[논문 리뷰] Secrets of RLHF in Large Language Models Part I: PPO
이 논문은 LLM 정렬을 위한 PPO를 활용한 RLHF를 분석하고, 안정적인 학습의 핵심으로 정책 제약을 확인하며, 학습 안정성과 확장성을 개선하기 위해 PPO-max를 도입하고, 공개된 보상 모델과 PPO 코드를 포함한다.
Large language models (LLMs) have formulated a blueprint for the advancement of artificial general intelligence. Its primary objective is to function as a human-centric (helpful, honest, and harmless) assistant. Alignment with humans assumes paramount significance, and reinforcement learning with human feedback (RLHF) emerges as the pivotal technological paradigm underpinning this pursuit. Current technical routes usually include extbf{reward models} to measure human preferences, extbf{Proximal Policy Optimization} (PPO) to optimize policy model outputs, and extbf{process supervision} to improve step-by-step reasoning capabilities. However, due to the challenges of reward design, environment interaction, and agent training, coupled with huge trial and error cost of large language models, there is a significant barrier for AI researchers to motivate the development of technical alignment and safe landing of LLMs. The stable training of RLHF has still been a puzzle. In the first report, we dissect the framework of RLHF, re-evaluate the inner workings of PPO, and explore how the parts comprising PPO algorithms impact policy agent training. We identify policy constraints being the key factor for the effective implementation of the PPO algorithm. Therefore, we explore the PPO-max, an advanced version of PPO algorithm, to efficiently improve the training stability of the policy model. Based on our main results, we perform a comprehensive analysis of RLHF abilities compared with SFT models and ChatGPT. The absence of open-source implementations has posed significant challenges to the investigation of LLMs alignment. Therefore, we are eager to release technical reports, reward models and PPO codes, aiming to make modest contributions to the advancement of LLMs.
연구 동기 및 목표
- LLM 정렬을 위한 RLHF 프레임워크와 그 학습 구성요소(SFT, RM, PPO)를 설명한다.
- 보상 모델의 품질과 PPO 설계가 정책 학습 및 안정성에 어떤 영향을 미치는지 평가한다.
- PPO 구현 세부사항을 조사하고 학습 안정성 및 성능을 좌우하는 요인을 식별한다.
제안 방법
- RLHF 프레임워크를 해부하고 PPO 내부 작동을 재평가하여 구성요소가 정책 학습에 어떤 영향을 미치는지 연구한다.
- 더 큰 코퍼스와 더 긴 학습 단계가 가능하도록 훈련 안정성을 높이는 고급 PPO 변형인 PPO-max를 제안한다.
- 크로스 모델 일반화 능력을 갖춘 중국어 및 영어 보상 모델을 개발하고 공개한다.
- PPO 학습 안정성을 모니터링하기 위해 행동 공간 지표(perplexity, 응답 길이, SFT 대비 KL 발산) 등을 사용한다.
- PPO-max를 7B 및 13B SFT 모델에서 평가하고 ChatGPT와의 정렬을 비교한다.
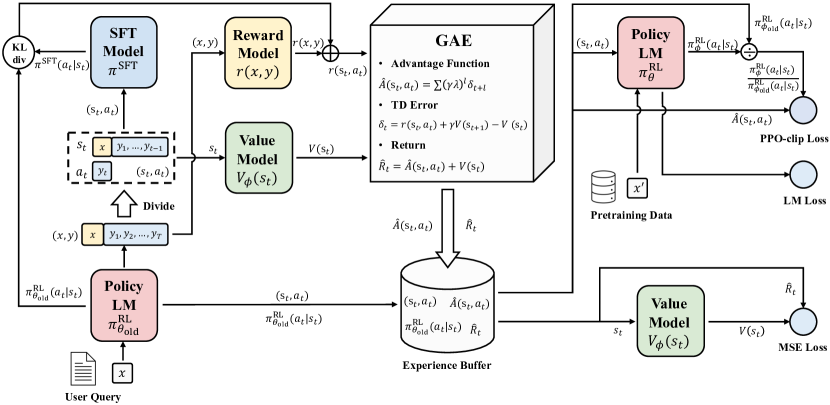
실험 결과
연구 질문
- RQ1RLHF 설정에서 보상 모델의 품질이 RL 정책의 성능을 어떤 한계로 제약하는가?
- RQ2LLM에서 학습 안정성과 정렬 결과에 가장 큰 영향을 미치는 PPO 설계 선택은 무엇인가?
- RQ3최적화된 PPO 변형(PPO-max)이 안정성을 개선하고 언어 능력을 해치지 않으면서 더 큰 학습 단계를 가능하게 할 수 있는가?
- RQ4언어와 데이터(영어 대 중국어)가 보상 모델 학습 및 RLHF 결과에 어떤 영향을 미치는가?
주요 결과
- 보상 모델의 품질은 정책 모델의 성능 상한을 직접 결정한다.
- PPO 내의 정책 제약은 안정적인 RLHF 학습에 있어 중요하다.
- PPO-max는 학습 안정성을 개선하고 더 긴 학습 단계와 더 큰 코퍼스를 지원한다.
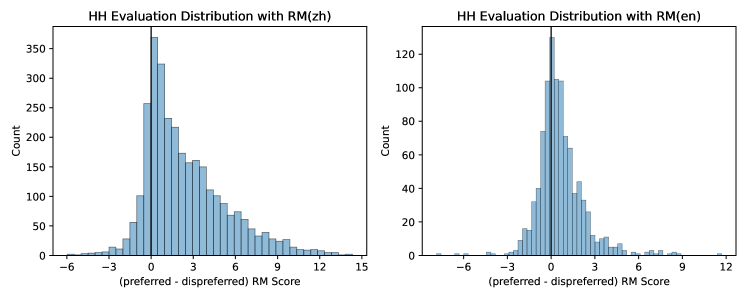
- 중국어 보상 모델은 테스트에서 HH 평가에서 영어 모델보다 인간 선호도와 더 강하게 정렬되는 경향을 보인다.
- RLHF로 학습된 모델은 때때로 쿼리의 심오한 의미를 더 잘 파악하고 사용자에게 더 직접적으로 공감되는 응답을 생성할 수 있다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.