[논문 리뷰] SatCLIP: Global, General-Purpose Location Embeddings with Satellite Imagery
SatCLIP은 Sentinel-2 영상에 대한 대조 학습으로 전 세계 일반 목적 위치 인코더를 학습하여 위도/경도 임베딩을 생성하고 이는 다양한 지리공간 예측을 개선하며 보지 않은 지역에서도 일반화합니다.
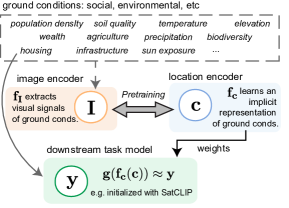
Geographic information is essential for modeling tasks in fields ranging from ecology to epidemiology. However, extracting relevant location characteristics for a given task can be challenging, often requiring expensive data fusion or distillation from massive global imagery datasets. To address this challenge, we introduce Satellite Contrastive Location-Image Pretraining (SatCLIP). This global, general-purpose geographic location encoder learns an implicit representation of locations by matching CNN and ViT inferred visual patterns of openly available satellite imagery with their geographic coordinates. The resulting SatCLIP location encoder efficiently summarizes the characteristics of any given location for convenient use in downstream tasks. In our experiments, we use SatCLIP embeddings to improve prediction performance on nine diverse location-dependent tasks including temperature prediction, animal recognition, and population density estimation. Across tasks, SatCLIP consistently outperforms alternative location encoders and improves geographic generalization by encoding visual similarities of spatially distant environments. These results demonstrate the potential of vision-location models to learn meaningful representations of our planet from the vast, varied, and largely untapped modalities of geospatial data.
연구 동기 및 목표
- 세계적으로 일반 목적 위치 인코더가 필요하다는 점의 동기 부여(학습 지역을 넘어 일반화).
- 좌표를 위성 영상에 매핑하기 위한 CLIP 스타일의 사전학습 목표를 제안.
- Sentinel-2 데이터로부터 전 세계적으로 균일한 사전학습 데이터셋(S2-100K)을 생성.
- 다양한 다운스트림 지리공간 작업에서 임베딩을 시연.
- 커뮤니티 사용을 위해 사전학습된 SatCLIP 모델 및 데이터셋 공개.
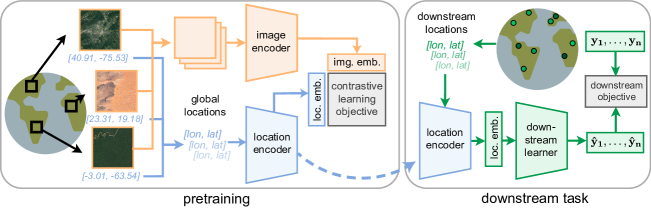
제안 방법
- 위치 인코더 f_c를 정의하여 (lat, lon)을 d 차원 벡터로 매핑.
- 이미지 인코더 f_I를 정의하여 위성 이미지 타일을 d 차원 벡터로 매핑.
- 좌표와 대응 이미지 임베딩을 정렬시키는 CLIP 유사 목표로 사전학습(Eq. 1–3).
- 전역 좌표 인코딩을 위해 Siren(SH) 구면 조화 및 사인 파 네트워크를 사용.
- ResNet 또는 ViT 이미지 백본 사용; 학습 중 최종 투영을 제외하고 고정.
- S2-100K에서 배치 크기 8k, 500 에폭으로 A100 GPU에서 학습.
실험 결과
연구 질문
- RQ1RQ1: SatCLIP 임베딩은 다양한 다운스트림 지리공간 작업에서 얼마나 일반화되는가?
- RQ2RQ2: SatCLIP 임베딩이 보지 못한 대륙에서 제로샷 또는 소수 샷으로 지리적으로 일반화되는가?
- RQ3RQ3: SatCLIP 임베딩이 환경 및 사회경제적 기초 조건의 의미 있는 공간적 경향을 포착하는가?
주요 결과
| 작업 | 데이터 | SatCLIP-RN50 | SatCLIP-ViT16 | CSP (FMoW) | CSP (iNat) | GPS2Vec (tag) | GPS2Vec (visual) | MOSAIKS (Planet) |
|---|---|---|---|---|---|---|---|---|
| Air temperature | (S2-100K) | 0.27±0.03 | 0.25±0.02 | 2.81±1.11 | 4.71±1.78 | 2.37±0.00 | 2.92±0.01 | 4.61±6.05 |
| Median income | (S2-100K) | 0.71±0.16 | 0.67±0.01 | 1.39±0.07 | 1.35±0.03 | 1.06±0.00 | 1.31±0.00 | 1.31±0.07 |
| Cali. housing | (FMoW) | 2.42±0.12 | 2.62±0.28 | 5.67±0.00 | 5.68±0.01 | 1.64±0.15 | 2.20±0.14 | 4.30±0.11 |
| Elevation | (S2-100K) | 0.15±0.00 | 0.15±0.01 | 0.80±0.05 | 1.11±0.06 | 1.11±0.01 | 1.17±0.00 | 0.98±0.01 |
| Population | (S2-100K) | 0.48±0.01 | 0.50±0.02 | 1.69±0.16 | 1.72±0.28 | 1.99±0.00 | 2.28±0.00 | 1.45±0.05 |
| Countries | (Planet) | 96.00±0.14 | 95.77±0.14 | 77.78±1.66 | 82.11±1.72 | 70.35±0.06 | 67.80±0.03 | 76.16±0.50 |
| iNaturalist | (tag) | 66.03±0.54 | 65.98±0.61 | 56.73±0.83 | 60.47±0.56 | 58.78±0.48 | 53.27±0.78 | 56.73±0.80 |
| Biome | (Planet) | 94.41±0.14 | 94.27±0.15 | 75.81±1.53 | 73.18±5.58 | 69.69±0.06 | 68.29±0.11 | 79.61±0.42 |
| Ecoregions | (Planet) | 91.67±0.15 | 91.61±0.22 | 76.87±1.27 | 78.43±1.71 | 68.46±0.06 | 67.26±0.02 | 70.48±0.21 |
- SatCLIP은 여덟 개의 다운스트림 태스크에서 베이스라인 대비 최상의 예측을 달성.
- SatCLIP은 대륙 간 강한 지리적 일반화를 보이며 대부분의 지역에서 이전 인코더보다 우수.
- 보지 않은 대륙에 대한 제로샷 또는 소수 샷 적응은 SatCLIP 임베딩에서 종종 우수.
- 임베딩은 학습 잠재공간에서 명확한 생태군(Biome) 클러스터링으로 환경 구조를 인식 가능하게 함.
- Biomes는 SatCLIP 임베딩에서 분리 가능하여 좌표를 넘어선 ground conditions를 포착함.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.