[논문 리뷰] Robust CLIP: Unsupervised Adversarial Fine-Tuning of Vision Embeddings for Robust Large Vision-Language Models
이 논문은 CLIP 비전 인코더를 위한 비지도적 적대적 미세조정 방법인 FARE를 소개하며, 원래 임베딩을 보존하면서 강건성을 향상시켜 재학습 없이도 강건한 다운스트림 VLM을 가능하게 한다.
Multi-modal foundation models like OpenFlamingo, LLaVA, and GPT-4 are increasingly used for various real-world tasks. Prior work has shown that these models are highly vulnerable to adversarial attacks on the vision modality. These attacks can be leveraged to spread fake information or defraud users, and thus pose a significant risk, which makes the robustness of large multi-modal foundation models a pressing problem. The CLIP model, or one of its variants, is used as a frozen vision encoder in many large vision-language models (LVLMs), e.g. LLaVA and OpenFlamingo. We propose an unsupervised adversarial fine-tuning scheme to obtain a robust CLIP vision encoder, which yields robustness on all vision down-stream tasks (LVLMs, zero-shot classification) that rely on CLIP. In particular, we show that stealth-attacks on users of LVLMs by a malicious third party providing manipulated images are no longer possible once one replaces the original CLIP model with our robust one. No retraining or fine-tuning of the down-stream LVLMs is required. The code and robust models are available at https://github.com/chs20/RobustVLM
연구 동기 및 목표
- 멀티모달 기초 모델에서 시각 인코더가 적대적 공격에 취약한 문제를 해결한다.
- Clean한 작업 성능을 보존하면서 강건한 CLIP 임베딩을 얻는 비지도 미세조정 스키마를 개발한다.
- retraining 없이 다운스트림 비전-언어 모델(VLM)로의 강건성 전달을 보장한다.
- 기존의 감독된 방법과 비지도 FARE를 비교하고 전반적인 강건성 향상을 보여준다.
제안 방법
- 깨끗한 입력에서 원래 CLIP 임베딩을 보존하는 임베딩 기반 적대적 미세조정 목표를 형식화한다.
- FARE 손실을 깨끗한 이미지의 원래 CLIP 임베딩과 미세조정된 임베딩 간의 최대 제곱 거리로 정의한다.
- 미세조정 중 적대적 섭 perturbations를 생성하기 위해 내부 최대화 문제를 PGD로 해결한다.
- 임베딩 차이를 최소화하는 것이 다운스트림 작업에서 사용되는 코사인 유사도도 보존함을 보여준다.
- 언어 또는 통합 구성요소를 재학습하지 않고 기존 VLM에서 robust한 FARE-CLIP으로 대체한다.
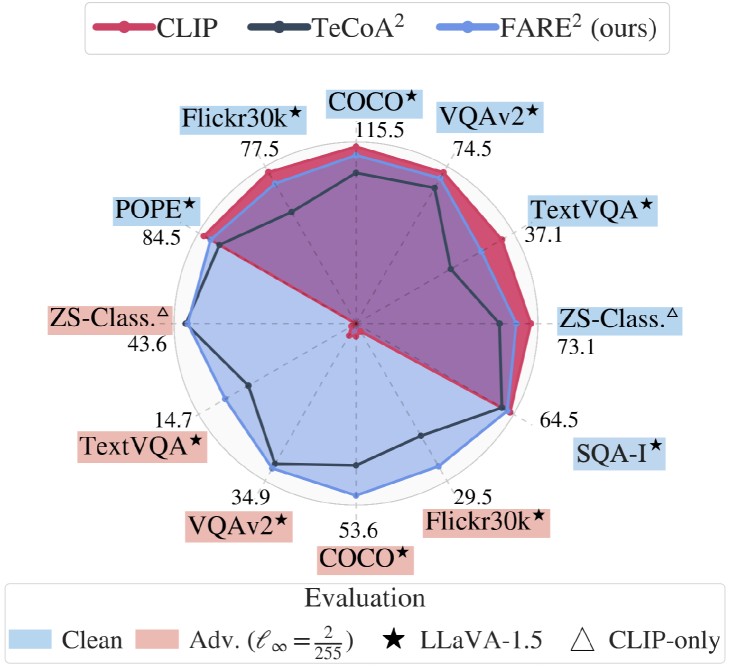
실험 결과
연구 질문
- RQ1CLIP의 이미지 인코더에 대한 비지도적 적대적 미세조정 목적이 깨끗한 다운스트림 성능을 저하시키지 않으면서 강건한 임베딩을 생성할 수 있는가?
- RQ2원래 임베딩 동작을 유지하면서 강건성을 추가하면 OpenFlamingo, LLaVA와 같은 비전-언어 모델에서 CLIP 인코더의 원활한 교체가 가능해지는가?
- RQ3FARE는 무표본 분류(zero-shot) 및 VLM 작업 전반에서 깨끗한 정확도와 강건성 측면에서 감독된 적대적 미세조정(TeCoA)과 어떻게 비교되는가?
주요 결과
- FARE는 깨끗한 데이터에서 원래 CLIP 임베딩과의 근접 정렬을 유지하여 VLM에서 재학습 없이 Plug-and-Play 교체를 가능하게 한다.
- 다수의 다운스트림 작업과 VLM에 걸친 l_infinity 적대적 교란에 대해 강건성 이점을 달성한다.
- FARE는 여러 제로샷 및 VLM 평가 작업에서 감독된 TeCoA 접근법보다 우수한 성능을 보이며, 깨끗한 성능도 보존한다.
- 강건한 CLIP 인코더를 VLM에 대체하면 모델 간 적대적 이미지의 전이 가능성이 줄고 표적 공격 성공률이 낮아진다.
- FARE는 TeCoA와 비교했을 때 환각 및 추론 벤치마크와 같은 추가 작업에서도 유리한 결과를 보인다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.