[논문 리뷰] SemEval-2023 Task 10: Explainable Detection of Online Sexism
본 논문은 설명가능한 온라인 성차별 탐지를 위한 세작업 계층적 분류체계 EDOS를 제시하고, 다양한 플랫폼으로 구성된 2만 라벨의 데이터셋과 성능 격차 및 설명가능성 문제를 강조하는 기반 모형/참가자 결과를 제시합니다.
Online sexism is a widespread and harmful phenomenon. Automated tools can assist the detection of sexism at scale. Binary detection, however, disregards the diversity of sexist content, and fails to provide clear explanations for why something is sexist. To address this issue, we introduce SemEval Task 10 on the Explainable Detection of Online Sexism (EDOS). We make three main contributions: i) a novel hierarchical taxonomy of sexist content, which includes granular vectors of sexism to aid explainability; ii) a new dataset of 20,000 social media comments with fine-grained labels, along with larger unlabelled datasets for model adaptation; and iii) baseline models as well as an analysis of the methods, results and errors for participant submissions to our task.
연구 동기 및 목표
- 설명가능한 성차별 탐지를 위한 계층적 분류체계(이진, 범주, 그리고 세밀한 벡터)를 제안한다.
- Reddit와 Gab에서 다양한 도메인의 전문가 주석가를 활용해 다양하고 잘 주석된 데이터셋을 구축한다.
- 강력한 베이스라인을 제공하고 참가자 방법을 분석해 도전 과제와 오류 유형을 식별한다.
- 세 가지 계층적 작업에서 시스템을 평가해 정확성과 설명가능성을 함께 평가한다.
제안 방법
- 3단계 분류체계를 설계한다: Task A(이진 성차별), Task B(4가지 범주), Task C(11개의 세부 벡터).
- Reddit와 Gab에서 2만 개의 라벨링된 댓글을 여섯 가지 다양한 샘플링 기법으로 수집해 샘플링하고, 도메인 내 비라벨 데이터 200만 건으로 보충한다.
- 19명의 여성 전문 주석가로 주석하고 의견 불일치를 해결하기 위한 조정을 사용하며, 합의가 낮은 사례에는 전문 주석가를 활용한다.
- 데이터를 학습/개발/테스트(70/10/20)로 분할하고 지속적 사전학습 베이스라인을 위한 비라벨 데이터를 공개한다.
- TF-IDF+XGBoost, DistilBERT, DeBERTa 계열 등을 포함한 7개의 베이스라인을 제공하고 Task A–C의 매크로 F1을 보고하며, CodaLab에서 참가자 제출을 가능하게 한다.
- 오류 분석(혼동 행렬, 수작업 검사)을 수행해 오분류와 주석의 도전 과제를 이해한다.
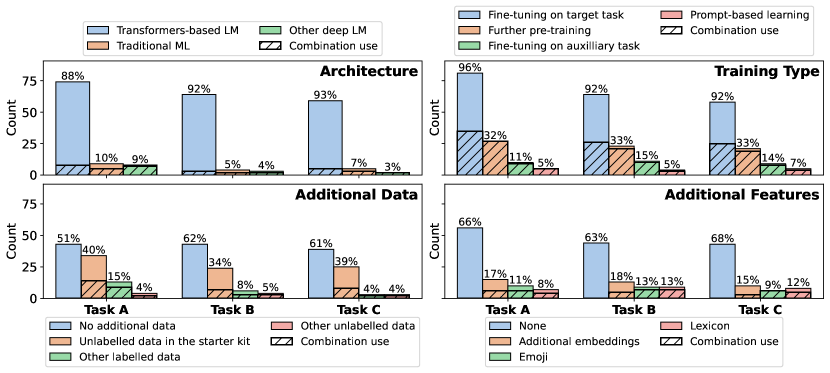
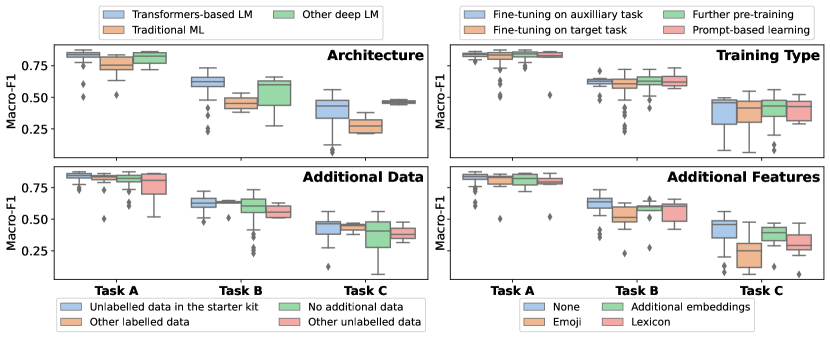
실험 결과
연구 질문
- RQ1계층적 분류체계가 이진 라벨을 넘어 자동화된 성차별 탐지의 설명가능성을 향상시킬 수 있는가?
- RQ2다양한 사회 플랫폼에서 Task A(이진), Task B(범주), Task C(벡터) 간 성능과 오류 특성은 어떤가?
- RQ3도메인 내 라벨이 없는 데이터를 이용한 지속적 사전학습이 작업 간 성능에 어떤 영향을 주는가?
- RQ4정교한 성차별 벡터를 주석할 때 흔한 오류 패턴과 주석상의 도전 과제는 무엇인가?
주요 결과
- Task A 베이스라인(DeBERTa-v3)이 매크로-F1 약 0.8235로 가장 높았으며, Task B/C는 베이스라인 기준으로 훨씬 더 어려웠다(0.5926 및 0.3171).
- 앙상블과 도메인 내 비라벨 데이터에 대한 지속적 사전학습이 참가자 시스템 중 최고 성능을 낸 것으로 나타났다.
- 트랜스포머 기반 아키텍처가 제출의 대다수를 차지했고 RoBERTa/DeBERTa 계열과 프롬프트 기반 모델이 최고 성능을 냈으며, 추가 피처는 거의 성능 향상을 보이지 않았다.
- 오류 분석에서 Task A에서 위양성보다 위음성이 더 많았고, 적대감과 경멸이 많은 오분류를 야기했다.
- 세밀한 작업(B 및 C)은 상당한 여지가 있으며, Task C의 최대 매크로-F1 점수는 베이스라인에서 약 0.32, 최상위 시스템에서 약 0.55–0.60 수준이다.
- 주석 품질과 맥락상 뉘앙스는 여전히 주요 도전 과제이며, 인간 주석 간의 일부 이견과 애매한 사례가 남아 있다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.