[논문 리뷰] Searching for Best Practices in Retrieval-Augmented Generation
이 논문은 검색 증강 생성(RAG) 파이프라인을 구축하기 위한 최선의 실천 방법을 체계적으로 조사하고, 질의 분류, 청크화, 임베딩 모델, 벡터 데이터베이스, 검색 방법, 재정렬, 재패킹, 요약 및 생성기 미세조정에 걸친 구성 요소 선택을 평가하며, 다중 모달 검색 및 효율성 중심 구성이 강조된다.
Retrieval-augmented generation (RAG) techniques have proven to be effective in integrating up-to-date information, mitigating hallucinations, and enhancing response quality, particularly in specialized domains. While many RAG approaches have been proposed to enhance large language models through query-dependent retrievals, these approaches still suffer from their complex implementation and prolonged response times. Typically, a RAG workflow involves multiple processing steps, each of which can be executed in various ways. Here, we investigate existing RAG approaches and their potential combinations to identify optimal RAG practices. Through extensive experiments, we suggest several strategies for deploying RAG that balance both performance and efficiency. Moreover, we demonstrate that multimodal retrieval techniques can significantly enhance question-answering capabilities about visual inputs and accelerate the generation of multimodal content using a "retrieval as generation" strategy.
연구 동기 및 목표
- 광범위한 실험을 통해 최적의 RAG 워크플로 컴포넌트와 그 조합을 식별한다.
- 일반, 도메인 특화 및 다중 모달 작업에 걸친 RAG 성능을 평가하기 위한 포괄적인 평가 프레임워크와 데이터셋을 제공한다.
- 다중 모달 검색이 시각 입력에 대한 QA를 향상시키고 retrieval-as-generation 접근법을 이용한 다중 모달 콘텐츠 생성을 가속화할 수 있음을 입증한다.
제안 방법
- 대표 작업에서의 성능으로 각 RAG 모듈 후보 방법을 세 단계로 선별한다.
- 한 요소씩 제거해 각 모듈이 전체 RAG 성능에 기여하는 바를 측정한다.
- 다양한 시나리오에 대해 성능 또는 효율성을 우선시하는 조합을 실증적으로 탐구한다.
- 평가에는 일반상식, 사실 확인, 오픈 도메인 QA, 다중 호프 QA, 의료 QA 등 다양한 작업 집합과 Faithfulness, Context Relevancy, Answer Relevancy, Answer Correctness 등의 지표를 사용한다.
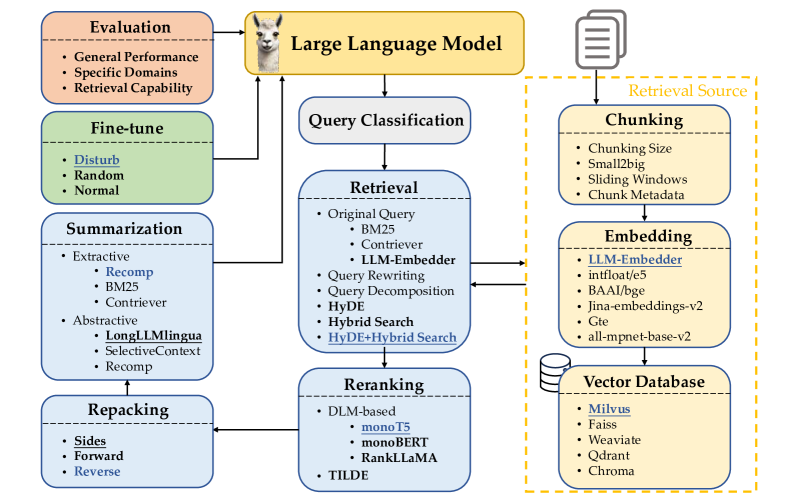
실험 결과
연구 질문
- RQ1질의 분류, 청크화, 임베딩, 벡터 저장소, 검색, 재정렬, 재포장, 요약, 그리고 생성기 미세조정 등 각 모듈에서 RAG 파이프라인의 최적 수행 방법은 무엇인가?
- RQ2각 모듈이 전체 RAG 성능에 얼마나 기여하며 어떤 조합이 정확도와 효율성 사이의 최적의 절충을 이루는가?
- RQ3다중 모달 검색은 시각 입력에 대한 QA를 크게 개선하고 retrieval-as-generation 전략을 통해 다중 모달 콘텐츠 생성을 가속화할 수 있는가?
주요 결과
| Method | TREC DL19 mAP | TREC DL19 nDCG@10 | TREC DL19 R@50 | TREC DL19 R@1k | Latency | DL20 mAP | DL20 nDCG@10 | DL20 R@50 | DL20 R@1k | Latency |
|---|---|---|---|---|---|---|---|---|---|---|
| BM25 | 30.13 | 50.58 | 38.32 | 75.01 | 0.07 | 28.56 | 47.96 | 46.18 | 78.63 | 0.29 |
| Contriever | 23.99 | 44.54 | 37.54 | 74.59 | 3.06 | 23.98 | 42.13 | 43.81 | 75.39 | 0.98 |
| LLM-Embedder | 44.66 | 70.20 | 49.06 | 84.48 | 2.61 | 45.60 | 68.76 | 61.36 | 84.41 | 0.71 |
| + Query Rewriting | 44.56 | 67.89 | 51.45 | 85.35 | 7.80 | 45.16 | 65.62 | 59.63 | 83.45 | 2.06 |
| + Query Decomposition | 41.93 | 66.10 | 48.66 | 82.62 | 14.98 | 43.30 | 64.95 | 57.74 | 84.18 | 2.01 |
| + HyDE | 50.87 | 75.44 | 54.93 | 88.76 | 7.21 | 50.94 | 73.94 | 63.80 | 88.03 | 2.14 |
| + Hybrid Search | 47.14 | 72.50 | 51.13 | 89.08 | 3.20 | 47.72 | 69.80 | 64.32 | 88.04 | 0.77 |
| + HyDE + Hybrid Search | 52.13 | 73.34 | 55.38 | 90.42 | 11.16 | 53.13 | 72.72 | 66.14 | 90.67 | 2.95 |
- 희소 기반(BM25)과 밀집 임베딩의 하이브리드 검색과 HyDE 기반 질의/문서 변환의 결합은 합리적 지연으로 강력한 성능을 제공합니다.
- 질의 재작성 및 질의 분해는 평가된 설정에서 Retrieval 성능에 대해 HyDE나 하이브드 전략보다 덜 효과적이다.
- 표준 벤치마크에서 최고의 총합 RAG 성능은 HyDE+Hybrid Search로, LLM-Embedder 임베딩과 강력한 재정렬기 (monoT5)를 사용했을 때 달성된다.
- 생성기 미세조정 중 관련 문서와 무작위 문서를 함께 사용하는 것이 관련 문서만 사용하거나 무작위 문서만 사용하는 것보다 견고성과 효과를 향상시킨다.
- 다중 모달 검색은 시각 입력에서의 QA를 크게 향상시키고 retrieval-as-generation 방식을 통해 다중 모달 콘텐츠 생성 속도를 높인다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.