[논문 리뷰] SceneScape: Text-Driven Consistent Scene Generation
SceneScape는 사전 학습된 텍스트-이미지 확산 모델과 단안 깊이 사전지 및 온라인 테스트-타임 최적화를 결합하여 텍스트 프롬프트와 카메라 궤적으로부터 장기적이고 3D 일관된 비디오를 생성하고, 통합된 3D 장면 메쉬를 구축합니다. 도메인 특화 학습 없이 제로샷으로 작동하며 기하학적 일관성을 보장하기 위해 메쉬를 점진적으로 업데이트합니다.
We present a method for text-driven perpetual view generation -- synthesizing long-term videos of various scenes solely, given an input text prompt describing the scene and camera poses. We introduce a novel framework that generates such videos in an online fashion by combining the generative power of a pre-trained text-to-image model with the geometric priors learned by a pre-trained monocular depth prediction model. To tackle the pivotal challenge of achieving 3D consistency, i.e., synthesizing videos that depict geometrically-plausible scenes, we deploy an online test-time training to encourage the predicted depth map of the current frame to be geometrically consistent with the synthesized scene. The depth maps are used to construct a unified mesh representation of the scene, which is progressively constructed along the video generation process. In contrast to previous works, which are applicable only to limited domains, our method generates diverse scenes, such as walkthroughs in spaceships, caves, or ice castles.
연구 동기 및 목표
- 자유로운 형태의 텍스트 프롬프트와 주어진 카메라 궤적으로부터 다양한 장면의 긴 영상을 생성할 수 있는 텍스트 기반의 지속적 뷰 생성의 가능성을 제시한다.
- 사전 학습된 이미지 확산 및 깊이 모델을 제로샷 프레임워크에서 활용해 대규모 도메인 특화 학습의 필요성을 제거한다.
- 비디오 합성 중 장면의 통합된 3D 메쉬를 구축하고 다듬어 3D 일관된 생성을 실현한다.
- 프레임 간 시점 차이(parallax), 가림, 콘텐츠 연속성을 처리하는 확장 가능한 프레임워크를 제공한다.
제안 방법
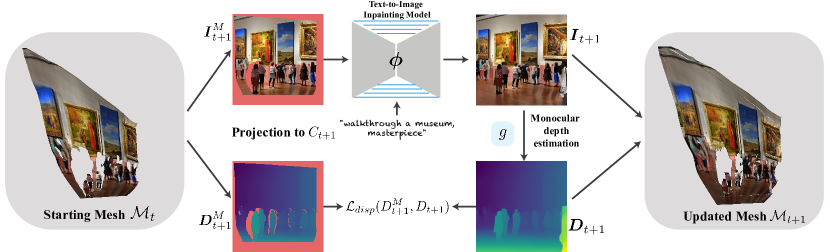
- 카메라가 움직일 때 새로 드러나는 내용을 합성하기 위해 사전 학습된 텍스트-투-이미지 확산 모델을 사용한다.
- 단안 깊이 예측기로 기하를 추정하고 테스트-타임 미세조정(L_disp)을 통해 깊이 일관성을 강제한다.
- 장면을 표현하는 통합 삼각 메쉬 M을 점진적으로 업데이트하고 새로운 콘텐츠로 확장한다(unproj 및 merge).
- 이미 알려진 콘텐츠와 이전 콘텐츠를 보존하기 위해 인페인팅 모델의 테스트-타임 디코더 미세조정을 수행한다(L_dec).
- 메쉬를 다음 시점으로 투영하고 경계/가려진 영역을 인페인팅해 인공물 없이 프레임을 렌더링한다.
- 렌더링 중 늘어난 삼각형을 제거하고 경계 영역을 인페인팅해 기하학적 인공물을 처리한다.

실험 결과
연구 질문
- RQ1텍스트 프롬프트와 카메라 궤적만으로 장기적이고 다양한 3D 일관성의 워크스루 비디오를, 작업 특화 학습 없이 생성할 수 있는가?
- RQ2단안 깊이 사전과 통합 메쉬 표현을 활용해 제로샷 설정에서 프레임 간 기하 일관성을 어떻게 보장할 수 있는가?
- RQ3깊이 미세조정과 디코더 미세조정이 3D 일관성과 시각적 품질에 미치는 영향은 무엇인가?
- RQ43D 일관성, 시각적 품질, 프롬프트 준수 측면에서 SceneScape의 성능은 기준선 대비 어떠한가?
주요 결과
- SceneScape은 다양한 실내 장면에서 고품질의 기하학적으로 타당한 워크스루 비디오를 생성한다.
- 변인실험은 깊이 미세조정과 디코더 미세조정이 깊이 일관성과 시간적 응집성을 크게 향상시킴을 보여준다.
- 메쉬를 2D 워핑으로 대체하면 3D 재구성과 지표가 저하되어 통합 메쉬의 중요성을 강조한다.
- 기준선과 비교하여 SceneScape는 3D-일관성 지표와 AMT 연구에서 사용자 주관적 시각 품질 면에서 앞선다.
- CLIP 기반 프롬프트 준수는 강력한 3D 일관성을 달성하면서도 경쟁력 있는 수준으로 유지된다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.