[논문 리뷰] Run, Don't Walk: Chasing Higher FLOPS for Faster Neural Networks
본 논문은 FLOPs를 줄인다고 해서 메모리 병목으로 인해 지연 시간이 반드시 감소하지 않는다고 주장하고, Partial Convolution (PConv)과 FasterNet을 도입한다. FasterNet은 GPU, CPU, ARM 디바이스에서 정확도를 희생하지 않으면서 더 높은 FLOPS와 더 빠른 추론 속도를 달성하는 빠른 CNN 계열이다.
To design fast neural networks, many works have been focusing on reducing the number of floating-point operations (FLOPs). We observe that such reduction in FLOPs, however, does not necessarily lead to a similar level of reduction in latency. This mainly stems from inefficiently low floating-point operations per second (FLOPS). To achieve faster networks, we revisit popular operators and demonstrate that such low FLOPS is mainly due to frequent memory access of the operators, especially the depthwise convolution. We hence propose a novel partial convolution (PConv) that extracts spatial features more efficiently, by cutting down redundant computation and memory access simultaneously. Building upon our PConv, we further propose FasterNet, a new family of neural networks, which attains substantially higher running speed than others on a wide range of devices, without compromising on accuracy for various vision tasks. For example, on ImageNet-1k, our tiny FasterNet-T0 is $2.8 imes$, $3.3 imes$, and $2.4 imes$ faster than MobileViT-XXS on GPU, CPU, and ARM processors, respectively, while being $2.9\%$ more accurate. Our large FasterNet-L achieves impressive $83.5\%$ top-1 accuracy, on par with the emerging Swin-B, while having $36\%$ higher inference throughput on GPU, as well as saving $37\%$ compute time on CPU. Code is available at \url{https://github.com/JierunChen/FasterNet}.
연구 동기 및 목표
- FLOPs와 실제 실세계 지연 간의 불일치를 기존의 빠른 네트워크에서 강조한다.
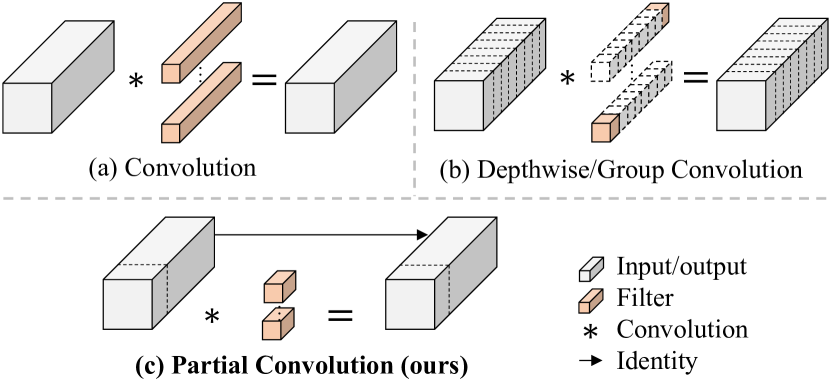
- 중복 계산과 메모리 접근을 줄이기 위해 Partial Convolution (PConv)을 도입한다.
- PConv를 기반으로 한 FasterNet 계열이 디바이스 간에 더 높은 처리량과 더 낮은 지연을 제공하도록 한다.
- ImageNet-1k 및 COCO 객체 탐지/분할과 같은 다운스트림 작업에서 FasterNet의 경쟁력 있는 정확도를 입증한다.
제안 방법
- 메모리 접근 병목에 초점을 맞추어 FLOPS/FPs 성능과 관련된 일반적인 CNN 연산자를 재평가한다.
- 입력 채널의 일부에만 일반 컨볼루션을 적용하고 다른 채널은 손대지 않는 방식으로 Partial Convolution (PConv)을 설계한다.
- PConv에 PWConv를 결합하여 공간 특징을 효율적으로 포획하는 T자형 수용 영역을 형성한다.
- 속도와 정확도를 위해 전략적 깊이/너비 분포를 갖춘 4단계 백본에 PConv 다음에 PWConvs를 배치한 FasterNet 블록을 구성한다.
- 배치 노름 융합과 선택적 활성화(GELU/ReLU)를 사용하여 디바이스 간 추론 지연을 최적화한다.
실험 결과
연구 질문
- RQ1더 높은 FLOPS(FLOPS)를 활용하여 일반 하드웨어에서 더 빠른 런타임(지연/처리량)을 달성할 수 있는가?
- RQ2Partial Convolution (PConv)이 메모리 접근과 중복 계산을 실제로 충분히 줄여 Depthwise/Group Convolution보다 성능을 앞당길 수 있는가?
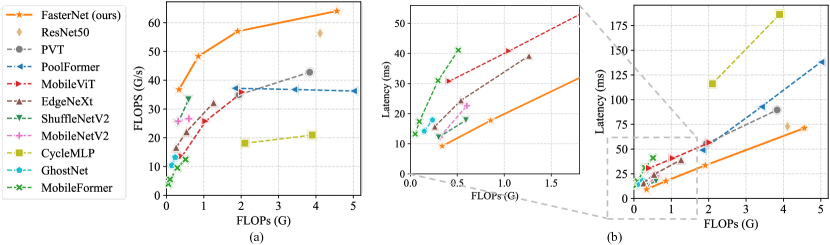
- RQ3PConv에 기반한 FasterNet 백본이 GPU, CPU, ARM 디바이스 전반에서 최첨단 속도-정확도 트레이드를 제공하는가?
- RQ4FasterNet 모델이 ImageNet 분류를 넘어 객체 탐지 및 인스턴스 분할과 같은 다운스트림 작업에 효과적인가?
주요 결과
- PConv는 입력 채널의 일부에만 컨볼루션을 적용함으로써 regular Conv에 비해 FLOPs를 줄이면서 DWConv/GConv보다 더 높은 FLOPS를 달성한다.
- PConv에 이어 PWConv를 적용하면 일반 Conv를 효과적으로 근사하며 메모리 접근이 더 적고 정확도도 경쟁력이 있다.
- Tiny FasterNet-T0는 ImageNet-1k에서 MobileViT-XXS 대비 GPU에서 2.8배, CPU에서 3.3배, ARM에서 2.4배 더 빠르며 정확도는 2.9% 포인트 높다.
- Large FasterNet-L은 ImageNet-1k에서 최고 83.5% 상위-1 정확도에 도달하고 Swin-B/ConvNeXt-B 기준으로 GPU 처리량 36%, CPU 계산 시간 37% 절감 효과를 보인다.
- FasterNet은 CNN, ViT, MLP 기반 모델과 비교하여 디바이스와 작업(분류, 탐지, 분할) 전반에서 우수한 정확도-처리량 및 정확도-지연 트레이드오프를 제공한다.
- COCO 객체 탐지/인스턴스 분할에서 FasterNet 백본은 비슷한 지연에서 더 높은 AP를 산출한다(예: FasterNet-S가 ResNet50 대비 상자 AP 및 마스크 AP를 개선).
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.