 Twitter US Airline에서 80.74% 정확도를 달성한다.
- RoBERTa-BiLSTM은 IMDb에서 92.36% 정확도를 달성한다.
- RoBERTa-BiLSTM은 Sentiment140에서 82.25% 정확도를 달성한다.
- RoBERTa-BiLSTM은 Twitter US Airline에서 F1-점수 80.73%, IMDb에서 92.35%, Sentiment140에서 82.25%를 달성한다.
- 제시된 데이터셋에서 RoBERTa-base, RoBERTa-GRU, RoBERTa-LSTM 기본선보다 모델이 우수한 성능을 보인다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.