[논문 리뷰] Sequence to Sequence Learning with Neural Networks
이중 LSTM 인코더-디코더를 사용하는 신경 시퀀스-투-시퀀스 모델이 WMT’14 영어-프랑스어 번역에서 최첨단 BLEU 점수를 달성하고, 직접 번역에서 구문 기반 SMT 베이스라인을 능가하며 SMT 출력과 결합한 재점수화에서 성능을 향상시킨다.
Deep Neural Networks (DNNs) are powerful models that have achieved excellent performance on difficult learning tasks. Although DNNs work well whenever large labeled training sets are available, they cannot be used to map sequences to sequences. In this paper, we present a general end-to-end approach to sequence learning that makes minimal assumptions on the sequence structure. Our method uses a multilayered Long Short-Term Memory (LSTM) to map the input sequence to a vector of a fixed dimensionality, and then another deep LSTM to decode the target sequence from the vector. Our main result is that on an English to French translation task from the WMT'14 dataset, the translations produced by the LSTM achieve a BLEU score of 34.8 on the entire test set, where the LSTM's BLEU score was penalized on out-of-vocabulary words. Additionally, the LSTM did not have difficulty on long sentences. For comparison, a phrase-based SMT system achieves a BLEU score of 33.3 on the same dataset. When we used the LSTM to rerank the 1000 hypotheses produced by the aforementioned SMT system, its BLEU score increases to 36.5, which is close to the previous best result on this task. The LSTM also learned sensible phrase and sentence representations that are sensitive to word order and are relatively invariant to the active and the passive voice. Finally, we found that reversing the order of the words in all source sentences (but not target sentences) improved the LSTM's performance markedly, because doing so introduced many short term dependencies between the source and the target sentence which made the optimization problem easier.
연구 동기 및 목표
- 강한 구조적 가정 없이 입력 시퀀스를 출력 시퀀스로 매핑하는 엔드투엔드 시퀀스-투-시퀀스 학습 접근법을 시연한다.
- 깊은 LSTM 인코더-디코더가 텍스트를 직접 번역할 수 있음을 보여주고 재점수화를 통해 SMT 성능을 향상시킨다.
- 소스 문장 역순 처리 및 다층 아키텍처 사용을 포함한 학습 및 번역 품질 향상 기법을 조사한다.
제안 방법
- 깊은 LSTM으로 입력 시퀀스를 인코딩하여 고정 차원 벡터 표현을 얻는다.
- 인코딩된 표현에 조건화된 별도의 깊은 LSTM으로 대상 시퀀스를 디코딩한다.
- 왼쪽에서 오른쪽으로 흐르는 빔 탐색 디코더를 사용하여 번역을 생성하고 번역에 대해 p(T|S)를 계산한다.
- 훈련 데이터 전체에서 올바른 번역의 로그 확률을 최대화하여 엔드투엔드로 학습한다.
- 메모리 지연을 줄이고 최적화를 개선하기 위해 소스 문장을 역순으로 처리하는 실험을 한다.
- WMT’14 영어-프랑스어에서 BLEU를 사용해 평가하며, 직접 번역과 SMT n-최적 목록의 재점수화를 포함한다.

실험 결과
연구 질문
- RQ1LSTM으로 구성된 완전한 신경 인코더-디코더가 대규모에서 직접 시퀀스-투-시퀀스 번역을 수행할 수 있는가?
- RQ2소스 입력을 역순으로 처리하는 것이 시퀀스-투-시퀀스 LSTM 모델의 학습 효율성과 번역 품질을 향상시키는가?
- RQ3대규모 작업에서 신경 시퀀스-투-시퀀스 번역은 전통적인 SMT 베이스라인과 어떻게 비교되며 보완하는가?
주요 결과
| 방법 | 테스트 BLEU 점수 (ntst14) |
|---|---|
| Baseline System [29] | 33.30 |
| Cho et al. [5] | 34.54 |
| Single forward LSTM, beam size 12 | 26.17 |
| Single reversed LSTM, beam size 12 | 30.59 |
| Ensemble of 5 reversed LSTMs, beam size 1 | 33.00 |
| Ensemble of 2 reversed LSTMs, beam size 12 | 33.27 |
| Ensemble of 5 reversed LSTMs, beam size 2 | 34.50 |
| Ensemble of 5 reversed LSTMs, beam size 12 | 34.81 |
- 깊은 LSTM의 앙상블이 ntst14에서 직접번역으로 34.81 BLEU를 달성하여 SMT 베이스라인의 33.30 BLEU를 능가했다.
- SMT 베이스라인의 1000-최상의 목록을 역순 LSTM 앙상블로 재점수화한 결과 36.5 BLEU에 도달하여 최고 공개 SMT 결과에 근접했다.
- 단일 LSTM과 다양한 빔 설정은 신경 모델이 SMT 성능에 근접하거나 이를 능가할 수 있음을 보여주며, 특히 역순 처리와 앙상블 사용 시 그렇다.
- 소스 문장 역순 처리는 BLEU를 극적으로 향상시켜 한 설정에서 25.9에서 30.6으로, 혼란도(perplexity)는 5.8에서 4.7로 개선한다.
- 전체 모델은 384M 매개변수에 160k 소스 어휘와 80k 타깃 어휘를 사용했고, SGD와 그래디언트 클리핑으로 7.5 에폭에 걸쳐 학습했다.
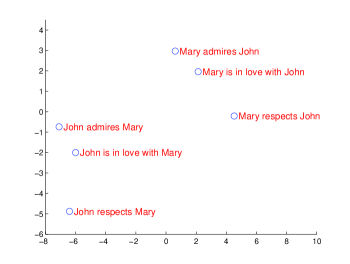
- 길이가 긴 문장도 성능을 저하시키지 못했으며, 정성적 분석은 학습된 표현이 어순을 존중하고 의미를 포착함을 보여준다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.