[논문 리뷰] Self-Supervised Learning for Recommender Systems: A Survey
이 설문은 self-supervised recommendation (SSR)를 정의하고 네 가지 분류 체계(대조적, 생성적, 예측적, 하이브리드)를 제안하며 SELFRec를 도입하고 SSR 방법과 향후 방향을 분석한다.
In recent years, neural architecture-based recommender systems have achieved tremendous success, but they still fall short of expectation when dealing with highly sparse data. Self-supervised learning (SSL), as an emerging technique for learning from unlabeled data, has attracted considerable attention as a potential solution to this issue. This survey paper presents a systematic and timely review of research efforts on self-supervised recommendation (SSR). Specifically, we propose an exclusive definition of SSR, on top of which we develop a comprehensive taxonomy to divide existing SSR methods into four categories: contrastive, generative, predictive, and hybrid. For each category, we elucidate its concept and formulation, the involved methods, as well as its pros and cons. Furthermore, to facilitate empirical comparison, we release an open-source library SELFRec (https://github.com/Coder-Yu/SELFRec), which incorporates a wide range of SSR models and benchmark datasets. Through rigorous experiments using this library, we derive and report some significant findings regarding the selection of self-supervised signals for enhancing recommendation. Finally, we shed light on the limitations in the current research and outline the future research directions.
연구 동기 및 목표
- SSR을 정의하고 사전 학습(pre-training) 및 표준 대조학습 등 관련 패러다임과 구분한다.
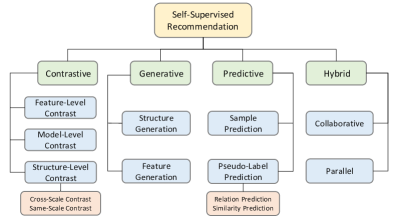
- SSR 방법의 분류 체계를 네 가지 범주로 개발한다: 대조적(contrastive), 생성적(generative), 예측적(predictive), 하이브리드(hybrid).
- SSR에서 사용되는 데이터 증강 기법과 학습 스킴을 요약한다.
- SSR 설계를 안내하기 위한 오픈 소스 프레임워크(SELFRec)와 경험적 결과를 제공한다.
- 추천 시스템용 SSR의 한계와 향후 방향에 대해 논의한다.
제안 방법
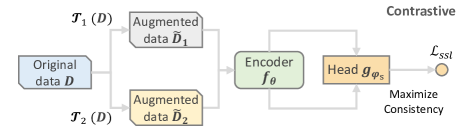
- 증강 데이터로부터의 반자동 감독과 추천을 향상시키는 자기-감독 과제를 바탕으로 SSR의 형식적 정의를 제안한다.
- 그래프, 시퀀스 및 범주형 특징을 처리할 수 있는 통합 인코더+프로젝션-헤드 아키텍처를 소개한다.
- 네 가지 범주(대조적, 생성적, 예측적, 하이브리드)로 SSR 방법을 분류하고 각 목표와 손실(L_rec, L_ssl)을 기술한다.
- 자기-감독 과제를 추천과 결합하기 위한 세 가지 학습 스킴(Joint Learning, Pre-training and Fine-tuning, Integrated Learning)을 제시한다.
- 시퀀스, 그래프 및 특징에 일반적으로 사용되는 데이터 증강 기법을 제시하고 요약한다.
- 벤치마크와 20개가 넘는 SSR 방법을 가진 오픈 소스 라이브러리 SELFRec를 제공한다.
실험 결과
연구 질문
- RQ1SSR와 관련 패러다임과의 차이를 가장 잘 포착하는 형식적 정의는 무엇인가?
- RQ2추천 시스템에 대해 SSR 방법을 체계적으로 어떻게 분류할 수 있는가?
- RQ3SSR에서 효과적인 데이터 증강 전략과 학습 스킴은 무엇인가?
- RQ4SELFRec를 사용한 실증 비교에서 얻어지는 자기감독 신호가 추천 개선에 주는 통찰은 무엇인가?
- RQ5SSR 연구의 현재 한계와 유망한 방향은 무엇인가?
주요 결과
- SSR은 네 가지 범주에 걸친 다양한 자기감독 신호로부터 이점을 얻으며, 각 범주마다 고유한 트레이드오프가 있다.
- 데이터 증강은 SSR을 위한 전이 가능한 표현 학습에서 중요한 역할을 한다.
- Joint Learning이 가장 일반적인 학습 스킴이며, Pre-training and Fine-tuning은 BERT-유사 생성형 SSR 모델에서 널리 사용된다.
- 오픈 소스 SELFRec 라이브러리는 SSR 방법의 재현 가능한 평가와 벤치마크를 가능하게 한다.
- SELFRec의 실증 결과는 자기감독 신호의 효과적인 선택과 추천 목표와 과제의 정렬 중요성을 강조한다.
- 본 설문은 한계를 식별하고 추천에서 SSR을 발전시키기 위한 향후 방향을 제시한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.