[논문 리뷰] SantaCoder: don't reach for the stars!
SantaCoder는 The Stack의 PII-redacted Java, JavaScript, and Python data로 학습된 1.1B-parameter decoder-only code 모델로, 이전의 오픈 소스 모델들보다 작음에도 불구하고 MultiPL-E에서 text-to-code 및 infilling 성능이 경쟁력 있음.
The BigCode project is an open-scientific collaboration working on the responsible development of large language models for code. This tech report describes the progress of the collaboration until December 2022, outlining the current state of the Personally Identifiable Information (PII) redaction pipeline, the experiments conducted to de-risk the model architecture, and the experiments investigating better preprocessing methods for the training data. We train 1.1B parameter models on the Java, JavaScript, and Python subsets of The Stack and evaluate them on the MultiPL-E text-to-code benchmark. We find that more aggressive filtering of near-duplicates can further boost performance and, surprisingly, that selecting files from repositories with 5+ GitHub stars deteriorates performance significantly. Our best model outperforms previous open-source multilingual code generation models (InCoder-6.7B and CodeGen-Multi-2.7B) in both left-to-right generation and infilling on the Java, JavaScript, and Python portions of MultiPL-E, despite being a substantially smaller model. All models are released under an OpenRAIL license at https://hf.co/bigcode.
연구 동기 및 목표
- Training data에서 PII를 제거하고 데이터 전처리 영향 평가를 통해 책임 있는 코드 LLM을 개발한다.
- FIM (Fill-in-the-Middle) 및 Multi Query Attention (MQA)에서의 어레이션을 통해 모델 아키텍처 리스크를 줄인다.
- 데이터 필터링 전략(stars filter, comments-to-code ratio, near-deduplication, tokenizer fertility)의 영향을 평가한다.
- 최종 1.1B 모델을 교육하고 기존의 오픈 소스 다국어 코드 모델과 비교한다.
- BigCode 노력 내에서 데이터셋과 전처리 도구에 공개 접근을 제공한다.
제안 방법
- The Stack 하위 집합(Java, JavaScript, Python)에 대해 FIM 및 MQA를 사용하는 1.1B decoder-only transformer를 학습한다.
- 프리-토큰화 데이터로 학습된 49k token Byte-Pair Encoding tokenizer를 사용한다.
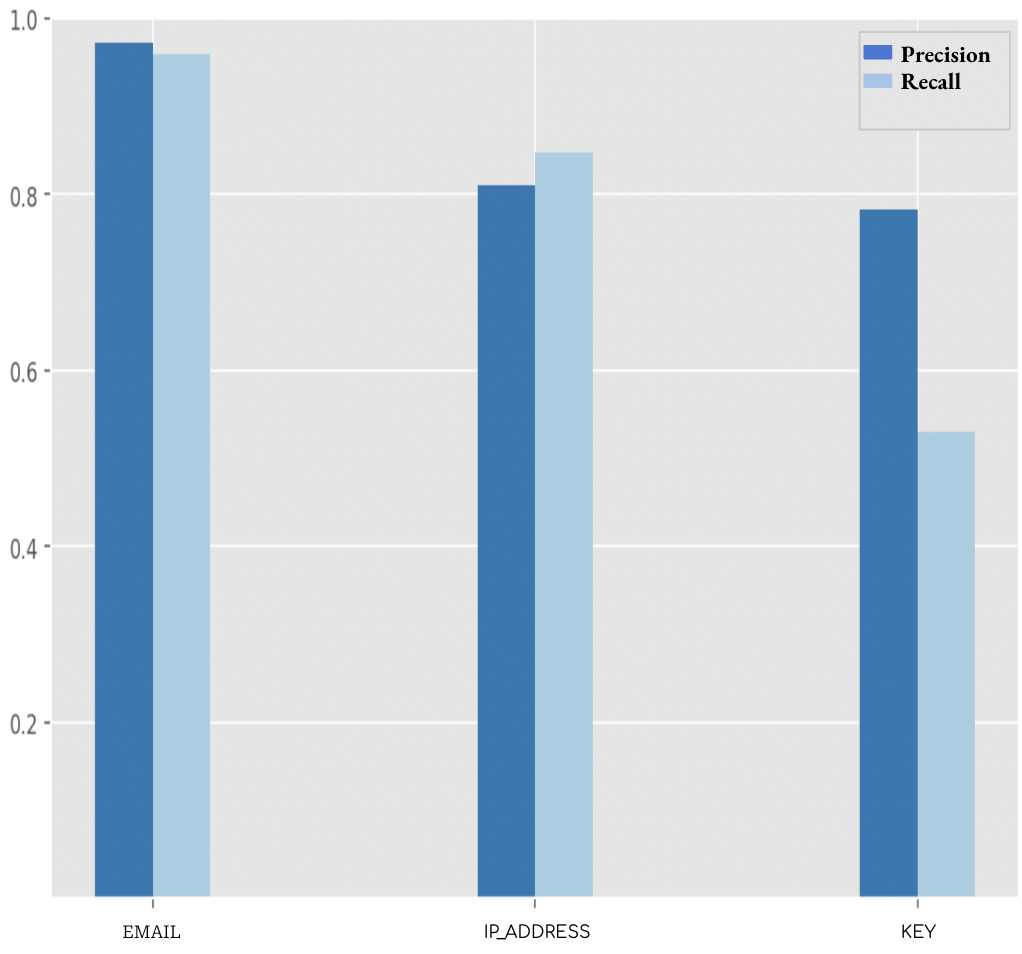
- 이메일, IP, 비밀 키를 탐지하는 벤치마크 및 파이프라인을 통해 PII redaction을 수행하고 필터링 및 gibberish/ hashing 검사로 처리한다.
- 아키텍처 어레이션(FIM 대 No-FIM; MQA 대 MHA) 및 데이터 필터링 어레이션(stars, comments-to-code, near-deduplication, fertility)을 수행한다.
- MultiPL-E 텍스트-투-코드 벤치마크 및 Java, JavaScript, Python 전반의 fill-in-the-middle 작업을 평가한다.
- SantaCoder를 InCoder, CodeGen, Codex baseline과 비교하고 OpenRAIL 하에 공개한다.
실험 결과
연구 질문
- RQ1PII redaction이 코드 LLM 학습에서 데이터 품질 및 모델 안전성에 어떤 영향을 미치는가?
- RQ2FIM 및 MQA와 같은 아키텍처 선택이 코드 생성 및 infilling 성능에 어떤 영향을 미치는가?
- RQ3데이터 필터링 전략이 텍스트-투-코드 벤치마크의 하류 성능에 어떤 영향을 미치는가?
- RQ4더 작은 1.1B 모델이 코드 생성 및 infilling 작업에서 더 큰 오픈 소스 다국어 코드 모델을 능가할 수 있는가?
- RQ5near-deduplication 및 stars 기반 필터링을 사용할 때 데이터 양과 질 사이의 트레이드오프는 무엇인가?
주요 결과
- PII redaction은 이메일 및 IP에 대해 높은 정밀도/재현율을 달성하고 벤치마크의 키에 대해서는 중간 수준의 정밀도를 나타낸다.
- FIM은 좌에서 우로의 텍스트-투-코드 성능에 작은 저하를 가져오지만 효율적 인 infilling을 가능하게 한다; MQA는 성능 변화가 약간 있으면서도 속도를 modest하게 향상시킨다.
- GitHub stars 필터링은 벤치마크와 언어 전반에서 일관되게 성능을 감소시킨다.
- Near-deduplication 및 comments-to-code 필터링은 텍스트-투-코드 벤치마크에서 소폭에서 중간 정도의 성능 향상을 가져오며, tokenizer fertility는 fill-in-the-middle 결과에 도움이 된다.
- SantaCoder (1.1B)는 MultiPL-E에서 Java, JavaScript, Python에 대해 left-to-right 생성 및 infilling에서 InCoder-6.7B 및 CodeGen-Multi-2.7B를 능가하며; 학습 반복을 두 배로 늘리면 텍스트-투-코드 성능이 더욱 향상된다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.