[논문 리뷰] Securing Large Language Models: Threats, Vulnerabilities and Responsible Practices
이 논문은 대형 언어 모델에 대한 보안 및 프라이버시 문제, 적대적 공격에 대한 취약성, 오용 위험 및 완화 전략을 조사하고 향후 연구 방향을 제시한다.
Large language models (LLMs) have significantly transformed the landscape of Natural Language Processing (NLP). Their impact extends across a diverse spectrum of tasks, revolutionizing how we approach language understanding and generations. Nevertheless, alongside their remarkable utility, LLMs introduce critical security and risk considerations. These challenges warrant careful examination to ensure responsible deployment and safeguard against potential vulnerabilities. This research paper thoroughly investigates security and privacy concerns related to LLMs from five thematic perspectives: security and privacy concerns, vulnerabilities against adversarial attacks, potential harms caused by misuses of LLMs, mitigation strategies to address these challenges while identifying limitations of current strategies. Lastly, the paper recommends promising avenues for future research to enhance the security and risk management of LLMs.
연구 동기 및 목표
- 모델 기반, 학습 시기, 추론 시기 단계에서 LLM 사용으로부터 발생하는 보안 및 프라이버시 문제를 식별한다.
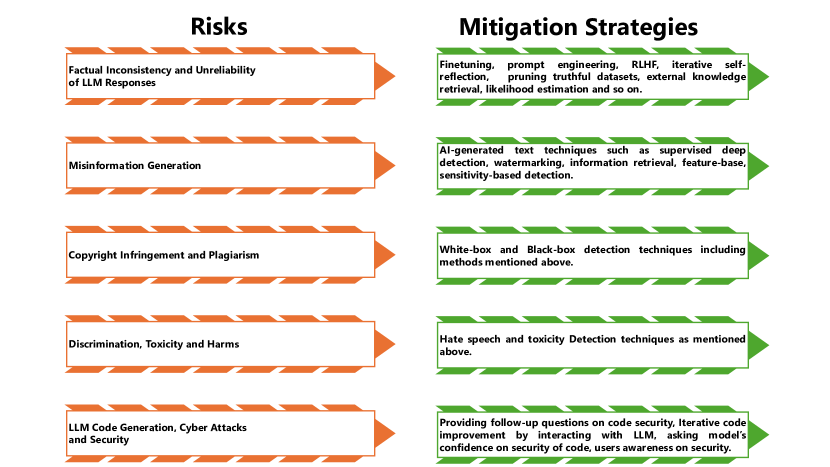
- 적대적 공격과 남용에서 발생하는 취약점과 잠재적 피해를 분류한다.
- 적·녹팀 테스트, 모델 편집, 워터마킹, 탐지 방법 등의 완화 전략을 검토하고 평가한다.
- 향후 연구 방향을 제시하여 LLM 보안 및 위험 관리의 향상을 도모한다.
제안 방법
- 대응책을 포함하여 LLM 취약점을 모델 기반, 학습 시기, 추론 시기 범주로 분류한다.
- 기존 문헌에서 기억화, 데이터 누출 및 프라이버시 위험을 검토한다.
- 코드 생성 보안 문제와 탐지 및 워터마킹 접근법의 효과를 분석한다.
- 홍·녹팀 구상, 워터마킹 및 탐지 기법을 포함한 완화 전략을 요약하고 그 한계와 트레이드오프를 논의한다.
- LLM 보안의 격차를 식별하고 향후 연구 방향을 제시한다.
실험 결과
연구 질문
- RQ1LLM과 관련된 주요 보안 및 프라이버시 문제는 무엇인가?
- RQ2적대적 공격은 LLM의 모델 기반, 학습 시기 및 추론 시기의 취약점을 어떻게 악용하는가?
- RQ3LLM에서 어떤 오용과 피해가 발생할 수 있으며 이를 어떻게 완화할 수 있는가?
- RQ4현재 완화 전략의 한계는 무엇이며 향후 연구가 어디에 집중되어야 하는가?
주요 결과
- 대형 언어 모델은 광범위한 웹 자료로의 사전 학습으로 인해 정보 누출 및 기억화 위험을 제기한다.
- LLM이 생성한 코드에 보안상 허점이 있어 악용될 수 있다.
- 취약점은 모델 기반, 학습 시기, 추론 시기 범주에 걸쳐 있으며 다양한 대응책이 존재한다.
- 완화 전략에는 레드 팀팅, 모델 편집, 워터마킹 및 탐지 방법이 포함되며 각각 한계와 트레이드오프가 있다.
- 본 논문은 LLM의 보안 및 위험 관리 향상을 위한 향후 연구 방향을 제시한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.