[논문 리뷰] Self-Refine: Iterative Refinement with Self-Feedback
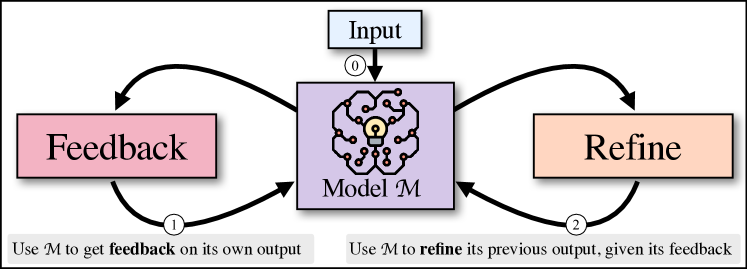
Self-Refine는 단일 대형 언어 모델을 사용하여 초기 출력을 생성한 다음 피드백을 제공하고 반복적으로 개선하며, 추가 훈련 없이도 여러 작업에서 개선을 달성합니다.
Like humans, large language models (LLMs) do not always generate the best output on their first try. Motivated by how humans refine their written text, we introduce Self-Refine, an approach for improving initial outputs from LLMs through iterative feedback and refinement. The main idea is to generate an initial output using an LLMs; then, the same LLMs provides feedback for its output and uses it to refine itself, iteratively. Self-Refine does not require any supervised training data, additional training, or reinforcement learning, and instead uses a single LLM as the generator, refiner, and feedback provider. We evaluate Self-Refine across 7 diverse tasks, ranging from dialog response generation to mathematical reasoning, using state-of-the-art (GPT-3.5, ChatGPT, and GPT-4) LLMs. Across all evaluated tasks, outputs generated with Self-Refine are preferred by humans and automatic metrics over those generated with the same LLM using conventional one-step generation, improving by ~20% absolute on average in task performance. Our work demonstrates that even state-of-the-art LLMs like GPT-4 can be further improved at test time using our simple, standalone approach.
연구 동기 및 목표
- LLM 출력 향상을 인간의 글쓰기 및 문제 해결에서 영감을 받은 반복적 자기 피드백을 통해 촉진하려는 동기 부여.
- 생성, 피드백, 개선에 동일한 LLM을 사용하는 훈련 부재 방법 제안.
- 다양한 작업에 걸친 효과성 시연 및 피드백 품질과 반복 깊이가 미치는 영향 분석.
제안 방법
- 기본 LLM으로 초기 출력 생성.
- 동일한 LLM에 출력을 둘러싼 실행 가능한 피드백을 생성하도록 프롬프트.
- 피드백을 사용하여 같은 LLM에 대한 정교한 프롬프트로 출력을 개선.
- 작업별 중지 조건까지 피드백과 개선을 반복(최대 4회의 반복).
- 외부 훈련 없이 생성, 피드백 및 개선을 안내하기 위한 few-shot 프롬프트 사용.
실험 결과
연구 질문
- RQ1추가 훈련 없이도 단일 LLM이 반복적 자기 피드백과 정교화를 통해 자신의 출력을 개선할 수 있는가?
- RQ2자기 생성 피드백의 품질이 정교화 결과에 어떤 영향을 미치는가?
- RQ3다양한 작업에 대한 다중 피드백-정교화 반복의 영향은 무엇인가?
- RQ4자기 정교화가 다양한 영역에서 단일 패스 생성보다 우수한가?
주요 결과
| 작업 | GPT-3.5 기본 | GPT-3.5 + 우리 | ChatGPT 기본 | ChatGPT + 우리 | GPT-4 기본 | GPT-4 + 우리 |
|---|---|---|---|---|---|---|
| 감정 역전 | 8.8 | 30.4 (↑ 21.6) | 11.4 | 43.2 (↑ 31.8) | 3.8 | 36.2 (↑ 32.4) |
| 대화 응답 | 36.4 | 63.6 (↑ 27.2) | 40.1 | 59.9 (↑ 19.8) | 25.4 | 74.6 (↑ 49.2) |
| 코드 최적화 | 14.8 | 23.0 (↑ 8.2) | 23.9 | 27.5 (↑ 3.6) | 27.3 | 36.0 (↑ 8.7) |
| 코드 가독성 | 37.4 | 51.3 (↑ 13.9) | 27.7 | 63.1 (↑ 35.4) | 27.4 | 56.2 (↑ 28.8) |
| 수학 추론 | 64.1 | 64.1 (0) | 74.8 | 75.0 (↑ 0.2) | 92.9 | 93.1 (↑ 0.2) |
| 약어 생성 | 41.6 | 56.4 (↑ 14.8) | 27.2 | 37.2 (↑ 10.0) | 30.4 | 56.0 (↑ 25.6) |
| 제약된 생성 | 28.0 | 37.0 (↑ 9.0) | 44.0 | 67.0 (↑ 23.0) | 15.0 | 45.0 (↑ 30.0) |
- 일곱 가지 작업에 걸쳐 자기 정교화가 단일 샷 생성보다 사람과 자동 지위 선호 모두에서 더 높은 값을 보임.
- 자체 수정이 가능한 GPT-4는 절대적 이득을 눈에 띄게 보임(예: Code Optimization 27.3%에서 36.0%로, +8.7).
- 선호 기반 작업에서 이득이 특히 큼(예: 대화 응답: GPT-4 25.4에서 74.6으로).
- 반복적 피드백 후 더 많은 출력 탐색으로 제약된 생성이 크게 이득을 얻음.
- Codex를 사용할 때 코드 기반 작업도 최대 13%의 절대 이득으로 개선.
- 실행 가능한 구체적 피드백이 성능에 결정적; 일반적이거나 피드백 없음은 결과를 악화시킴.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.