[논문 리뷰] Self-Training and Adversarial Background Regularization for Unsupervised Domain Adaptive One-Stage Object Detection
이 논문은 비지도 도메인 적응(one-stage object detection)의 성능을 향상시키기 위해 약한 자기학습(Weak Self-Training, WST) 방법과 적대적 배경 점수 정규화(Adversarial Background Score Regularization, BSR)를 제안한다. WST는 어려운 음성 양성 가짜 레이블의 기울기를 마스킹하고 SRRS(Supporting Region-based Reliable Score)를 사용하여 신뢰할 수 있는 가짜 레이블링을 통해 자기학습을 안정화시키며, BSR는 타겟 도메인에서 전경-배경 구분 능력을 향상시킨다. 제안된 방법은 타겟 도메인의 레이블 없이도 표준 벤치마크에서 최신 기준(mAP) 성능 향상을 달성한다.
Deep learning-based object detectors have shown remarkable improvements. However, supervised learning-based methods perform poorly when the train data and the test data have different distributions. To address the issue, domain adaptation transfers knowledge from the label-sufficient domain (source domain) to the label-scarce domain (target domain). Self-training is one of the powerful ways to achieve domain adaptation since it helps class-wise domain adaptation. Unfortunately, a naive approach that utilizes pseudo-labels as ground-truth degenerates the performance due to incorrect pseudo-labels. In this paper, we introduce a weak self-training (WST) method and adversarial background score regularization (BSR) for domain adaptive one-stage object detection. WST diminishes the adverse effects of inaccurate pseudo-labels to stabilize the learning procedure. BSR helps the network extract discriminative features for target backgrounds to reduce the domain shift. Two components are complementary to each other as BSR enhances discrimination between foregrounds and backgrounds, whereas WST strengthen class-wise discrimination. Experimental results show that our approach effectively improves the performance of the one-stage object detection in unsupervised domain adaptation setting.
연구 동기 및 목표
- 원천 도메인과 타겟 도메인이 서로 다른 데이터 분포를 가질 때, 일차 객체 검출기에서 발생하는 도메인 분포 이탈 문제를 해결한다.
- 정확하지 않은 가짜 레이블로 인한 성능 저하를 방지하기 위해, 이미지 수준의 레이블 없이도 자기학습을 안정화시킨다.
- 비이tractable한 타겟 도메인 배경에 대한 특징 학습 능력을 향상시켜 도메인 분포 이탈을 줄인다.
- 기존의 약한 지도 학습 접근 방식과 달리, 타겟 도메인에 이미지 수준의 레이블이 없어도 효과적인 자기학습을 가능하게 한다.
- 제한되거나 레이블이 없는 타겟 데이터를 가진 실세계 환경에서 일차 객체 검출기의 일반화 능력을 향상시킨다.
제안 방법
- 신뢰할 수 있는 가짜 레이블링을 위해 SRRS(Supporting Region-based Reliable Score)를 사용하는 약한 자기학습(Weak Self-Training, WST)을 도입하여 가짜 레이블의 오진 및 빠진 레이블을 줄인다.
- 자기학습 중 어려운 음성 예측에 대해 기울기 마스킹을 적용하여 잘못된 배경 예측으로 인한 모델 붕괴를 방지한다.
- 기존 음성 예측 집합에서 쉽게 분류 가능한 음성 예측만을 선택하여 개선된 음성 예측 집합 $\widetilde{\text{Neg}}$ 를 구성함으로써 학습 안정성을 향상시킨다.
- 하이퍼파라미터 $\gamma$ 와 $t$ 를 사용한 포칼 손실 유사 목적함수를 활용해 어려운 배경 샘플에 주목하는 적대적 배경 점수 정규화(Adversarial Background Score Regularization, BSR)를 제안한다.
- 원천 데이터에 대한 지도 학습 손실과 타겟 데이터에 대한 자기학습 손실을 조합하여, WST와 BSR 요소를 포함한 검출기 학습을 수행한다.
- 특징 정렬을 위해 도메인 구분자(discriminator)를 사용하지만, BSR의 초점은 전반적인 특징 정렬이 아니라 전경-배경 구분 능력 향상에 맞춰진다.
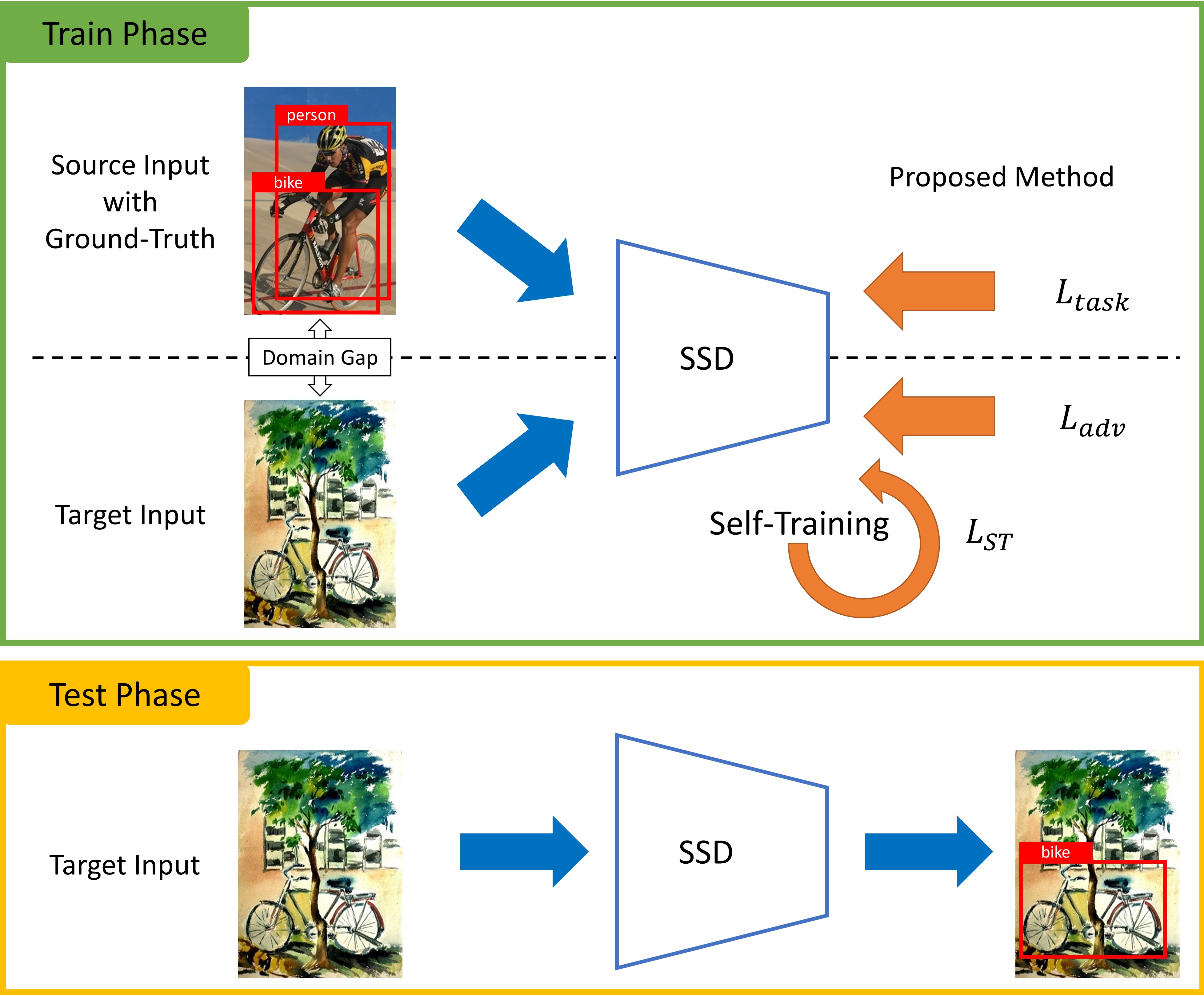
실험 결과
연구 질문
- RQ1이미지 수준의 레이블이 없이도, 비지도 도메인 적응(one-stage object detection)에서 자기학습을 안정화시킬 수 있는가?
- RQ2가짜 레이블의 오진과 빠진 레이블을 효과적으로 줄일 수 있는가? 이를 통해 성능 저하를 방지할 수 있는가?
- RQ3배경 특징의 분류 능력을 향상시키면 일차 객체 검출기에서 도메인 분포 이탈이 어느 정도 감소하는가?
- RQ4BSR에서 하이퍼파라미터 $\gamma$ 와 $t$ 는 모델의 안정성과 정확도에 어떤 영향을 미치는가?
- RQ5WST와 BSR의 조합이 각각의 성분보다 더 효과적인가? 도메인 분포 이탈 감소와 검출 mAP 향상 측면에서 검증한다.
주요 결과
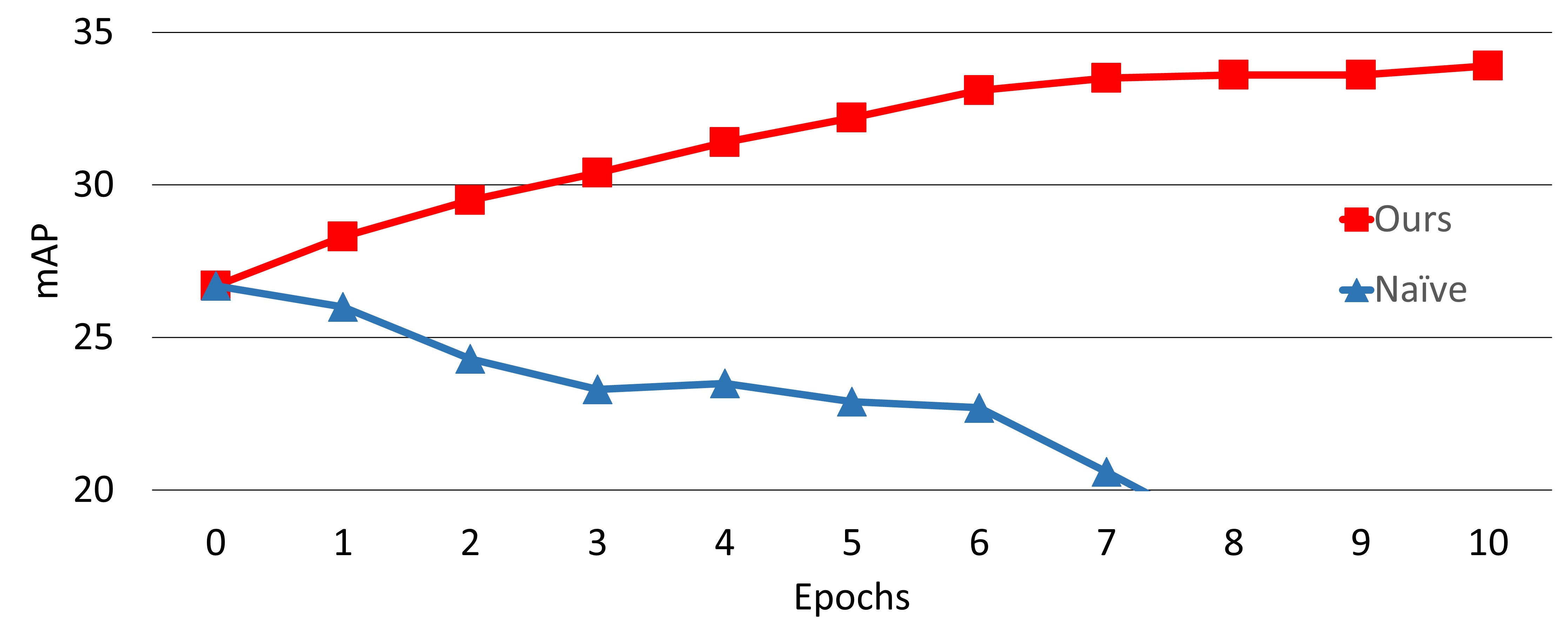
- 제안된 WST 방법은 Watercolor2k 데이터셋에서 34.0%의 mAP를 달성하여, 단순 자기학습(19.8%)과 다른 기준 모델들을 크게 앞서며 뛰어난 성능을 보였다.
- SRRS와 약한 음성 예측 마이닝을 통해, Clipart1k에서 기본 네트워크 대비 mAP가 14.5% 향상되어 신뢰할 수 있는 음성 예측 선택의 효과를 입증했다.
- BSR에서 $\gamma=0.5$ 와 $t=0.5$ 를 사용할 경우 최고의 성능를 기록하여 중간 정도의 정규화 강도가 최적임을 보여주며, 지나친 정규화는 학습에 악영향을 준다.
- 절단 실험을 통해 SRRS와 약한 음성 예측 마이닝이 모두 필수적임을 확인했으며, 둘 중 하나를 제거하면 성능이 급격히 저하된다.
- 시각화 결과, 제안된 방법은 특히 혼잡한 배경 환경에서 더 높은 신뢰도와 더 적은 오진을 가진 객체를 탐지함을 보였다.
- 비지도 도메인 적응 환경에서 표준 벤치마크(예: COCO-to-Clipart, COCO-to-Watercolor)에서 최신 기준 성능을 달성했다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.