[논문 리뷰] Scale-Aware Modulation Meet Transformer
Scale-Aware Modulation Transformer(SMT)를 도입하여 컨볼루션 모듈레이션과 비전 트랜스포머를 Scale-Aware Modulation(SAM), MHMC, SAA를 통해 하이브리드화하고, 지역-에서 글로벌 의존성을 포착하기 위한 Evolutionary Hybrid Network를 제시한다.
This paper presents a new vision Transformer, Scale-Aware Modulation Transformer (SMT), that can handle various downstream tasks efficiently by combining the convolutional network and vision Transformer. The proposed Scale-Aware Modulation (SAM) in the SMT includes two primary novel designs. Firstly, we introduce the Multi-Head Mixed Convolution (MHMC) module, which can capture multi-scale features and expand the receptive field. Secondly, we propose the Scale-Aware Aggregation (SAA) module, which is lightweight but effective, enabling information fusion across different heads. By leveraging these two modules, convolutional modulation is further enhanced. Furthermore, in contrast to prior works that utilized modulations throughout all stages to build an attention-free network, we propose an Evolutionary Hybrid Network (EHN), which can effectively simulate the shift from capturing local to global dependencies as the network becomes deeper, resulting in superior performance. Extensive experiments demonstrate that SMT significantly outperforms existing state-of-the-art models across a wide range of visual tasks. Specifically, SMT with 11.5M / 2.4GFLOPs and 32M / 7.7GFLOPs can achieve 82.2% and 84.3% top-1 accuracy on ImageNet-1K, respectively. After pretrained on ImageNet-22K in 224^2 resolution, it attains 87.1% and 88.1% top-1 accuracy when finetuned with resolution 224^2 and 384^2, respectively. For object detection with Mask R-CNN, the SMT base trained with 1x and 3x schedule outperforms the Swin Transformer counterpart by 4.2 and 1.3 mAP on COCO, respectively. For semantic segmentation with UPerNet, the SMT base test at single- and multi-scale surpasses Swin by 2.0 and 1.1 mIoU respectively on the ADE20K.
연구 동기 및 목표
- 로컬 특성 모델링과 글로벌 컨텍스트의 균형을 맞추는 하이브리드 CNN-트랜스포머 설계를 제시한다.
- Scale-Aware Modulation(SAM)을 Multi-Head Mixed Convolution(MHMC)와 Scale-Aware Aggregation(SAA)와 함께 개발한다.
- 깊이가 증가함에 따라 로컬에서 글로벌 의존성 포착으로의 전이를 시뮬레이션하기 위해 Evolutionary Hybrid Network(EHN)를 제안한다.
- 효율적인 파라미터와 계산 예산으로 ImageNet, COCO, ADE20K에서 SMT의 우수성을 시연한다.
제안 방법
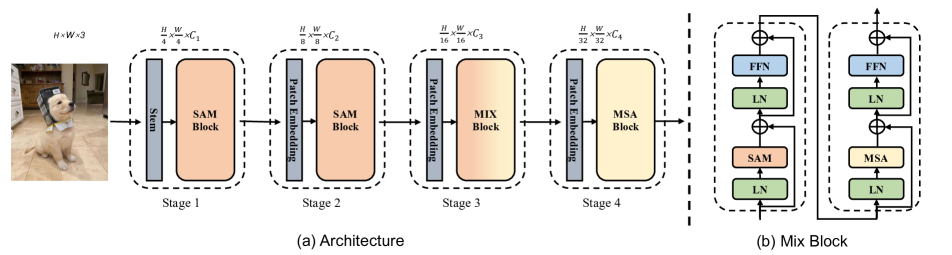
- 초기 단계에서 전통적인 어텐션을 대체하거나 보강하기 위해 Scale-Aware Modulation(SAM)을 제안한다.
- 채널별 헤드를 통해 다중 스케일 특성을 포착하기 위해 Multi-Head Mixed Convolution(MHMC)을 구현한다.
- 경량의 크로스-헤드 상호작용으로 다중 스케일 특성을 융합하기 위해 Scale-Aware Aggregation(SAA)을 도입한다.
- SAM을 상위 단계에, MSA를 더 깊은 단계에 배치하고 두 가지 하이브드 스태킹 전략으로 Evolutionary Hybrid Network(EHN)을 채택한다.
- 로컬에서 글로벌로의 전이를 모델링하기 위해 SAM 및 MSA 블록을 결합한 Mix Block 설계를 사용한다.
- MHMC 헤드, 어그리게이션 및 스태킹에 대한 탈아블레이션과 함께 ImageNet-1K/22K, COCO, ADE20K에서 SMT를 평가한다.
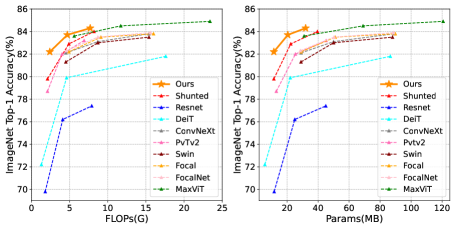
실험 결과
연구 질문
- RQ1Scale-Aware Modulation(SAM)이 MHMC 및 SAA와 함께 분류, 탐지, 세분화 작업에서 순수 어텐션이나 순수 컨볼루션 블록을 능가할 수 있는가?
- RQ2SAM이 지배하는 초기 단계에서 MSA가 지배하는 후기 단계로 전이하는 Evolutionary Hybrid Network(EHN)가 더 나은 효율-정확도 균형을 제공하는가?
- RQ3MHMC 헤드 수와 어그리게이션 전략이 성능과 처리량에 어떤 영향을 미치는가?
- RQ4SMT에서 로컬에서 글로벌 의존성 전이를 가장 잘 모델링하는 스태킹 전략은 무엇인가?
주요 결과
| Backbone | 매개변수 수 | FLOPs | ImageNet top-1 |
|---|---|---|---|
| SMT-T(Ours) | 11.5 | 2.4 | 82.2 |
| SMT-B(Ours) | 32.0 | 7.7 | 84.3 |
- SMT는 SMT-T로 ImageNet-1K에서 82.2% 톱-1, SMT-B로 84.3%를 달성하여 유사한 파라미터 수와 FLOPs에서 여러 최첨단 기준선을 앞질렀다.
- ImageNet-22K에서 사전학습하고 224^2 및 384^2에서 미세조정하면 각각 87.1%와 88.1%의 top-1을 얻는다.
- Mask R-CNN과 함께 COCO에서 SMT 베이스는 1x 일정에서 Swin보다 AP 4.2, 3x 일정에서 AP 1.3을 상회한다.
- ADE20K에서 UPerNet으로 SMT 베이스는 Swin보다 단일 스케일에서 mIoU를 2.0, 다중 스케일에서 1.1 향상시킨다.
- 탈아블레이션은 4 MHMC 헤드가 최대 이미지넷 정확도를 낳고 Scale-Aware Aggregation(SAA)가 기준선 대비 1.6% 이점을 제공함을 보여준다.
- 두 가지 하이브리드 스태킹 전략을 평가했으며, SAM과 MSA 블록이 순차적으로 배치되고 마지막 단계에 MSA를 남겨둔 전략이 최적의 성능을 보였다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.