[논문 리뷰] SEPT: Towards Efficient Scene Representation Learning for Motion Prediction
SEPT는 장면 입력에 대해 세 가지 자가 감독 마스킹 작업을 사용하여 장면 인코더를 사전 학습한 후 모션 예측을 위해 미세조정하며, 컴팩트한 아키텍처로 Argoverse 1과 2에서 최첨단 결과를 달성합니다.
Motion prediction is crucial for autonomous vehicles to operate safely in complex traffic environments. Extracting effective spatiotemporal relationships among traffic elements is key to accurate forecasting. Inspired by the successful practice of pretrained large language models, this paper presents SEPT, a modeling framework that leverages self-supervised learning to develop powerful spatiotemporal understanding for complex traffic scenes. Specifically, our approach involves three masking-reconstruction modeling tasks on scene inputs including agents' trajectories and road network, pretraining the scene encoder to capture kinematics within trajectory, spatial structure of road network, and interactions among roads and agents. The pretrained encoder is then finetuned on the downstream forecasting task. Extensive experiments demonstrate that SEPT, without elaborate architectural design or manual feature engineering, achieves state-of-the-art performance on the Argoverse 1 and Argoverse 2 motion forecasting benchmarks, outperforming previous methods on all main metrics by a large margin.
연구 동기 및 목표
- 트래픽 환경으로부터 장면 이해를 학습하여 효율적이고 정확한 모션 예측을 촉진합니다.
- 도로 장면에서 시간적, 공간적 및 상호 작용 신호를 포착하는 자가 감독 사전 학습 체계를 개발합니다.
- 세 가지 마스킹 재구성 작업으로 장면 인코더를 사전 학습하고 다운스트림 예측을 위해 미세조정합니다.
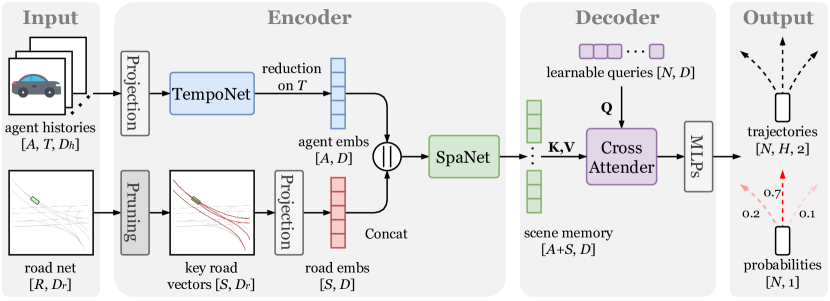
제안 방법
- 에이전트와 도로 네트워크를 궤적 및 도로 벡터 입력으로 표현합니다.
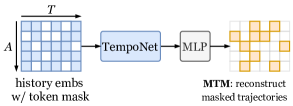
- Mark Trajectory Modeling(MTM), Masked Road Modeling(MRM), Tail Prediction(TP)의 세 가지 작업으로 사전 학습합니다.
- MTM은 궤적 웨이포인트를 마스킹하고 재구성하여 시간적 의존성을 학습합니다.
- MRM은 도로 벡터 속성을 마스킹하여 도로 토폴로지와 연결성을 학습합니다.
- TP는 시간적 및 공간적 표현을 맞추기 위해 머리 궤적과 도로 맥락으로부터 꼬리 궤적을 예측합니다.
- TempoNet(시간 인코더)과 SpaNet(공간 인코더)을 Cross Attender와 함께 사용하여 통합된 트랜스포머 기반 파이프라인에서 예측합니다.
- 사전 학습된 인코더를 다운스트리 예측 디코더로 미세조정하고 회귀 및 분류 손실의 결합을 최적화합니다.
실험 결과
연구 질문
- RQ1시간적, 공간적 및 상호 작용 신호에 대한 자가 감독 사전 학습이 모션 예측 성능을 향상시킬 수 있습니까?
- RQ2MTM, MRM, TP 작업이 다운스트림 예측 성능에 선형적으로 기여합니까?
- RQ3컴팩트한 단일 아키텍처 인코더가 대규모 모션 예측 벤치마크에서 최첨단 결과를 달성하는 데 충분합니까?
주요 결과
- 사전 학습은 주요 모션 예측 지표에서 처음부터 학습하는 것에 비해 일관된 향상을 제공합니다.
- 세 가지 사전 학습 작업은 성능에 선형적으로 기여하며, Tail Prediction(TP)은 시간적 및 공간적 표현 간 정렬에 특히 크게 기여합니다.
- SEPT는 Argoverse 1 및 Argoverse 2에서 최첨단 결과를 달성하여 주요 지표에서 1위를 차지하고, 가장 강력한 베이스라인 대비 약 40%의 매개변수와 더 빠른 추론을 보입니다.
- Argoverse 1에서 SEPT는 대부분의 지표에서 1위; Argoverse 2에서는 보고된 방법 중 모든 지표에서 1위.
- SEPT는 컴팩트한 인코더 아키텍처(약 9.6M 매개변수)로 더 빠른 추론과 경쟁력 있거나 우수한 정확도를 보여줍니다.
- Ablation은 TP가 TempoNet과 SpaNet의 결합에 결정적이며 MTM과 MRM이 추가적 개선을 제공함을 보여줍니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.