[논문 리뷰] See, Think, Confirm: Interactive Prompting Between Vision and Language Models for Knowledge-based Visual Reasoning
IPVR는 시각적 개념을 근거로 삼고, LLM으로 추론하며, 합리화를 검증하여 지식 기반 시각 추론 작업을 해결하기 위한 인터랙티브하고 반복적인 프롬프트 프레임워크로, 투명한 단계별 설명을 제공합니다.
Large pre-trained vision and language models have demonstrated remarkable capacities for various tasks. However, solving the knowledge-based visual reasoning tasks remains challenging, which requires a model to comprehensively understand image content, connect the external world knowledge, and perform step-by-step reasoning to answer the questions correctly. To this end, we propose a novel framework named Interactive Prompting Visual Reasoner (IPVR) for few-shot knowledge-based visual reasoning. IPVR contains three stages, see, think and confirm. The see stage scans the image and grounds the visual concept candidates with a visual perception model. The think stage adopts a pre-trained large language model (LLM) to attend to the key concepts from candidates adaptively. It then transforms them into text context for prompting with a visual captioning model and adopts the LLM to generate the answer. The confirm stage further uses the LLM to generate the supporting rationale to the answer, verify the generated rationale with a cross-modality classifier and ensure that the rationale can infer the predicted output consistently. We conduct experiments on a range of knowledge-based visual reasoning datasets. We found our IPVR enjoys several benefits, 1). it achieves better performance than the previous few-shot learning baselines; 2). it enjoys the total transparency and trustworthiness of the whole reasoning process by providing rationales for each reasoning step; 3). it is computation-efficient compared with other fine-tuning baselines.
연구 동기 및 목표
- 지식 기반 시각 추론(KB-VQA)을 이미지 이해와 외부 지식 및 단계별 추론을 결합하여 해결하려는 동기 부여.
- 개념을 근거화하고 맥락 텍스트를 생성하며 답을 반복적으로 정제하는 모듈식 IPVR 파이프라인(see–think–confirm) 제안.
- 합리화를 제공하고 합리화, 이미지 콘텐츠, 출력 간의 일관성을 검증하여 투명성 강화.
- 전체 파인튜닝에 비해 효율성을 높이면서 해석성과 모듈성을 유지.
제안 방법
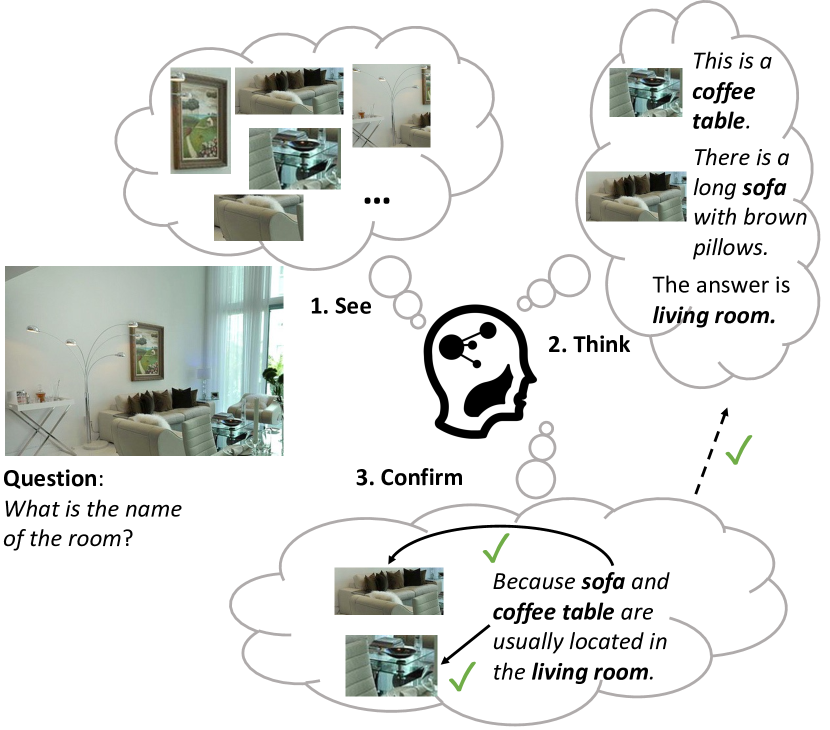
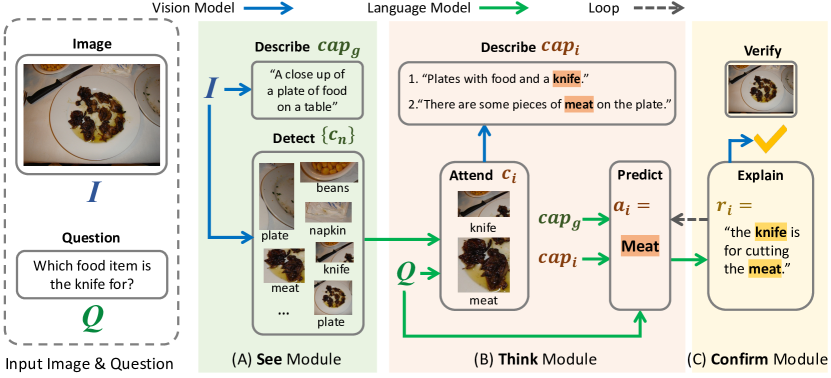
- See 모듈은 장면 파서를 사용하여 이미지의 후보 시각적 개념을 탐지하고 전역 이미지 캡션을 생성합니다.
- Think 모듈은 인-context 프롬PT를 사용하는 LLM으로 핵심 개념에 주목하고, 주목된 개념에 대한 지역 캡션을 생성하며, 답을 예측합니다.
- Confirm 모듈은 LLM에게 합리화를 생성하도록 촉진하고, 합리화의 일관성을 이미지와의 교차 모달 분류기로 검증한 후 루프를 시작합니다.
- 반복 루프는 연속된 두 개의 생각-확인을 수렴할 때까지 생각 및 확인을 반복하여 답과 합리화 흔적을 생성합니다.
- 구현은 객체 개념에 Faster-RCNN, 지역 캡션에 BLIP, LLM으로 OPT-66B, 합리화-이미지 검증에 CLIP를 사용합니다.
실험 결과
연구 질문
- RQ1시각 모델과 언어 모델 간의 인터랙티브 프롬프팅이 소수 예제 프롬프팅으로 KB-VQA에서 높은 정확도를 달성할 수 있는가?
- RQ2반복적 think–confirm 프롬프팅이 투명하고 검증 가능한 추론 흔적을 제공하여 신뢰와 성능을 향상시키는가?
- RQ3각 IPVR 구성요소(attend/describe, rationale generation, verification)가 성능 및 효율성에 미치는 영향은 무엇인가?
- RQ4IPVR이 KB-VQA 벤치마크에서 학습-인-컨텍스트 기반 기준 및 미세조정 기반 접근법과 비교하여 무엇을 보여주는가?
주요 결과
- IPVR은 KB-VQA 벤치마크(OK-VQA 및 A-OKVQA)에서 기존의 소수 샘플 학습 기법보다 더 나은 성능을 달성합니다.
- IPVR은 시각적 개념, 지역 캡션 및 합리화를 포함한 투명한 단계별 추론 흔적을 제공합니다.
- 합리화 생성을 교차 모달 분류기와의 검증이 합리화의 정확도와 일관성을 향상시킵니다.
- IPVR은 전체 파인튜닝 기준에 비해 계산 효율성을 유지하고, 추론 파이프라인을 통한 해석 가능성을 유지합니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.