[논문 리뷰] SAM-Med3D: Towards General-purpose Segmentation Models for Volumetric Medical Images
SAM-Med3D는 SAM을 완전히 학습 가능한 3D 아키텍처로 재구성하여 대규모 체적 의료 데이터셋에서 학습시키며, 훨씬 적은 프롬프트와 더 빠른 3D 의료 영상 분할 추론으로 경쟁력 있는 Dice 점수를 얻습니다.
Existing volumetric medical image segmentation models are typically task-specific, excelling at specific target but struggling to generalize across anatomical structures or modalities. This limitation restricts their broader clinical use. In this paper, we introduce SAM-Med3D for general-purpose segmentation on volumetric medical images. Given only a few 3D prompt points, SAM-Med3D can accurately segment diverse anatomical structures and lesions across various modalities. To achieve this, we gather and process a large-scale 3D medical image dataset, SA-Med3D-140K, from a blend of public sources and licensed private datasets. This dataset includes 22K 3D images and 143K corresponding 3D masks. Then SAM-Med3D, a promptable segmentation model characterized by the fully learnable 3D structure, is trained on this dataset using a two-stage procedure and exhibits impressive performance on both seen and unseen segmentation targets. We comprehensively evaluate SAM-Med3D on 16 datasets covering diverse medical scenarios, including different anatomical structures, modalities, targets, and zero-shot transferability to new/unseen tasks. The evaluation shows the efficiency and efficacy of SAM-Med3D, as well as its promising application to diverse downstream tasks as a pre-trained model. Our approach demonstrates that substantial medical resources can be utilized to develop a general-purpose medical AI for various potential applications. Our dataset, code, and models are available at https://github.com/uni-medical/SAM-Med3D.
연구 동기 및 목표
- 슬라이스 단위 방법을 넘어 3D 체적 의료 영상에 대한 일반 목적의 분할을 동기 부여하고 가능하게 한다.
- 슬라이스 간 공간 정보를 포착하기 위해 SAM의 완전한 3D 버전을 개발한다.
- 훈련 및 평가를 위한 대규모의 다양하고 체적화된 의료 데이터셋을 선별한다.
- 다수의 데이터셋, 모달리티 및 대상에 걸쳐 기존 SAM 변형들과 벤치마크한다.
제안 방법
- SAM을 3D 이미지 인코더, 3D 프롬프트 인코더, 3D 마스크 디코더를 갖춘 완전한 3D 아키텍처로 재설계한다.
- 체적 맥락을 모델링하기 위해 3D 합성곱과 3D 위치 인코딩을 사용한다.
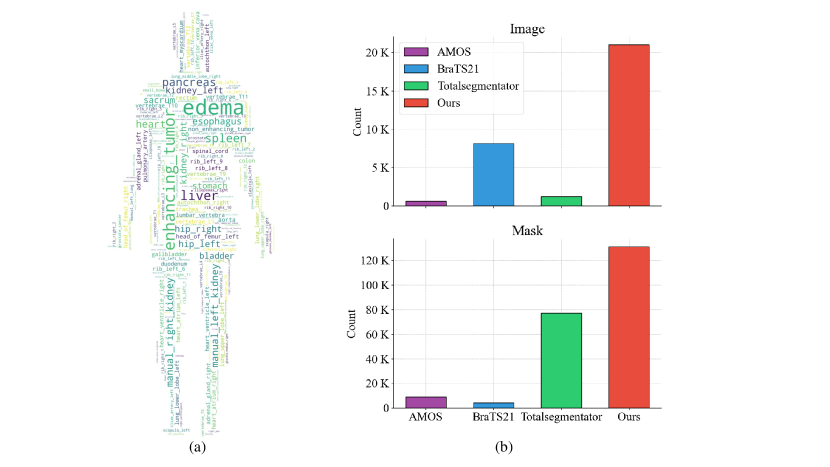
- 247 카테고리에 걸친 21K 이미지와 131K 마스크를 포함하는 대규모 데이터셋에서 처음부터 학습한다.
- 단일 3D 프롬프트 포인트가 전체 체적을 대상으로 삼을 수 있는 3D 프롬프트 체계로 평가한다.
- 15개의 공개 데이터세트와 MICCAI 2023 챌린지 데이터세트에서 SAM 및 SAM-Med2D와 비교한다.
![Figure 1 : Illustration of SAM [ 21 ] , fine-tuned SAM (SAM-Med2D [ 6 ] ), and our SAM-Med3D on 3D Volumetric Medical Images. Both SAM and SAM-Med2D take $N$ prompt points (one for each slice) whereas SAM-Med3D uses a single prompt point for the entire 3D volume. Here, $N$ corresponds to the number](https://ar5iv.labs.arxiv.org/html/2310.15161/assets/x1.png)
실험 결과
연구 질문
- RQ1완전 학습 가능한 3D 아키텍처가 슬라이스 단위 또는 2D 적응형 접근 방식과 비교하여 체적 의료 영상의 프롬프트 기반 분할을 개선할 수 있는가?
- RQ2대규모의 다양하고 체적화된 3D 의료 데이터셋이 해부학적 구조, 모달리티 및 보지 못한 대상에 대해 더 나은 일반화를 가능하게 하는가?
- RQ33D 분할 작업에서 2D SAM 변형에 비해 SAM-Med3D의 추론 시간 및 필요한 프롬프트 수는 얼마인가?
- RQ43D 인코더가 완전 감독형 3D 의료 분할 모델로 얼마나 잘 전이되는가?
- RQ5다중 모달리티(CT, MRI, US)와 대상 유형(장기, 뼈, 병변) 전반에서 SAM-Med3D의 성능은 어떠한가?
주요 결과
- SAM-Med3D는 21K개의 3D 이미지와 131K 마스크를 포함하고 247 카테고리에 걸친 완전 학습 가능한 3D 아키텍처를 사용한다.
- 프롬프트 포인트 1개로 평가 세트에서 Overall Dice 49.91을 달성하고, 각각 3, 5, 10 프롬프트에서는 56.38, 58.57, 60.94를 달성한다.
- SAM-Med3D는 추론 시간의 약 15% 수준으로 작동하면서 프롬프트 체계 전반에 걸쳐 우수한 Dice 점수를 제공한다.
- SAM-Med3D는 프롬프트가 증가할 때 CT 및 US 모달리티 및 보지 않은 대상에서도 경쟁력 있는 결과를 포함해 많은 해부 구조와 병변에서 SAM 및 SAM-Med2D를 지속적으로 능가한다.
- SAM-Med3D의 사전 학습된 ViT 인코더가 전이 작업에서 완전 감독형 UNETR 기반을 최대 5.63 Dice 포인트 향상시킨다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.