[논문 리뷰] Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
Self-Rag은 필요 시 검색하고, 생성하며, 반성 토큰(reflection tokens)을 통해 자신의 출력을 비평하도록 단일 언어 모델을 학습시켜 다양한 작업에서 사실성 및 인용 정확성을 향상시킨다.
Despite their remarkable capabilities, large language models (LLMs) often produce responses containing factual inaccuracies due to their sole reliance on the parametric knowledge they encapsulate. Retrieval-Augmented Generation (RAG), an ad hoc approach that augments LMs with retrieval of relevant knowledge, decreases such issues. However, indiscriminately retrieving and incorporating a fixed number of retrieved passages, regardless of whether retrieval is necessary, or passages are relevant, diminishes LM versatility or can lead to unhelpful response generation. We introduce a new framework called Self-Reflective Retrieval-Augmented Generation (Self-RAG) that enhances an LM's quality and factuality through retrieval and self-reflection. Our framework trains a single arbitrary LM that adaptively retrieves passages on-demand, and generates and reflects on retrieved passages and its own generations using special tokens, called reflection tokens. Generating reflection tokens makes the LM controllable during the inference phase, enabling it to tailor its behavior to diverse task requirements. Experiments show that Self-RAG (7B and 13B parameters) significantly outperforms state-of-the-art LLMs and retrieval-augmented models on a diverse set of tasks. Specifically, Self-RAG outperforms ChatGPT and retrieval-augmented Llama2-chat on Open-domain QA, reasoning and fact verification tasks, and it shows significant gains in improving factuality and citation accuracy for long-form generations relative to these models.
연구 동기 및 목표
- LLM 출력의 다재다능함을 해치지 않으면서 사실성 및 검증 가능성을 개선한다.
- 불필요하거나 관련성 없는 맥락을 피하기 위해 필요 시 검색을 가능하게 한다.
- 자신의 생성 구간을 사실성 및 검색된 단락의 지지에 따라 비판하고 순위를 매기는 자기 반성 메커니즘을 도입한다.
- 구간별 검증 신호가 있는 인용 기반의 출력을 제공하여 사실 확인을 용이하게 한다.
제안 방법
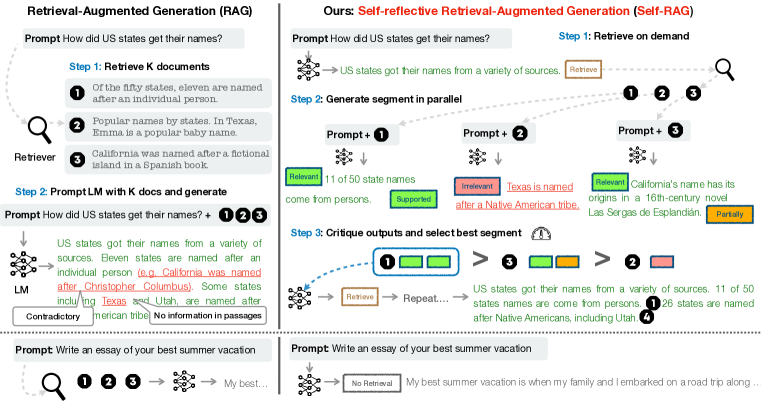
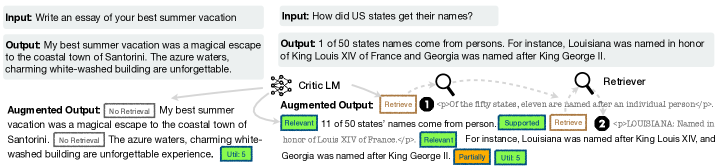
- 반영 토큰을 나타내는 텍스트를 생성하고 검색 필요를 표시하며 자신의 출력을 평가하도록 단일 임의의 LM을 학습시킨다.
- 모델이 먼저 검색 여부를 결정한 후 다수의 검색된 구절을 병렬로 처리하는 필요 시 검색을 사용한다.
- 검색 및 관련성 및 지지 여부를 제어하고 평가하기 위해 네 가지 반성/비평 토큰 유형(Retrieve, IsRel, IsSup, IsUse)을 도입한다.
- 추론 시 별도의 비평 모델이 필요하지 않도록 학습 데이터에 반성 토큰을 오프라인으로 삽입하는 비평가 모델을 활용한다.
- 검색된 구절과 반성 토큰이 포함된 확장 데이터에 대해 표준 LM 목표로 생성기를 학습시킨다.
- 세그먼트 수준의 빔 서치와 반성 토큰 확률의 가중 합계를 사용한 해석 시점의 디코딩 전략을 지원한다.
실험 결과
연구 질문
- RQ1LM이 필요 시 검색을 학습하여 생성 품질을 향상시키되 다재다능성을 해치지 않는가?
- RQ2반성 및 비평 토큰이 장문 생성에서 사실성, 검증 가능성 및 인용 정확성을 더 높여주는가?
- RQ3반성 토큰으로 안내되는 세그먼트 수준 재랭크가 검색 빈도와 출력 품질에 어떤 영향을 미치는가?
- RQ4Self-Rag의 필요 시 검색 및 자기 비평이 출처의 귀속 및 인용에 어떤 영향을 미치는가?
주요 결과
- Self-Rag은 다양한 작업에서 최첨단 LLM 및 검색 강화 모델보다 상당히 우수하게 성능을 발휘한다.
- Self-Rag은 오픈 도메인 QA, 추론, 사실 검증 작업에서 ChatGPT 및 검색 강화 Llama2-chat보다 우수한 성능을 보인다.
- Self-Rag은 이러한 모델에 비해 장문 생성을 위한 사실성 및 인용 정확도에서 상당한 이점을 보여준다.
- 추론 시점의 반성 토큰은 검색 빈도와 작업 중심 목표를 조정할 수 있는 제어 가능한 동작을 가능하게 한다.
- 오프라인으로 삽입된 비평 토큰으로 학습하면 추론 시 외부 보상 모델 의존도가 감소하고 학습 비용이 낮아진다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.