[논문 리뷰] Security Weaknesses of Copilot-Generated Code in GitHub Projects: An Empirical Study
GitHub 프로젝트의 Copilot-생성 코드 스니펫 435건을 분석한 실증 연구로, CodeQL 및 언어별 정적 분석 도구를 사용해 여섯 가지 언어 전반의 보안 취약점과 CWE를 식별함.
Modern code generation tools utilizing AI models like Large Language Models (LLMs) have gained increased popularity due to their ability to produce functional code. However, their usage presents security challenges, often resulting in insecure code merging into the code base. Thus, evaluating the quality of generated code, especially its security, is crucial. While prior research explored various aspects of code generation, the focus on security has been limited, mostly examining code produced in controlled environments rather than open source development scenarios. To address this gap, we conducted an empirical study, analyzing code snippets generated by GitHub Copilot and two other AI code generation tools (i.e., CodeWhisperer and Codeium) from GitHub projects. Our analysis identified 733 snippets, revealing a high likelihood of security weaknesses, with 29.5% of Python and 24.2% of JavaScript snippets affected. These issues span 43 Common Weakness Enumeration (CWE) categories, including significant ones like CWE-330: Use of Insufficiently Random Values, CWE-94: Improper Control of Generation of Code, and CWE-79: Cross-site Scripting. Notably, eight of those CWEs are among the 2023 CWE Top-25, highlighting their severity. We further examined using Copilot Chat to fix security issues in Copilot-generated code by providing Copilot Chat with warning messages from the static analysis tools, and up to 55.5% of the security issues can be fixed. We finally provide the suggestions for mitigating security issues in generated code.
연구 동기 및 목표
- 현실 세계의 GitHub 프로젝트에서 Copilot-generated 코드의 보안 취약점이 얼마나 일반적인지 평가한다.
- Copilot으로 생성된 스니펫에 존재하는 보안 취약점의 유형(CWEs)을 식별한다.
- 식별된 취약점 중 MITRE CWE Top-25에 얼마나 많이 일치하는지 평가한다.
- Copilot 생성 코드를 사용할 때 개발자를 위한 보안 관행에 대한 지침을 제공한다.
제안 방법
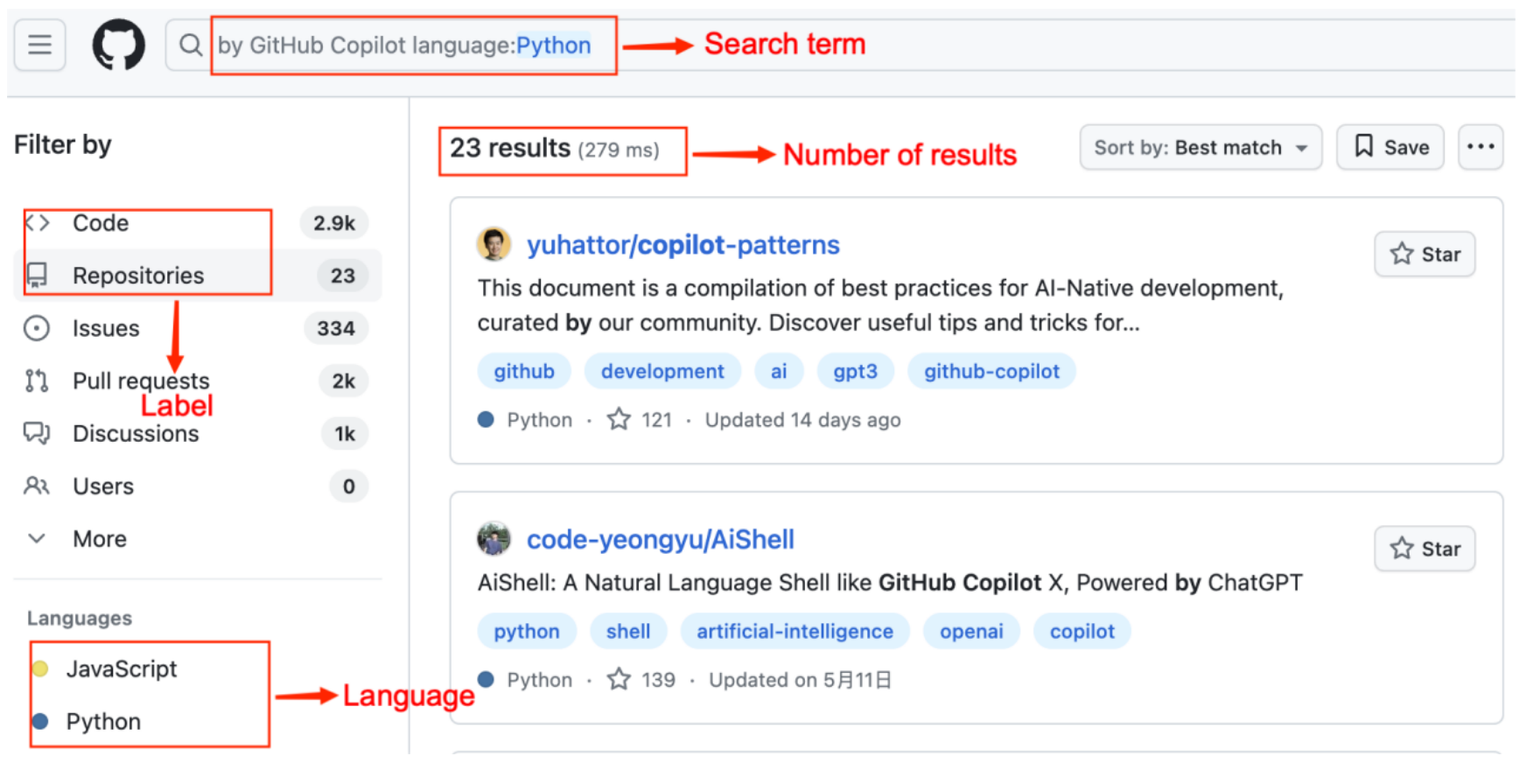
- GitHub 프로젝트에서 Copilot으로 생성된 코드 스니펫 데이터셋을 선별한다(총 435건; Repository-label 249건, Code-label 186건).
- 다중 도구 정적 분석(CodeQL과 언어별 도구)을 수행해 여섯 가지 언어(Python, JavaScript, Java, C++, Go, C#)에 걸친 CWE를 식별한다.
- 도구 결과를 CWE ID로 매핑한다(일부 도구에 대해서는 수동 매핑 포함).
- 스니펫이 실제로 Copilot 생성되었고 보안 취약점과 관련이 있는지 여부를 보장하기 위해 결과를 필터링한다.
- 결과를 집계해 CWE의 발생 현황과 분포를 파악하고 MITRE Top-25와의 일치를 포함한다.

실험 결과
연구 질문
- RQ1RQ1: GitHub 프로젝트에서 Copilot이 생성한 코드의 보안은 얼마나 안정적인가?
- RQ2RQ2: Copilot으로 생성된 코드 스니펫에 어떤 보안 취약점이 존재하는가?
- RQ3RQ3: 검출된 취약점 중 2022년 MITRE CWE Top-25에 속하는 비율은 얼마나 되는가?
주요 결과
- Copilot으로 생성된 코드 스니펫의 35.8%에 보안 취약점이 존재한다.
- 취약점은 여섯 가지 언어에 걸치고 42개의 CWE로 확산되며, CWE-78(OS Command Injection), CWE-330(Use of Insufficiently Random Values), CWE-703(Improper Check or Handling of Exceptional Conditions)이 가장 많이 나타난다.
- 42개의 CWE 중 11개가 2022년 CWE Top-25의 일부이다.
- Python은 39.4%로 가장 높은 취약점 비율을 보이고; C++와 Go는 각각 46.1%, 45.0%로 언어별 비율이 특히 높다.
- Go와 Python은 취약점의 절대 수가 더 많아 Copilot 사용에서의 인기를 반영한다.
- 향후 연구를 위해 선별된 Copilot 생성 코드 데이터셋과 재현 패키지가 제공된다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.