[논문 리뷰] Self-Evaluation Guided Beam Search for Reasoning
저자들은 단계별 자기 평가를 안내하는 확률적 빔 탐색을 도입하여 LLM의 다단계 추론을 보정하고 가이딩하며, 강력한 기반선 대비 비슷한 비용으로 산술, 기호 및 상식 작업에서 정확도를 향상시킨다.
Breaking down a problem into intermediate steps has demonstrated impressive performance in Large Language Model (LLM) reasoning. However, the growth of the reasoning chain introduces uncertainty and error accumulation, making it challenging to elicit accurate final results. To tackle this challenge of uncertainty in multi-step reasoning, we introduce a stepwise self-evaluation mechanism to guide and calibrate the reasoning process of LLMs. We propose a decoding algorithm integrating the self-evaluation guidance via stochastic beam search. The self-evaluation guidance serves as a better-calibrated automatic criterion, facilitating an efficient search in the reasoning space and resulting in superior prediction quality. Stochastic beam search balances exploitation and exploration of the search space with temperature-controlled randomness. Our approach surpasses the corresponding Codex-backboned baselines in few-shot accuracy by $6.34\%$, $9.56\%$, and $5.46\%$ on the GSM8K, AQuA, and StrategyQA benchmarks, respectively. Experiment results with Llama-2 on arithmetic reasoning demonstrate the efficiency of our method in outperforming the baseline methods with comparable computational budgets. Further analysis in multi-step reasoning finds our self-evaluation guidance pinpoints logic failures and leads to higher consistency and robustness. Our code is publicly available at https://guideddecoding.github.io/.
연구 동기 및 목표
- 다단계 LLM 추론에서의 오류 누적을 줄이기 위해 단계별.self 평가 메커니즘을 도입한다.
- 추론 체인을 위한 탐색과 활용의 균형을 맞추는 제약된 확률적 빔 탐색을 개발한다.
- 생성 신뢰도와 정답 신뢰도를 결합한 자기 평가 점수로 디코딩을 보정한다.
- 산술, 기호 및 상식 추론 벤치마크에서 성능 향상을 입증한다.
- 다양한 백본과 프롬팅 패러다임에서 접근법의 비용 및 강건성을 분석한다.
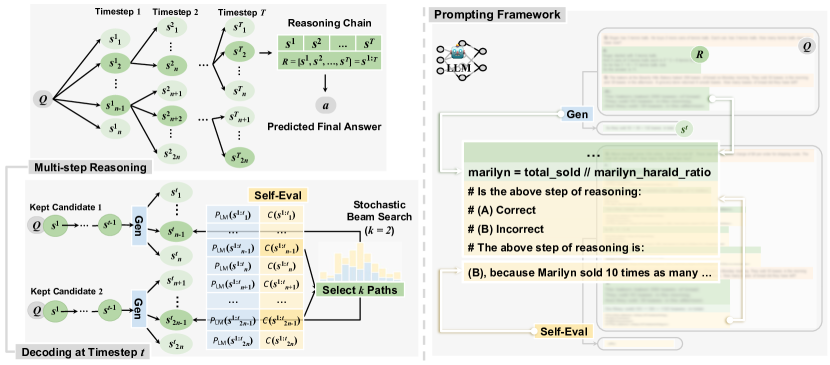
제안 방법
- 각 단계 s^t가 의미적으로 통합된 토큰 시퀀스인 다단계 디코딩 문제로 추론 체인 생성을 정식화한다.
- 각 단계의 LLM 기반 정답 신뢰도를 인코딩하는 제약 함수 C(s^t)를 도입하고 이를 목표 함수 E(s^{1:T})의 LM 확률과 균형 있게 사용한다.
- E(s^{1:T}) = prod_t P_{LM_G}^λ(s^t | x, s^{1:t-1}) * C^{1-λ}(s^t)로 디코딩을 안내한다.
- 빔 크기 k의 확률적 빔 탐색을 적용하고, 빔당 n개의 후보를 샘플링하여 S를 형성한 뒤, exp(E(s^{1:t})/τ)에 비례하여 샘플링으로 가지치기하여 다양성을 촉진한다.
- 무작위성을 점진적으로 감소시키는 온도 감소 α를 도입하여 긴 체인에서의 안정성을 확보한다.
- 자기 평가 LLM(동일 백본, 다른 프롬트)을 사용하여 P(A | prompt_C, Q, s^{1:t})를 통해 다지선다 형태의 정답 확신도 C(s^t)를 생성한다.
- 수학, 기호, 상식 벤치마크에서 Codex 및 Llama-2를 포함한 폐쇄형 및 오픈 소스 LLM과의 실험을 통해 CoT, PAL/PoT 기준선 및 자기 일관성과 비교를 수행한다.
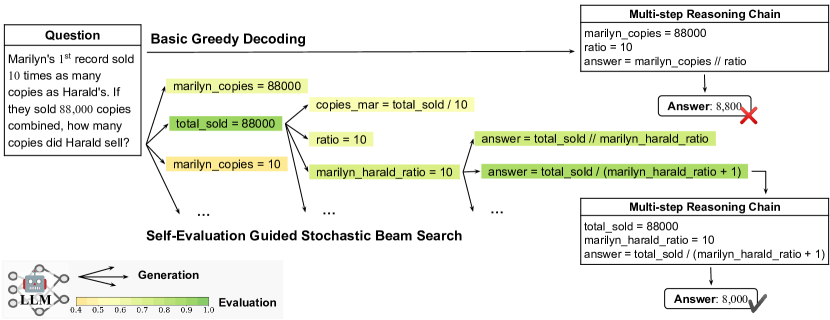
실험 결과
연구 질문
- RQ1단계별 자기 평가가 다단계 추론 체인의 디코딩을 보정하고 오류 누적을 줄일 수 있는가?
- RQ2제어 가능한 무작위성을 가진 확률적 빔 탐색이 고정된 계산 예산 하에서 추론 품질을 개선하는가?
- RQ3제안된 방법이 산술, 기호 및 상식 벤치마크에서 강력한 기준선과 비교해 어떤 성능을 보이는가?
- RQ4자기 일관성과 다른 프롬팅 전략에 비해 비용-성능의 트레이드오프는 어떻게 되는가?
- RQ5생성 신뢰도와 정답 신뢰도는 다양한 과제에서 자기 평가 점수에 어떻게 기여하는가?
주요 결과
- 이 방법은 Codex 기반 기준선 대비 GSM8K, AQuA, StrategyQA 벤치마크에서 단일 및 다중 체인 설정 모두에서 정확도 향상을 달성했다.
- Codex를 이용한 산술 추론에서 Ours-PAL은 GSM8K에서 85.5%, AQuA에서 64.2%를 달성하며 각각 기준선 80.4% 및 58.6%를 능가했다.
- Codex를 이용한 상식 추론에서 Ours-CoT는 StrategyQA에서 77.2%, CommonsenseQA에서 78.6%를 달성하며 각각 기준선 73.2% 및 74.4%를 능가했다.
- 비용 분석 결과 이 방법은 자기 일관성에 비해 토큰 사용이 더 많지만, 특히 긴 추론 체인에서 유사 예산 하에서 이를 능가할 수 있다.
- 생성 신뢰도와 정답 신뢰도 분석에 따르면 정답 신뢰도가 논리적 오류를 포착하는 데 더 구분력이 있으며, 두 신뢰도를 λ로 균형 맞추면 결과가 향상된다(실험에서 λ=0.5 사용).
- 이 방법은 더 긴 추론 체인에서 특히 이익을 보이며, 체인 길이가 길어질수록 StrategyQA에서 더 큰 이득을 얻고, 다양성 기반 샘플링 및 온도 감소 아래에서도 이득이 지속된다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.