[논문 리뷰] SaulLM-7B: A pioneering Large Language Model for Law
SaulLM-7B는 Mistral-7B를 기반으로 구축된 7B 규모의 법률 도메인 LLM이며, 30B 개의 법률 토큰으로 학습되었고, 지시문 튜닝된 변형 SaulLM-7B-Instruct가 있으며, MIT 라이선스 하에 공개된다.
In this paper, we introduce SaulLM-7B, a large language model (LLM) tailored for the legal domain. With 7 billion parameters, SaulLM-7B is the first LLM designed explicitly for legal text comprehension and generation. Leveraging the Mistral 7B architecture as its foundation, SaulLM-7B is trained on an English legal corpus of over 30 billion tokens. SaulLM-7B exhibits state-of-the-art proficiency in understanding and processing legal documents. Additionally, we present a novel instructional fine-tuning method that leverages legal datasets to further enhance SaulLM-7B's performance in legal tasks. SaulLM-7B is released under the MIT License.
연구 동기 및 목표
- 법률 텍스트 이해 및 생성을 위한 공개적이고 오픈 소스 LLM 개발.
- 영문 법률 말뭉치를 크게 다양하게 사전 학습하여 법률 용어의 뉘앙스를 포착.
- 법률 특화 지시를 포함한 지시 미세 조정을 통해 성능을 향상.
- 법률 도메인에서의 연구 및 채택을 촉진하기 위한 개방 라이선스 및 평가 도구를 제공.
제안 방법
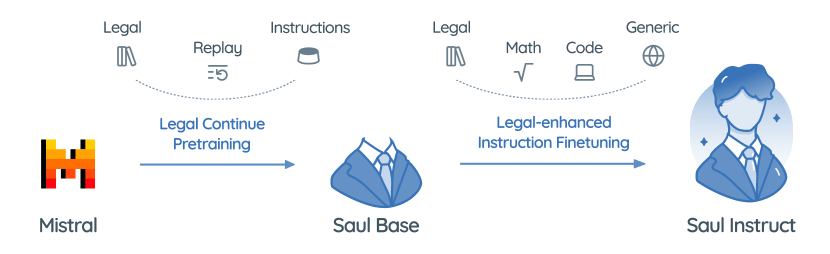
- 기반 모델: SaulLM-7B의 기초로 Mistral-7B를 사용.
- 다양한 관할권의 선별된 30B 토큰 영어 법률 말뭉치로의 지속적인 사전 학습.
- 사전 학습용 고품질 법률 텍스트를 만들기 위한 데이터 정리 및 중복 제거.
- 일반 지시 데이터와 법률 지시 데이터를 혼합한 지시 미세 조정을 통해 SaulLM-7B-Instruct를 생성.
- 작업 집중 능력을 향상시키기 위한 법률 지시 대화의 합성 구성.
- LegalBench-Instruct 및 Legal-MMLU를 포함한 평가 프로토콜, 법률 문서 유형에 대한 프렙서티 분석과 함께.
실험 결과
연구 질문
- RQ1큰 규모의 법률 말뭉치에 대한 지속적인 사전 학습이 일반 모델 대비 법률 작업 성능을 향상시키는가?
- RQ2법률 지시 미세 조정(SaulLM-7B-Instruct)을 추가하면 법률 벤치마크에서 최첨단 결과를 얻을 수 있는가?
- RQ3LegalBench-Instruct 및 Legal-MMLU 작업에서 open-source 7B/13B 모델과 SaulLM-7B-Instruct의 비교는 어떠한가?
- RQ4기반 모델 선택과 지시 데이터 구성의 변화가 법적 추론 및 추론 작업에 어떤 영향을 미치는가?
주요 결과
- SaulLM-7B는 독립형 모델로서 강한 성능을 발휘하여 법률 벤치마크에서 일부 7B 기준선에 근접하거나 일치한다.
- SaulLM-7B-Instruct가 LegalBench-Instruct에서 평균 점수 0.61로 새로운 최첨단을 확립했으며, 최상의 오픈 소스 지시 모델(Mistral-7B-Instruct-v0.1) 대비 상대 개선 11%를 보인다.
- LegalBench-Instruct 결과는 SaulLM-7B-Instruct가 핵심 법률 능력(이슈 탐지, 규칙 회상, 해석, 이해)에서 비법률 지시 미세 조정 모델을 능가함을 보여준다.
- Legal-MMLU에서 SaulLM-7B-Instruct는 세 가지 과제에서 비법률 지시 미세 조정 모델보다 우수한 성능을 보이며, 최상의 7B 오픈 소스 경쟁자보다 3–4점 차로 앞선다.
- 프렙서티 분석: SaulLM-7B-Instruct의 중앙값 프렙서티는 8.69로, Mistral-7B 대비 5.5% 감소, Llama2-7B 대비 9.20% 감소(Median 9.74).
- 계속된 법률 사전 학습과 법률 지시 튜닝의 결합은 상당한 이점을 제공하는 반면, 이 법적 맥락에서 DPO 정렬 모델은 지시 튜닝된 동료들에 비해 성능이 떨어진다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.