[논문 리뷰] Scalable Pre-training of Large Autoregressive Image Models
본 논문은 autoregressive 목표로 사전 학습된 비전 트랜스포머 계열인 Aim을 소개하고, 모델 크기와 데이터의 증가에 따라 이미지 표현 품질이 확장 가능하게 향상됨을 시연하며, 목표 값이 다운스트리밍 성능과 연결됨을 보인다.
This paper introduces AIM, a collection of vision models pre-trained with an autoregressive objective. These models are inspired by their textual counterparts, i.e., Large Language Models (LLMs), and exhibit similar scaling properties. Specifically, we highlight two key findings: (1) the performance of the visual features scale with both the model capacity and the quantity of data, (2) the value of the objective function correlates with the performance of the model on downstream tasks. We illustrate the practical implication of these findings by pre-training a 7 billion parameter AIM on 2 billion images, that achieves 84.0% on ImageNet-1k with a frozen trunk. Interestingly, even at this scale, we observe no sign of saturation in performance, suggesting that AIM potentially represents a new frontier for training large-scale vision models. The pre-training of AIM is similar to the pre-training of LLMs, and does not require any image-specific strategy to stabilize the training at scale.
연구 동기 및 목표
- 비전 모델의 autoregressive 사전 학습을 대형 언어 모델(LLMs)에 비견되도록 확장하는 것을 동기로 삼는다.
- 모델 용량과 데이터 양의 증가가 사전 학습 손실과 다운스트리밍 정확도를 개선함을 입증한다.
- autoregressive 목표가 다운스트리밍 특징 품질과 상관관계가 있음을 보여주고, 확장 가능한 비전 모델을 가능하게 한다.
제안 방법
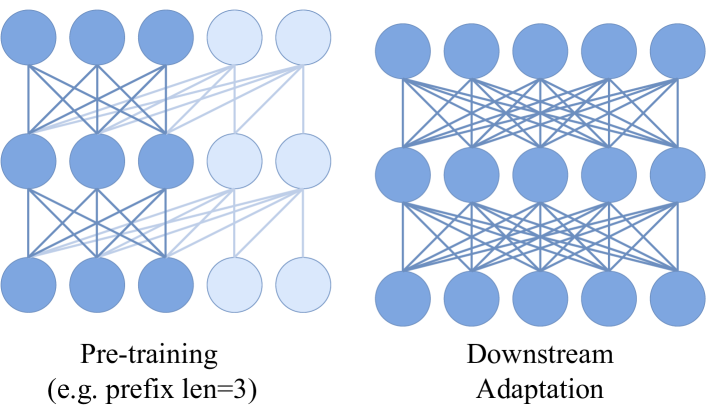
- Autoregressive 사전 학습을 유지하면서 양방향 다운스트림 사용을 가능하게 하는 prefix attention을 사용하는 ViT 백본을 사용한다.
- 특징 품질 향상을 위해 매개변수화가 큰 패치 수준 MLP 헤드를 사용한다.
- 정규화된 패치에 대한 픽셀 수준 MSE 손실을 사용하여 으뜸 데이터와 다양한 데이터의 혼합으로 DFN-2B+ (2B 이미지)에서 사전 학습한다.
- 초기 패치가 컨텍스트를 형성하고 후속 패치가 autoregressively 예측되는 prefix LM 학습 방식를 채택한다.
- 15 벤치마크에서 얼어붙은 트렁크를 대상으로 주의적(probing) 특징 평가를 수행한다.

실험 결과
연구 질문
- RQ1자동 회귀 목표가 LLM에서처럼 시각 표현에 대해 효과적으로 확장되는가?
- RQ2Aim의 모델 크기와 데이터 양이 사전 학습 손실 및 다운스트리밍 특징 품질에 어떤 영향을 미치는가?
- RQ3비전 모델의 다운스트리밍 전달을 최적화하는 아키텍처 선택(Prefix attention, MLP 헤드)은 무엇인가?
- RQ4시각 자동회귀 모델의 대규모 사전 학습에서 성능의 포화가 존재하는가?
주요 결과
- Aim은 모델 크기를 600M에서 7B 매개변수로 증가시킴에 따라 성능이 확장된다.
- 검증 사전 학습 손실과 다운스트리밍 특징 품질 사이에 상관관계가 있다.
- 2B+ 이미지에서 사전 학습하면 강력한 다운스트리밍 성능을 얻으며, 명확한 포화는 관찰되지 않았다.
- DFN-2B+와 IN-1k의 데이터 혼합이 테스트 데이터셋 중 최상의 다운스트리밍 결과를 제공한다.
- 동일한 설정에서 autoregressive 목표가 마스킹 목표보다 우수하다.
- 얼어붙은 트렁크에서의 주의적(probing) 평가에서 Aim-7B가 15개 벤치마크에서 강력한 결과를 보인다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.