[논문 리뷰] SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
SDXL은 더 큰 UNet, 새로운 conditioning 체계, 다중 종횡비 학습, 그리고 정제 단계가 포함된 텍스트-이미지 생성용 잠재 확산 모델을 크게 향상시켰으며, 이전 Stable Diffusion 버전보다 인간의 선호도가 현저히 높고 SOTA 경쟁력을 갖춘 성능을 달성합니다.
We present SDXL, a latent diffusion model for text-to-image synthesis. Compared to previous versions of Stable Diffusion, SDXL leverages a three times larger UNet backbone: The increase of model parameters is mainly due to more attention blocks and a larger cross-attention context as SDXL uses a second text encoder. We design multiple novel conditioning schemes and train SDXL on multiple aspect ratios. We also introduce a refinement model which is used to improve the visual fidelity of samples generated by SDXL using a post-hoc image-to-image technique. We demonstrate that SDXL shows drastically improved performance compared the previous versions of Stable Diffusion and achieves results competitive with those of black-box state-of-the-art image generators. In the spirit of promoting open research and fostering transparency in large model training and evaluation, we provide access to code and model weights at https://github.com/Stability-AI/generative-models
연구 동기 및 목표
- 이전 Stable Diffusion 버전보다 텍스트-이미지 합성에서 이미지 품질과 프롬프트 준수를 향상시킨다.
- 아키텍처 확장과 다중 종횡비 미세 조정을 통해 고해상도 출력을 가능하게 한다.
- 추가 감독 없이 학습 데이터를 활용하는 사이즈 및 crop 조건화 체계를 도입한다.
- 정제 확산 모델을 통해 왜곡을 줄이고 로컬 디테일을 개선한다.
- 재현성을 위한 코드와 모델 가중치를 제공하여 개방성을 촉진한다.
제안 방법
- 더 많은 어텐션 블록과 더 큰 cross-attention 컨텍스트를 갖춘 UNet 용량을 2.6B 파라미터로 확장한다.
- 원본 이미지의 높이와 너비를 임베딩하고 이를 타임스텝 임베딩에 주입하는 사이즈 조건화를 도입한다.
- 주파수 도메인 인코딩된 자르기 좌표를 통해 훈련 중 무작위 크롭 아티팩트를 제어하기 위한 크롭 조건화를 추가한다.
- 전용 조건화를 갖춘 다양한 종횡비 버킷에서 미세조정하여 다중 종횡비 학습을 수행한다.
- 고주파 디테일을 향상시키기 위해 노이징-디노이징 과정(SDEdit 유사)을 사용하여 잠재 공간에 별도 정제 모델을 학습한다.
- 텍스트 인코더로 OpenCLIP ViT-bigG를 CLIP ViT-L과 조합하여 사용하고, 프리-펜ultimate 출력을 연결하여 조건화에 사용한다.
- 별도의 분류기를 사용하지 않고도 프롬프트를 향하도록 분류기 없는 가이던스를 적용한다.

실험 결과
연구 질문
- RQ1Stable Diffusion 프레임워크를 확장하여 고해상도 이미지 합성을 위한 충실도와 프롬프트 준수를 어떻게 향상시킬 수 있는가?
- RQ2다양한 학습 데이터 크기와 종횡비를 더 잘 활용하기 위해 어떤 조건화 전략을 잠재 확산 모델에 추가할 수 있는가?
- RQ3Latent 공간의 포스트-호크 정제 단계가 외부 감독 없이 시각적 품질을 향상시키는가?
- RQ4크기- 및 크롭 조건화가 대규모 확산 모델의 생성 품질과 아티팩트 감소에 어떤 영향을 미치는가?
- RQ5다중 종횡비 학습이 다양한 출력 형태에서 성능에 어떤 영향을 주는가?
주요 결과
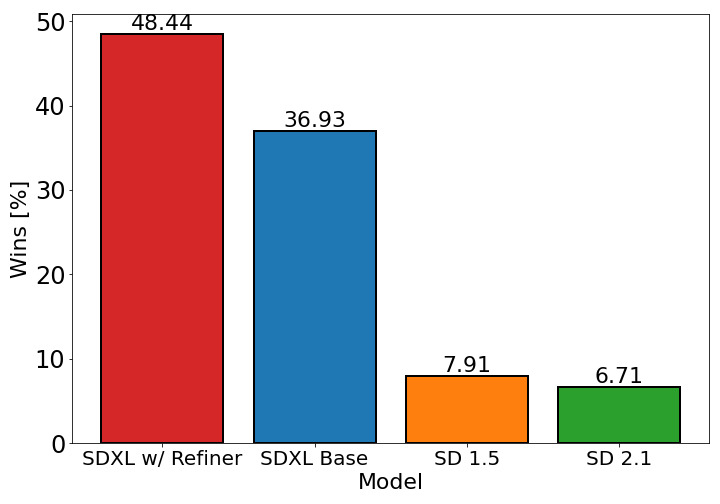
- SDXL은 이미지 품질과 프롬프트 준수 면에서 기존의 이전 Stable Diffusion 버전보다 사용자 연구에서 상당히 우수하다.
- 정제 모델은 기본 SDXL보다 지각된 이미지 충실도를 추가로 향상시키며 평가에서 가장 높은 사용자 선호를 달성한다.
- 재현성 및 투명성을 뒷받침하기 위해 오픈 소스 가중치와 코드가 제공된다.
- 사이즈 조건화와 크롭 조건화는 훈련 시간 데이터 손실과 아티팩트를 줄여 샘플 품질을 개선한다.
- 다중 종횡비 학습은 다양한 종횡비에서 심각한 저하 없이 효과적으로 생성할 수 있게 한다.
- 정량적 지표(FID/CLIP)는 인간의 판단과 완전히 일치하지 않으며, 기본 텍스트-이미지 모델에 대한 인간 평가의 중요성을 강조한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.