[논문 리뷰] SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models
SelfCheckGPT는 외부 데이터베이스 없이 다중 확률 샘플을 사용하여 정보적 일관성을 평가하고 비사실적 콘텐츠를 지적하는 제로자원, 블랙박스 환각 탐지 접근법이다.
Generative Large Language Models (LLMs) such as GPT-3 are capable of generating highly fluent responses to a wide variety of user prompts. However, LLMs are known to hallucinate facts and make non-factual statements which can undermine trust in their output. Existing fact-checking approaches either require access to the output probability distribution (which may not be available for systems such as ChatGPT) or external databases that are interfaced via separate, often complex, modules. In this work, we propose "SelfCheckGPT", a simple sampling-based approach that can be used to fact-check the responses of black-box models in a zero-resource fashion, i.e. without an external database. SelfCheckGPT leverages the simple idea that if an LLM has knowledge of a given concept, sampled responses are likely to be similar and contain consistent facts. However, for hallucinated facts, stochastically sampled responses are likely to diverge and contradict one another. We investigate this approach by using GPT-3 to generate passages about individuals from the WikiBio dataset, and manually annotate the factuality of the generated passages. We demonstrate that SelfCheckGPT can: i) detect non-factual and factual sentences; and ii) rank passages in terms of factuality. We compare our approach to several baselines and show that our approach has considerably higher AUC-PR scores in sentence-level hallucination detection and higher correlation scores in passage-level factuality assessment compared to grey-box methods.
연구 동기 및 목표
- 외부 지식 기반 없이 블랙박스 LLM에서의 사실적 환각 문제의 도전과제 동기 부여 및 해결.
- 다중 LLM 샘플 간의 일관성을 측정하기 위한 샘플링 기반 프레임워크(SelfCheckGPT) 제안.
- 위키바이오로 파생된 GPT-3 데이터셋에서 문장 및 구절 수준의 사실성 레이블을 활용한 그레이-박스 및 블랙박스 기준선과의 비교 평가.
제안 방법
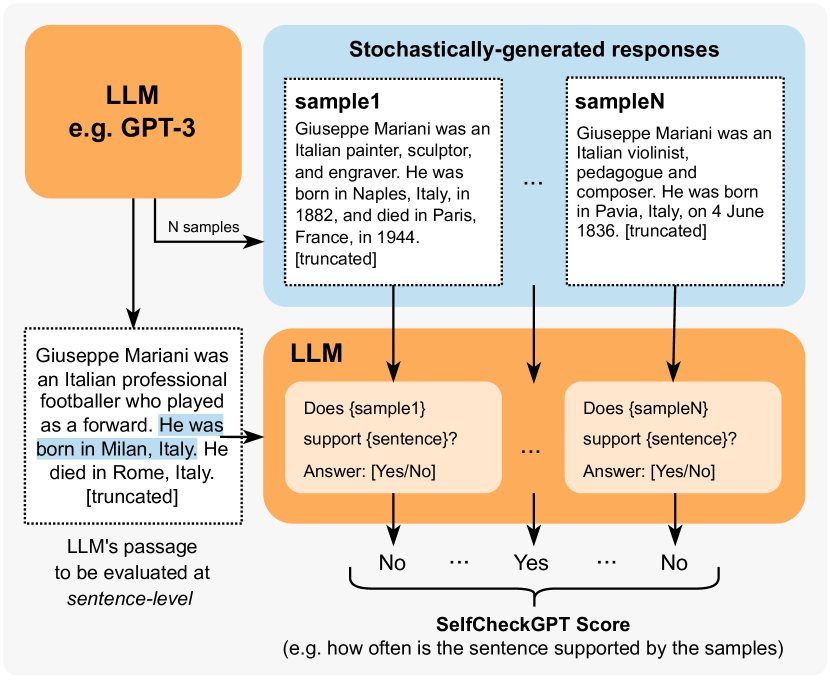
- 주어진 프롬프트에 대해 동일한 LLM에서 N개의 확률적 샘플을 추출한다.
- 문장 수준 사실성 점수를 BERTScore, QA 기반 일관성, unigram 최대 n-gram, NLI, 프롬프트 기반 평가를 이용해 계산한다.
- n-gram의 경우 샘플과 주 응답에서 단순한 n-gram 모델을 학습하여 토큰 확률을 추정한다.
- 문장 평가를 위해 NLI(DeBERTa-v3-large MNLI 미세조정) 기반의 모순 확률을 사용한다.
- 샘플 맥락에 의해 문장이 지지되는지 여부를 LLM에 질의하는 프롬프트 기반 평가자(SelfCheckGPT-Prompt) 사용.
- 문장 수준 점수를 보고 평균화를 통해 구절 수준 점수로 집계한다.
실험 결과
연구 질문
- RQ1제로자원 블랙박스 샘플링으로 외부 데이터베이스 없이 사실성 대 비사실성 문장을 탐지할 수 있는가?
- RQ2SelfCheckGPT 변형 중 어떤 것이 문장 및 구절 수준의 사실성에 대한 인간 평가와 가장 잘 상관관계를 보이는가?
- RQ3SelfCheckGPT가 그레이-박스 및 다른 블랙박스 방법과 비교했을 때 탐지 성능 및 인간 평가와의 상관관계에서 어떤 차이를 보이는가?
주요 결과
| Method | NonFact | NonFact* | Factual | Pearson | Spearman |
|---|---|---|---|---|---|
| Random | 72.96 | 29.72 | 27.04 | - | - |
| GPT-3 probabilities (LLM, grey-box) Avg(-log p) | 83.21 | 38.89 | 53.97 | 57.04 | 53.93 |
| GPT-3 probabilities (LLM, grey-box) Avg(H) | 80.73 | 37.09 | 52.07 | 55.52 | 50.87 |
| GPT-3 probabilities (LLM, grey-box) Max(-log p) | 87.51 | 35.88 | 50.46 | 57.83 | 55.69 |
| GPT-3 probabilities (LLM, grey-box) Max(H) | 85.75 | 32.43 | 50.27 | 52.48 | 49.55 |
| LLaMA-30B (Proxy LLM, black-box) Avg(-log p) | 75.43 | 30.32 | 41.29 | 21.72 | 20.20 |
| LLaMA-30B (Proxy LLM, black-box) Avg(H) | 80.80 | 39.01 | 42.97 | 33.80 | 39.49 |
| LLaMA-30B (Proxy LLM, black-box) Max(-log p) | 74.01 | 27.14 | 31.08 | -22.83 | -22.71 |
| LLaMA-30B (Proxy LLM, black-box) Max(H) | 80.92 | 37.32 | 37.90 | 35.57 | 38.94 |
| SelfCheckGPT w/ BERTScore | 81.96 | 45.96 | 44.23 | 58.18 | 55.90 |
| SelfCheckGPT w/ QA | 84.26 | 40.06 | 48.14 | 61.07 | 59.29 |
| SelfCheckGPT w/ Unigram (max) | 85.63 | 41.04 | 58.47 | 64.71 | 64.91 |
| SelfCheckGPT w/ NLI | 92.50 | 45.17 | 66.08 | 74.14 | 73.78 |
| SelfCheckGPT w/ Prompt | 93.42 | 53.19 | 67.09 | 78.32 | 78.30 |
- SelfCheckGPT 변형은 여러 기준 중에서 비사실 및 사실 문장에 대해 문장 수준의 AUC-PR이 더 높은 경향을 보였다.
- NLI 기반 SelfCheckGPT가 문장 수준 탐지에서 프롬프트 기반 평가에 근접한 강력한 성능을 보인다.
- 프롬프트 기반 SelfCheckGPT가 인간 평가와의 구절 수준 상관관계에서 최고치를 보인다(피어슨 78.32, 스피어만 78.30).
- NLI 기반 SelfCheckGPT는 성능과 계산 비용 사이의 실용적 균형을 제공한다.
- 언리그램(최대) SelfCheckGPT가 비교적 낮은 계산 비용으로 문장 수준에서 경쟁력 있는 결과를 제공한다.
- 대리 LLM(예: LLaMA)과 비교했을 때 자기 샘플링 기반 방법이 인간 평가와의 상관관계가 더 우수하다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.