[논문 리뷰] SecureFalcon: Are We There Yet in Automated Software Vulnerability Detection with LLMs?
SecureFalcon은 FalconLLM 7b를 미세조정하여 FormAI 데이터셋으로 C 코드의 취약점을 탐지하고, 취약점 탐지 정확도 94%를 달성하며 수리 제안을 가능하게 합니다.
Software vulnerabilities can cause numerous problems, including crashes, data loss, and security breaches. These issues greatly compromise quality and can negatively impact the market adoption of software applications and systems. Traditional bug-fixing methods, such as static analysis, often produce false positives. While bounded model checking, a form of Formal Verification (FV), can provide more accurate outcomes compared to static analyzers, it demands substantial resources and significantly hinders developer productivity. Can Machine Learning (ML) achieve accuracy comparable to FV methods and be used in popular instant code completion frameworks in near real-time? In this paper, we introduce SecureFalcon, an innovative model architecture with only 121 million parameters derived from the Falcon-40B model and explicitly tailored for classifying software vulnerabilities. To achieve the best performance, we trained our model using two datasets, namely the FormAI dataset and the FalconVulnDB. The FalconVulnDB is a combination of recent public datasets, namely the SySeVR framework, Draper VDISC, Bigvul, Diversevul, SARD Juliet, and ReVeal datasets. These datasets contain the top 25 most dangerous software weaknesses, such as CWE-119, CWE-120, CWE-476, CWE-122, CWE-190, CWE-121, CWE-78, CWE-787, CWE-20, and CWE-762. SecureFalcon achieves 94% accuracy in binary classification and up to 92% in multiclassification, with instant CPU inference times. It outperforms existing models such as BERT, RoBERTa, CodeBERT, and traditional ML algorithms, promising to push the boundaries of software vulnerability detection and instant code completion frameworks.
연구 동기 및 목표
- 대형 언어 모델(LLMs)을 활용한 소프트웨어 취약점 탐지 개선 동기 제시.
- C 코드 샘플의 이진 취약점 분류를 위해 FalconLLM를 미세조정합니다.
- FormAI 데이터셋을 생성하고 활용하여 취약점 탐지 성능을 평가합니다.
- 수정 지향 모델을 통한 프롬프트를 통해 취약점 수리 기능을 제공합니다.
- SecureFalcon의 구성 변형 및 실제 배치 고려사항 평가.
제안 방법
- FormAI로 파생된 C 코드에서 42 CWE 레이블로 FalconLLM 7b를 미세조정.
- 헤더 노이즈, HTML, 이메일 주소 제거로 데이터 전처리; 레이블을 수치로 인코딩.
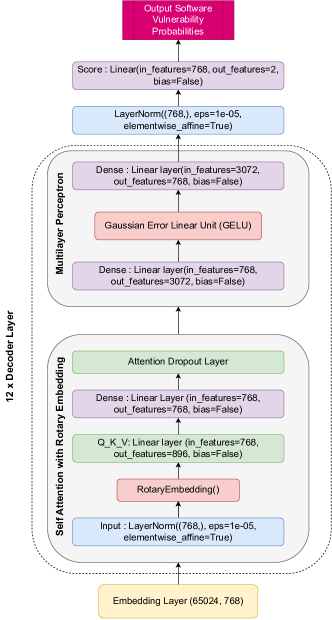
- 768-차 디코더 출력에서 2클래스로 매핑하는 시그모이드가 있는 두-레이블 취약점 점수 계산 헤드를 구현.
- 셀프 어텐션에서 Rotation Position Embedding (RoPE) 사용 및 디코더 계층에서 GELU 활성화를 갖는 MLP.
- AdamW 옵티마이저, LR 스케줄(2e-2 및 2e-5), 조기 중단, 교차 엔트로피 손실로 학습.
- 두 구성(121M 및 44M 파라미터) 평가 및 Falcon-40B-Instruct 프롬프트를 통한 취약점 수리 시연.
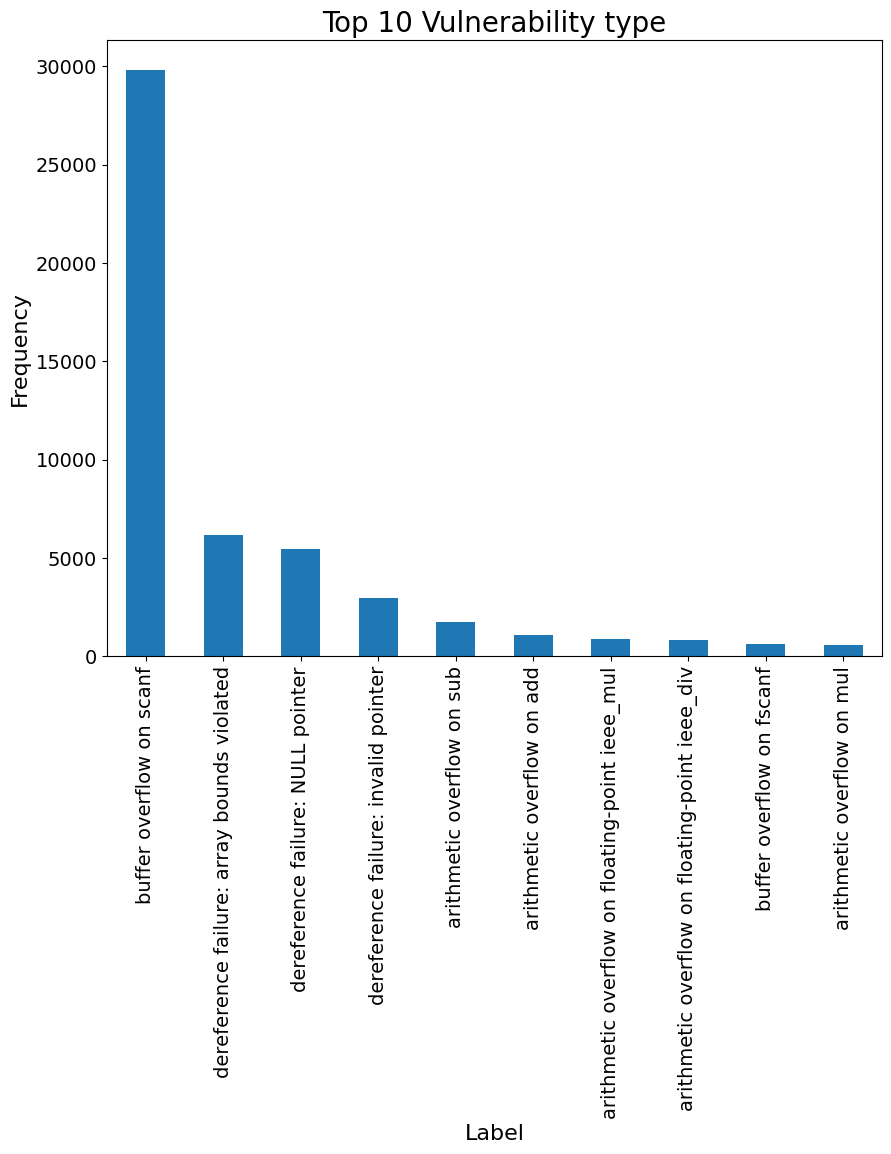
실험 결과
연구 질문
- RQ1FalconLLM을 취약한 C 코드 샘플과 비취약 샘플을 효과적으로 구분하도록 미세조정할 수 있는가?
- RQ2모델 크기(121M 대 44M)가 취약점 탐지 성능에 미치는 영향은 무엇인가?
- RQ342 CWE 카테고리 전반에서 FormAI 기반 취약점 분포에 대해 SecureFalcon은 얼마나 잘 수행하는가?
- RQ4감지된 취약점에 대한 수정 절차를 제안하도록 시스템을 확장할 수 있는가?
주요 결과
- SecureFalcon은 FormAI 유래 데이터에서 취약점 검출에 높은 정확도를 달성합니다(구성별 학습 에포크에서 보고된 정확도 구체적 지표).
- 두 구성(121M 및 44M)이 서로 다른 학습률(LR=2e-5 및 LR=2e-2) 하에서 에포크 전반에 걸쳐 정확도가 점진적으로 개선됩니다.
- LR=2e-5인 SecureFalcon 121M의 학습 정확도는 에포크 7에서 0.97, 검증 정확도는 0.94에 도달합니다.
- FormAI 데이터셋은 42 CWE 카테고리와 표기된 샘플 전반에 걸쳐 112,000개의 C 프로그램과 197,800개의 취약점을 포함합니다.
- 연구는 또한 취약점 탐지 후 수정을 제안하기 위해 FalconLLM을 수리 시스템으로 사용하는 것을 시연합니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.