[논문 리뷰] Robust Prompt Optimization for Defending Language Models Against Jailbreaking Attacks
이 논문은 미니맥스 방어 목표를 형식화하고, 보강 프롬프트 최적화(RPO)라는 그래디언트 기반 토큰-접미사 방법을 도입하여 보편적이고 전이 가능한 접미사로 jailbreaking에 대해 LMs를 방어하고 최첨단 강건성을 달성합니다.
Despite advances in AI alignment, large language models (LLMs) remain vulnerable to adversarial attacks or jailbreaking, in which adversaries can modify prompts to induce unwanted behavior. While some defenses have been proposed, they have not been adapted to newly proposed attacks and more challenging threat models. To address this, we propose an optimization-based objective for defending LLMs against jailbreaking attacks and an algorithm, Robust Prompt Optimization (RPO) to create robust system-level defenses. Our approach directly incorporates the adversary into the defensive objective and optimizes a lightweight and transferable suffix, enabling RPO to adapt to worst-case adaptive attacks. Our theoretical and experimental results show improved robustness to both jailbreaks seen during optimization and unknown jailbreaks, reducing the attack success rate (ASR) on GPT-4 to 6% and Llama-2 to 0% on JailbreakBench, setting the state-of-the-art. Code can be found at https://github.com/lapisrocks/rpo
연구 동기 및 목표
- LM jailbreaking에 대한 현실적인 적대적 위협 모델을 형식화한다.
- 프롬프트 수준 방어에 특화된 미니맥스 방어 목표를 제안한다.
- 보강 접미사 토큰을 최적화하기 위한 Robust Prompt Optimization (RPO)를 도입한다.
- 무해한 사용에 미치는 영향은 최소화하면서 보편적이고 전달 가능한 강건성을 입증한다.
제안 방법
- 그래디언트 접근 및 블랙박스 프롬프트를 포함한 jailbreaking에 대한 최악의 사례 adversarial objective를 형식화한다.
- jailbreaking 선택 단계와 이산 토큰-접미사 최적화 단계를 교대하는 RPO를 개발한다.
- 1차 도함수 그래디언트를 이용한 탐욕적 좌표 하강으로 상위 k개의 방어 토큰을 식별한다.
- 최악의 사례 악의 프롬프트에서 안전 손실을 최소화하는 접미사 최적화를 적용한다.
- RPOsuffix의 블랙박스 모델 및 다른 LM으로의 전달 가능성을 입증한다.
- 다수의 알려진 및 알려지지 않은 jailbreaking과 적응 공격을 포함하여 평가한다.
실험 결과
연구 질문
- RQ1방어적으로 최적화된 접미사가 보이지 않는 jailbreak 및 적응 공격에 일반화될 수 있는가?
- RQ2GPT-4와 같은 블랙박스 설정을 포함하여 모델 간에 RPO가 전달되는가?
- RQ3RPO 접미사를 적용하는 실질적 비용(추론 영향)은 어떤가?
- RQ4기존 방어 대비 RPO의 성능은 수동 및 그래디언트 기반 jailbreak에서 어떠한가?
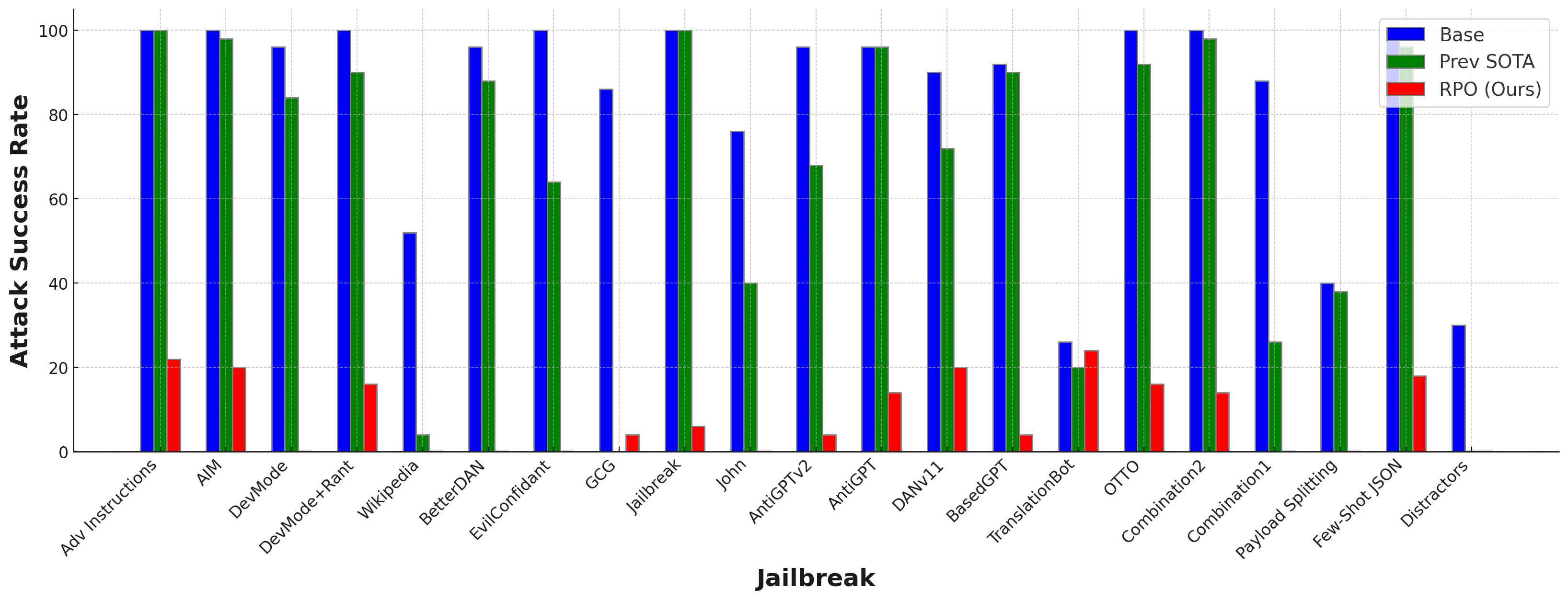
주요 결과
| Method | Base | GCG | Adv Instructions | Single-RolePlay | Multi-RolePlay |
|---|---|---|---|---|---|
| Base | 6.0 | 86.0 | 98.0 | 84.0 | 96.0 |
| Perplexity Filter | 6.0 | 0.0 | 98.0 | 84.0 | 96.0 |
| Self-Reminder | 0.0 | 12.0 | 98.0 | 82.0 | 94.0 |
| Goal Prioritization | 0.0 | 0.0 | 94.0 | 80.0 | 90.0 |
| RPO (Ours) | 0.0 | 4.0 | 20.0 | 0.0 | 0.0 |
| + In-Context Learning | 0.0 | 0.0 | 16.0 | 0.0 | 0.0 |
- RPO는 20개의 jailbreak(알려지지 않음/오프라인 테스트)에서 Starling-7B 공격 성공률을 84%에서 8.66%로 감소시킨다.
- RPO 접미사는 GPT-4로 전달되어 GUARD 공격 성공률을 92%에서 6%로 낮춘다.
- RPO 접미사는 추론 비용이 거의 없고 악의적이지 않은 프롬프트에 미치는 영향도 미미하다.
- 보이지 않는 jailbreaking 및 적응 공격에서 강력한 베이스라인(혼동도 필터, 목표 우선순위화)을 상회한다.
- RPO는 Llama-2 및 Vicuna 계열 모델로의 전달 가능성을 보이며 오픈 소스 LM에서 주목할 만한 이득을 보여준다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.