[논문 리뷰] (Security) Assertions by Large Language Models
그 논문은 벤치마크 세트와 프롬프트 기반 프롬트를 사용하여 자동으로 하드웨어 보안 주장(hardware security assertions)을 생성하기 위해 즉시 사용 가능한 대형 언어 모델을 평가하고, 평가를 위한 오픈 소스 프레임워크를 공개한다.
The security of computer systems typically relies on a hardware root of trust. As vulnerabilities in hardware can have severe implications on a system, there is a need for techniques to support security verification activities. Assertion-based verification is a popular verification technique that involves capturing design intent in a set of assertions that can be used in formal verification or testing-based checking. However, writing security-centric assertions is a challenging task. In this work, we investigate the use of emerging large language models (LLMs) for code generation in hardware assertion generation for security, where primarily natural language prompts, such as those one would see as code comments in assertion files, are used to produce SystemVerilog assertions. We focus our attention on a popular LLM and characterize its ability to write assertions out of the box, given varying levels of detail in the prompt. We design an evaluation framework that generates a variety of prompts, and we create a benchmark suite comprising real-world hardware designs and corresponding golden reference assertions that we want to generate with the LLM.
연구 동기 및 목표
- 주장(assertions)이 설계 의도와 취약성 점검을 포착하는 하드웨어 보안 검증의 동기를 부여한다.
- 즉시 사용 가능한 LLM이 자연어 프롬프트로부터 SystemVerilog 보안 주장를 생성할 수 있는지 평가한다.
- LLM 성능을 측정하기 위한 벤치마크, 프롬프트 및 검증 파이프라인을 포함한 평가 프레임워크를 개발한다.
- LLM 지원 하드웨어 주장 생성에 대한 추가 연구를 지원하기 위해 프레임워크와 벤치마크를 오픈 소스로 공개한다.
제안 방법
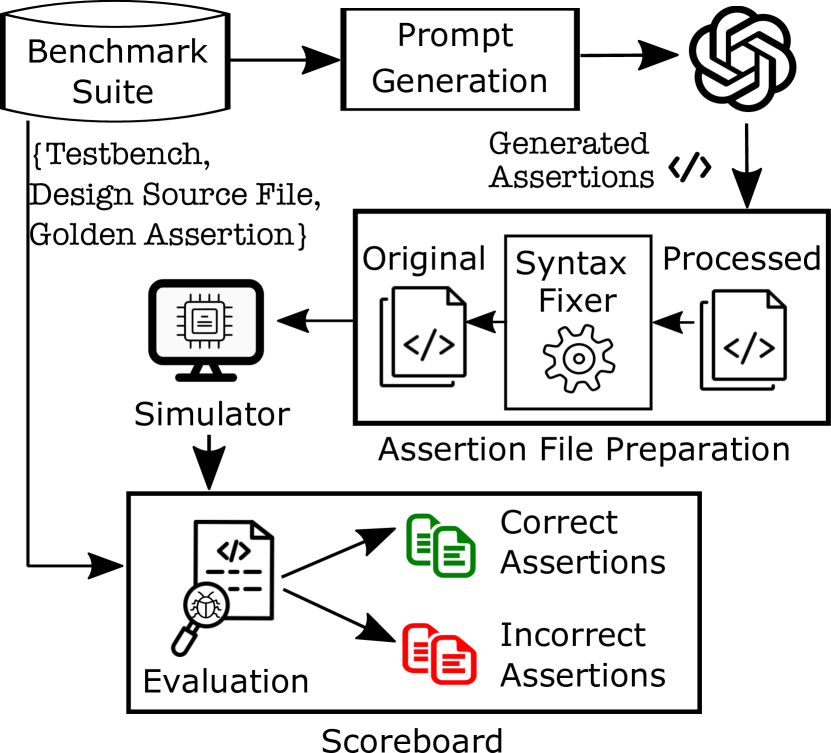
- 실제 하드웨어 설계의 벤치마크 세트를 설계하고 대응하는 골든 레퍼런스 주장을 마련한다.
- 설계 맥락, 예시 주장, 주석의 다양한 상세 수준을 결합하는 프롬프트 생성기를 만든다.
- 일반적인 LLM 실수를 수정하고 검증을 위해 처리된 주장을 준비하는 주장 파일 생성기를 구현한다.
- 시뮬레이터(Modelsim)를 사용하여 위반 매칭에 기반해 LLM이 생성한 주장과 골든 레퍼런스를 비교한다.
- 위반을 발생시키는 입력을 매칭해 처리된 주장을 올바른지/잘못된지로 분류하는 점수표로 정확도를 평가한다.
실험 결과
연구 질문
- RQ1RQ1: 대형 언어 모델은 즉시 사용 가능한 상태로 하드웨어 보안 주장을 생성할 수 있는가?
- RQ2RQ2: 서로 다른 프롬프트 유형이 생성된 주장들의 품질과 정확도에 어떤 영향을 미치는가?
주요 결과
- LLM 주도 파이프라인은 다양한 벤치마크에 걸쳐 하드웨어 보안 주장을 생성할 수 있다.
- 프롬프트 설계(설계 맥락, 주석 세부 정보, 예시, 시작 부분)가 주장 품질에 상당한 영향을 미친다.
- 고정된 자동 수정 집합이 일반적인 구문/오타 문제를 수정할 수 있으며 성능을 저하시키지 않으면서도 작동한다.
- 처리 및 중복 제거를 통해 상당한 수의 사용 가능한 주장들이 생겨나며, 그 중 일부가 검증에서 골든 레퍼런스와 일치한다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.