[논문 리뷰] Scaling Law in Neural Data: Non-Invasive Speech Decoding with 175 Hours of EEG Data
EEG에서 175시간의 데이터로 개방 어휘 음성 decoding을 시연하여 48%의 top-1 및 76%의 top-10 정확도를 달성하고, 대략 10시간과 비교하여 데이터 길이 확장 효과가 강하게 나타남을 보여준다.
Brain-computer interfaces (BCIs) hold great potential for aiding individuals with speech impairments. Utilizing electroencephalography (EEG) to decode speech is particularly promising due to its non-invasive nature. However, recordings are typically short, and the high variability in EEG data has led researchers to focus on classification tasks with a few dozen classes. To assess its practical applicability for speech neuroprostheses, we investigate the relationship between the size of EEG data and decoding accuracy in the open vocabulary setting. We collected extensive EEG data from a single participant (175 hours) and conducted zero-shot speech segment classification using self-supervised representation learning. The model trained on the entire dataset achieved a top-1 accuracy of 48\% and a top-10 accuracy of 76\%, while mitigating the effects of myopotential artifacts. Conversely, when the data was limited to the typical amount used in practice ($\sim$10 hours), the top-1 accuracy dropped to 2.5\%, revealing a significant scaling effect. Additionally, as the amount of training data increased, the EEG latent representation progressively exhibited clearer temporal structures of spoken phrases. This indicates that the decoder can recognize speech segments in a data-driven manner without explicit measurements of word recognition. This research marks a significant step towards the practical realization of EEG-based speech BCIs.
연구 동기 및 목표
- 비침습적 EEG 기반 음성 전달을 실제 개방 어휘 BCI로 확장하기 위해 데이터 크기에 따른 디코딩 정확도 스케일링을 평가한다.
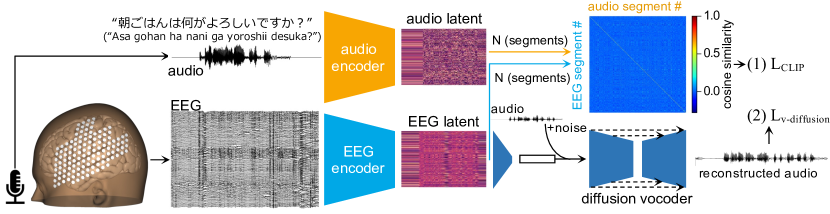
- EEG와 음성 표현을 정렬하기 위한 자기지도 CLIP 기반 프레임워크를 개발하여 제로샷 구문 분류 및 재구성을 가능하게 한다.
- EMG/근전근 영향에 대한 견고성을 평가하고 명시적 감독 없이도 음성 시작 탐지를 탐구한다.
제안 방법
- 48일에 걸친 175시간의 EEG 및 음성을 한 참가자로부터의 명시적 읽기 동안 기록한다.
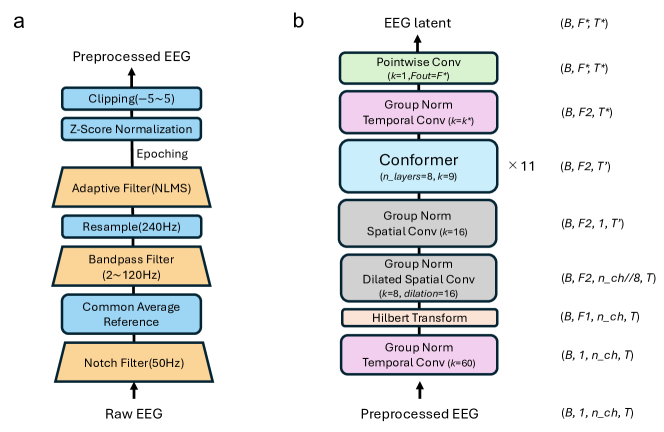
- EMG 아티팩트 완화 및 데이터를 5초 창으로 분할하는 EEG 전처리 수행한다.
- 고정 오디오 인코더(wav2vec2.0, Whisper encoder, 또는 Encodec)와 EEG 인코더(HTNet + Conformer)를 사용해 잠재 표현을 생성한다.
- 레이블 없이 EEG 및 오디오 잠재 간 코사인 유사도를 최대화하기 위해 CLIP 손실로 EEG 인코더를 학습한다.
- EEG 잠재에서 음성을 재구성하기 위해 확산 보코더를 학습하고 멜-케프스트랄 왜곡(MCD)로 평가한다.
실험 결과
연구 질문
- RQ1개방 어휘 음성 디코딩이 대규모 데이터 수집으로 비침습적으로 달성될 수 있는가?
- RQ2EEG 기반 음성 디코딩에서 학습 데이터의 양에 따라 디코딩 정확도는 어떻게 스케일링되는가?
- RQ3명시적 비신경 신호 없이 EEG 잠재 역학으로 음성 시작/구간 탐지가 가능한가?
- RQ4EMG 아티팩트가 EEG 기반 디코딩에 어느 정도 영향을 미치는가, 그리고 모델은 이를 무시하도록 학습시킬 수 있는가?
주요 결과
- 전체 175시간에서 512-구문 개방 어휘 작업의 Top-1 정확도 48% 및 Top-10 정확도 76%를 달성.
- wav2vec2.0 음성 임베딩을 사용한 제로샷 분류에서 48.5% Top-1 및 76.0% Top-10 정확도 달성.
- 학습 데이터가 늘어날수록 분류 정확도가 향상되며, 증가하는 데이터 하에서 포화가 아닌 스케일링 경향을 보임.
- 음성 재구성은 평균 MCD 4.68 dB로 나타나 셔플된 라벨 기반 기준보다 현저히 우수하며 침습 시스템 벤치마크의 범위에 속한다.
- 더 많은 데이터에서 EEG 잠재 표현이 더 명확한 시간적 구조를 보이며 명시적 단어 수준 라벨 없이도 데이터 기반의 음성 구간(음성 시작) 탐지가 가능해진다.
- EMG 아티팩트는 EMG-혼합 데이터로 EMG 신호를 무시하도록 모델을 학습시키면 영향이 제한적이며, EEG 기반 디코딩은 신경 활동에 크게 의존한다는 것을 시사한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.