[논문 리뷰] S$^{3}$: Increasing GPU Utilization during Generative Inference for Higher Throughput
S3는 출력 시퀀스 길이를 예측하여 배치를 형성하고 생성 추론을 스케줄링함으로써 Transformer 기반 LLM의 GPU 활용도와 처리량을 향상시키고 잘못 예측을 처리한다.
Generating texts with a large language model (LLM) consumes massive amounts of memory. Apart from the already-large model parameters, the key/value (KV) cache that holds information about previous tokens in a sequence can grow to be even larger than the model itself. This problem is exacerbated in one of the current LLM serving frameworks which reserves the maximum sequence length of memory for the KV cache to guarantee generating a complete sequence as they do not know the output sequence length. This restricts us to use a smaller batch size leading to lower GPU utilization and above all, lower throughput. We argue that designing a system with a priori knowledge of the output sequence can mitigate this problem. To this end, we propose S$^{3}$, which predicts the output sequence length, schedules generation queries based on the prediction to increase device resource utilization and throughput, and handle mispredictions. Our proposed method achieves 6.49$ imes$ throughput over those systems that assume the worst case for the output sequence length.
연구 동기 및 목표
- KV 캐시 증가로 인한 자기회귀 LLM 추론에서의 메모리 바운드 GPU 활용 문제를 동기 부여한다.
- 지연 SLO 하에서 처리량을 높이기 위한 시퀀스 길이 예측 및 스케줄링 프레임워크(S3)를 제안한다.
- 모델 무결성을 해치지 않으면서 오판을 처리하고 신뢰성을 유지하는 메커니즘을 개발한다.
- 여러 모델 규모에 걸쳐 기본 시스템 대비 처리량 개선을 입증한다.
제안 방법
- Alpaca에서 예를 들어 98.61%에 이르는 정확도로 출력 시퀀스 길이를 10개 버킷으로 분류하도록 DistilBERT 기반 예측기를 미세조정한다.
- 단일 HBM 용량 제약과 ORCA에서 영감을 얻은 선택적 배치를 사용하여 길이 인식 스케줄러를 구현하고 요청을 배치한다(바이너 포장 스타일).
- 오판을 감지하고, 과길 KV 캐시를 선점 처리하며 데이터를 재배치하고 예측기를 온라인으로 재학습시키는 감독기를 사용한다.
- 메모리 제약을 준수하면서 처리량을 극대화하기 위해 FasterTransformer에 예측기, 스케줄러, 감독기를 통합한다.
- 더 높은 배치 크기를 가능하게 하고 처리량을 유지하기 위해 대형 모델의 GPU 간 파이프라인 분할을 수행한다.
![Figure 1 : Latency versus throughput trade-off among different models (left) and the number of GPUs (right, distributing GPT-3 to 6, 8, and 10 GPUs) when generating 60 tokens, inspired by FlexGen [ 6 ] . The markers in the lines represent batch sizes, from 1 to the maximum batch size that can be loa](https://ar5iv.labs.arxiv.org/html/2306.06000/assets/x1.png)
실험 결과
연구 질문
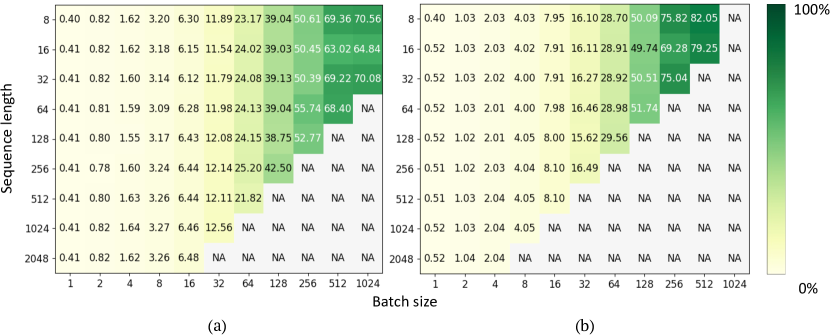
- RQ1출력 시퀀스 길이를 예측하는 것이 GPU HBM 용량을 초과하지 않으면서 달성 가능한 배치 크기를 증가시킬 수 있는가?
- RQ2온라인(SLO) 및 오프라인 시나리오에서 길이 인식 스케줄링이 처리량과 지연에 어떤 영향을 미치는가?
- RQ3오판 처리 및 메모리 단편화에 대한 감독기의 오버헤드와 강건성은 무엇인가?
주요 결과
- S3는 최악의 출력 길이를 가정한 시스템에 비해 최대 6.49×의 처리량 향상을 달성한다.
- 온라인 시나리오에서 지연 SLO가 토큰당 0.1875초인 경우 S3는 같은 SLO를 준수하면서 ORCA보다 최대 6.49× 더 많은 시퀀스를 생성한다.
- 정확한 출력 길이를 사전에 알지 못하더라도 S3는 모델 크기에 따라 Oracle(완벽 예측기)와 9.34%–40.52% 이내로 일치할 수 있다.
- 6개의 GPU를 사용한 S3는 10개의 GPU를 가진 일반 시스템과 거의 동일한 처리량을 보여 비용 효율성을 개선한다.
- 예측기는 버킷 예측에서 Alpaca에 대해 98.61%의 높은 정확도와 지연이 거의 없는 예측기 지연 3.7 ms를 달성한다.
- 오버헤드 및 오판 페널티는 작고(생성 시간의 평균 11%), 더 긴 생성에서 상쇄된다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.