[논문 리뷰] Segment Anything Model for Medical Image Analysis: an Experimental Study
본 논문은 Segment Anything Model (SAM)을 다양한 모달리티의 19개 의학 영상 데이터셋에서 평가하여 zero-shot 분할 성능과 상호작용 모드를 평가하고, 다른 인터랙티브 방법과의 비교 및 프롬프트 전략을 자세히 설명한다.
Training segmentation models for medical images continues to be challenging due to the limited availability of data annotations. Segment Anything Model (SAM) is a foundation model that is intended to segment user-defined objects of interest in an interactive manner. While the performance on natural images is impressive, medical image domains pose their own set of challenges. Here, we perform an extensive evaluation of SAM's ability to segment medical images on a collection of 19 medical imaging datasets from various modalities and anatomies. We report the following findings: (1) SAM's performance based on single prompts highly varies depending on the dataset and the task, from IoU=0.1135 for spine MRI to IoU=0.8650 for hip X-ray. (2) Segmentation performance appears to be better for well-circumscribed objects with prompts with less ambiguity and poorer in various other scenarios such as the segmentation of brain tumors. (3) SAM performs notably better with box prompts than with point prompts. (4) SAM outperforms similar methods RITM, SimpleClick, and FocalClick in almost all single-point prompt settings. (5) When multiple-point prompts are provided iteratively, SAM's performance generally improves only slightly while other methods' performance improves to the level that surpasses SAM's point-based performance. We also provide several illustrations for SAM's performance on all tested datasets, iterative segmentation, and SAM's behavior given prompt ambiguity. We conclude that SAM shows impressive zero-shot segmentation performance for certain medical imaging datasets, but moderate to poor performance for others. SAM has the potential to make a significant impact in automated medical image segmentation in medical imaging, but appropriate care needs to be applied when using it.
연구 동기 및 목표
- SAM의 제로샷 분할 성능을 광범위한 의학 영상 데이터셋에서 평가한다.
- 프롬프트 전략(포인트 vs 박스)과 프롬프트 반복이 SAM 성능에 미치는 영향을 규명한다.
- RITM, SimpleClick, FocalClick 등 다른 인터랙티브 분할 방법과의 비교를 수행한다.
- 프롬프트-모호성 효과를 확인하고 의학 영상 응용을 위한 실용적 사용 모드를 제시한다.
제안 방법
- MRI, CT, X-ray, 초음파, PET에 걸친 19개의 공개 의학 영상 데이터셋에서 SAM을 평가한다.
- 사용자 상호작용을 시뮬레이션하기 위해 다섯 가지 비반복 프롬프트 모드(포인트 또는 박스)와 반복 프롬프트 체계를 정의한다.
- 주요 정확도 지표로 IoU를 사용하고, 오라클 성능을 상한 프록시로 활용한다.
- 비반복 프롬프트와 반복 프롬프트 하에서 SAM을 RITM, SimpleClick, FocalClick과 비교한다.
- segment-everything 모드와 객체 크기가 성능에 미치는 영향을 분석한다.
- 정성적 시각화 제공 및 프롬프트 모호성 효과를 논의한다.
실험 결과
연구 질문
- RQ1다양한 모달리티와 해부학에서 제로샷 분할을 가진 의학 영상에서 SAM의 성능은 어떠한가?
- RQ2다중부분 구조를 포함한 의학 객체에 대해 어떤 프롬프트 전략(포인트 대 박스)과 모드가 최상의 SAM 성능을 제공하는가?
- RQ3단일 프롬프트 및 다중 프롬프트 하에서 SAM은 다른 인터랙티브 분할 방법과 어떻게 비교되는가?
- RQ4반복 프롬프트가 특히 다부분 객체나 모호한 프롬프트의 경우 SAM 성능을 크게 향상시키는가?
- RQ5의학 영상 주석 및 모델 학습에 SAM을 통합하기 위한 실용적 사용 모드가 무엇인가?
주요 결과
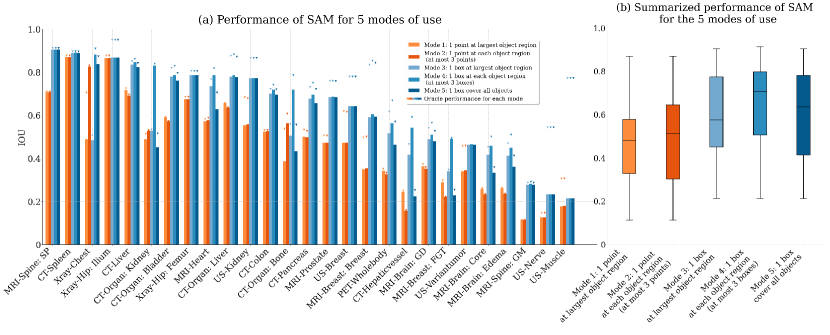
- SAM의 28개 작업에서의 성능은 다양하게 변동하며, IoU 0.1135 (spine MRI)에서 0.8650 (hip X-ray)까지이다.
- 박스 프롬프트가 포인트 프롬프트를 능가하며, 모드 4(객체 부분당 하나의 박스)가 작업 전반에 걸친 최상의 평균 IoU 0.6542를 달성한다.
- 단일 포인트 프롬프트 설정에서 SAM은 일반적으로 RITM, SimpleClick, FocalClick보다 우수하며; 오라클 모드에서 28개 작업 중 26개에서 SAM이 선두를 차지한다.
- 반복 프롬프트는 SAM에 한정된 이점을 제공하고, SimpleClick과 RITM은 추가 포인트로 더 큰 개선을 보이며 일부 사례에서 SAM을 능가할 수 있다.
- SAM은 일부 데이터셋에서 제로샷 가능성을 보이지만, 다른 데이터셋에서는 보통에서 미약한 성능을 보여 주의 깊은 사용과 프롬프트 전략이 필요함을 시사한다.
- 프롬프트의 모호성은 다수의 출력으로 이어질 수 있으며, SAM의 높은 신뢰도 맵은 영역 확장 분할 영역을 닮는 경향이 있고, 낮은 신뢰도 출력은 더 다양하다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.