[논문 리뷰] Robust Distortion-free Watermarks for Language Models
이 논문은 distortion-free, robust 워터마크를 가지는 autoregressive 언어 모델에 대한 제시이며, agnostic 탐지와 함께 OPT-1.3B, LLaMA-7B, Alpaca-7B에서 상당한 편집에도 강한 탐지를 검증한다.
We propose a methodology for planting watermarks in text from an autoregressive language model that are robust to perturbations without changing the distribution over text up to a certain maximum generation budget. We generate watermarked text by mapping a sequence of random numbers -- which we compute using a randomized watermark key -- to a sample from the language model. To detect watermarked text, any party who knows the key can align the text to the random number sequence. We instantiate our watermark methodology with two sampling schemes: inverse transform sampling and exponential minimum sampling. We apply these watermarks to three language models -- OPT-1.3B, LLaMA-7B and Alpaca-7B -- to experimentally validate their statistical power and robustness to various paraphrasing attacks. Notably, for both the OPT-1.3B and LLaMA-7B models, we find we can reliably detect watermarked text ($p \leq 0.01$) from $35$ tokens even after corrupting between $40$-$50\%$ of the tokens via random edits (i.e., substitutions, insertions or deletions). For the Alpaca-7B model, we conduct a case study on the feasibility of watermarking responses to typical user instructions. Due to the lower entropy of the responses, detection is more difficult: around $25\%$ of the responses -- whose median length is around $100$ tokens -- are detectable with $p \leq 0.01$, and the watermark is also less robust to certain automated paraphrasing attacks we implement.
연구 동기 및 목표
- 언어 모델이 생성한 텍스트의 출처와 귀속에 대해 동기를 부여한다.
- 원문 분포를 보존하는 워터마크를 개발한다(왜곡 없는).
- 프롬프트 지식 없이도 작동하는 모델-무관(detector)을 만든다.
- 편집 및 의역과 같은 텍스트 변형 하에서도 워터마크 탐지의 강건성을 보장한다.
제안 방법
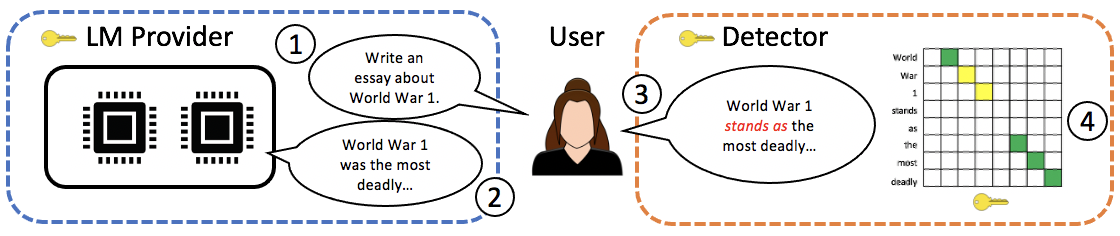
- LM 제공자와 탐지자 사이에 공유 워터마크 키를 가지는 워터마크 프로토콜을 정의한다.
- 무작위 키 시퀀스를 모델 샘플에 매핑하되 모델의 분포를 보존하는 generate 함수(왜곡 없는)를 도입한다.
- 워터마크 키에 의존하는지 여부를 테스트하고 p-value를 출력하는 robust한 시퀀스 정렬을 사용하는 detect 함수를 정의한다.
- 역변환 샘플링(inverse transform sampling)과 지수 최소 샘플링(exponential minimum sampling) 두 가지 샘플링 스키마를 구현한다.
- 다시 같은 워터마크 부분 시퀀스가 쿼리 간 재사용되지 않도록 하고 확률성을 유지하는 randomized wrapper shift_generate를 제공한다.
- 해독기의 왜곡-프리니스를 입증하고 텍스트 길이와 워터마크 키 길이에 따라 확장되는 p-value 경계치를 도출한다.
실험 결과
연구 질문
- RQ1워터마크를 텍스트 출력의 분포를 왜곡시키지 않으면서 어떻게 삽입할 수 있는가?
- RQ2상당한 텍스트 편집이나 의역 후에도 워터마크를 견고하게 탐지할 수 있는가?
- RQ3워터마크 가능성과 텍스트 길이가 주어졌을 때 탐지 가능성(p-value)에 대한 이론적 한계는 무엇인가?
- RQ4다른 샘플링 전략(inverse transform vs exponential minimum)이 파워와 강건성에 있어 어떻게 비교되는가?
주요 결과
- 워터마크는 왜곡-없음: generate 함수는 워터마크 키 시퀀스에 걸쳐 평균화될 때 기본 언어 모델과 동일한 분포의 텍스트를 생성한다.
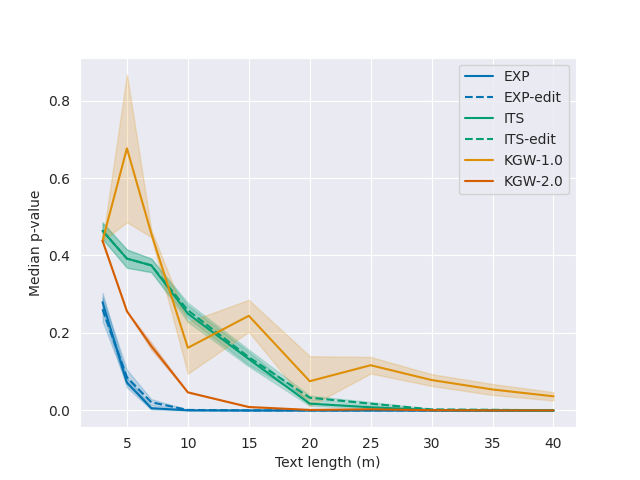
- 탐지 파워는 텍스트 길이에 따라 기하급수적으로 증가하고 워터마크 키 길이에 대해서는 선형적으로만 감소한다.
- exponential minimum sampling을 사용할 때 OPT-1.3B와 LLaMA-7B에서 40–50%의 토큰 치환/편집 후에도 35 토큰부터의 탐지에서 p ≤ 0.01의 탐지력을 달성한다.
- Alpaca-7B의 경우 대략 25%의 응답(중간 길이 약 100 토큰)이 p ≤ 0.01로 탐지되며 특정 자동 의역에 대한 강건성은 더 약하다.
- 대형 모델의 경우 의역(프랑스어/러시아어로의 번역 및 다시 번역) 하에서도 워터마크 탐지가 가능하지만 모델에 따라 강건성이 달라진다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.