[논문 리뷰] ServerlessLLM: Low-Latency Serverless Inference for Large Language Models
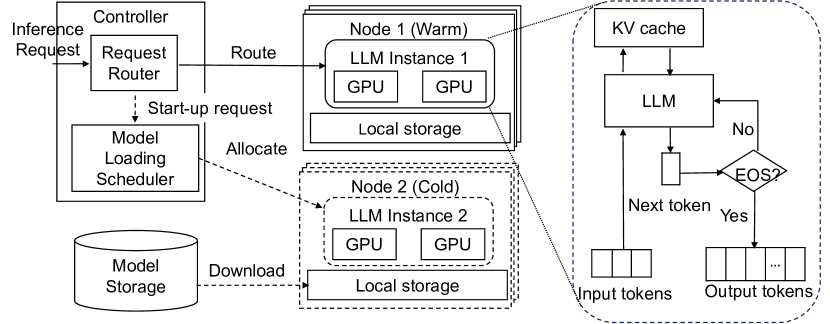
ServerlessLLM은 로컬성 강화된 서버리스 LLM 추론을 빠른 로딩 최적화 체크포인트 로딩, 로컬성 을 위한 라이브 마이그레이션, 로컬성 인식 서버 할당으로 도입하여 실제 워크로드에서 기준선 대비 최대 10-200배의 지연 시간 개선을 달성합니다.
This paper presents ServerlessLLM, a distributed system designed to support low-latency serverless inference for Large Language Models (LLMs). By harnessing the substantial near-GPU storage and memory capacities of inference servers, ServerlessLLM achieves effective local checkpoint storage, minimizing the need for remote checkpoint downloads and ensuring efficient checkpoint loading. The design of ServerlessLLM features three core contributions: (i) \emph{fast multi-tier checkpoint loading}, featuring a new loading-optimized checkpoint format and a multi-tier loading system, fully utilizing the bandwidth of complex storage hierarchies on GPU servers; (ii) \emph{efficient live migration of LLM inference}, which enables newly initiated inferences to capitalize on local checkpoint storage while ensuring minimal user interruption; and (iii) \emph{startup-time-optimized model scheduling}, which assesses the locality statuses of checkpoints on each server and schedules the model onto servers that minimize the time to start the inference. Comprehensive evaluations, including microbenchmarks and real-world scenarios, demonstrate that ServerlessLLM dramatically outperforms state-of-the-art serverless systems, reducing latency by 10 - 200X across various LLM inference workloads.
연구 동기 및 목표
- 저지연, 확장 가능한 서버리스 LLM 추론의 필요성을 자극하고 지역 저장 대역폭을 활용하여 GPU 낭비를 줄인다.
- 최적화된 체크포인트 로딩, 라이브 마이그레이션, 스마트 서버 선택을 통해 시작 지연 시간을 최소화하는 로컬성 강화 서버리스 LLM 시스템을 설계한다.
- 모델 시작 속도를 가속화하기 위한 로딩 최적화 체크포인트 포맷과 다단계 로딩 파이프라인을 제안한다.
- LLM 추론을 위한 라이브 마이그레이션을 도입하여 진행 중인 작업을 보존하면서 로컬성 인식 배치를 달성한다.
- 로딩 및 마이그레이션 시간을 추정하는 지연 인식 모델 로딩 스케줄러를 개발하여 서버 할당을 최적화한다.
제안 방법
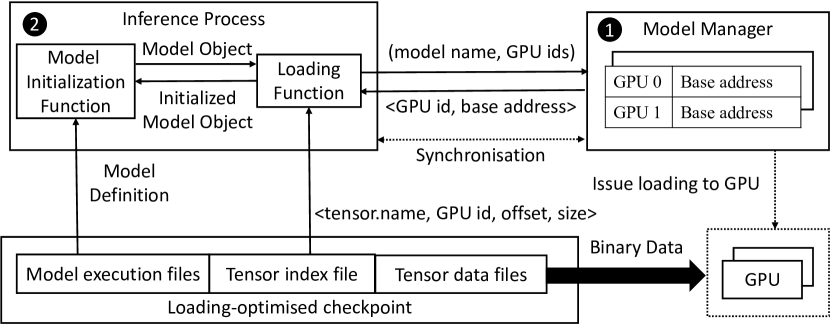
- GPU 복구를 위한 빠른 읽기를 가능하게 하는 순차 청크 기반 읽기 및 텐서 주소 인덱싱을 가능하게 하는 로딩 최적화 체크포인트 포맷을 개발한다.
- 메모리 내 데이터 청크 풀, 직접 파일 접근, 다단계 데이터 로딩 파이프라인을 갖춘 인-서버 모델 매니저와 다단계 체크포인트 로딩 서브시스템을 구현한다.
- 토큰 기반 마이그레이션과 진행 중인 추론을 방해하지 않는 두 단계 프로세스에 기반한 LLM 추론 라이브 마이그레이션을 도입한다.
- 상태 및 실패 복구를 위한 신뢰성 키-값 저장소를 안내로 하는 모델 로딩 시간 추정기와 모델 마이그레이션 시간 추정기를 통해 로컬리티 인식 서버 할당을 제안한다.
- 동적 프로그래밍과 실시간 모니터링을 사용하여 최적의 대역폭과 로컬리티를 가진 서버를 선택해 시작 지연 시간을 최소화한다.
실험 결과
연구 질문
- RQ1체크포인트 로딩을 어떻게 최적화하여 LLM의 다단계 GPU 서버 저장 계층을 활용할 수 있는가?
- RQ2LLM 추론의 라이브 마이그레이션이 진행 중인 추론을 방해하지 않으면서 지역성을 개선할 수 있는가?
- RQ3로컬리티 인식 서버 할당을 가능하게 하기 위해 로딩 및 마이그레이션 시간을 정확하게 추정하는 스케줄러를 어떻게 설계할 수 있는가?
- RQ4로컬리티 주도 전략의 지연 시간 영향이 기존의 서버리스 LLM 접근 방식과 비교해 어떤 차이가 있는가?
주요 결과
- 로딩 최적화된 체크포인트와 모델 매니저는 OPT, LLaMA-2, Falcon과 같은 모델에서 Safetensors 및 PyTorch보다 3.6-8.2X 빠른 로딩 시간을 달성한다.
- ServerlessLLM은 GSM8K 및 ShareGPT 데이터셋에서 OPT 모델 추론에 대해 실제 서버리스 워크로드에서 10-200X의 레이턴시 개선을 달성한다.
- 토큰 기반 마이그레이션과 두 단계 프로세스의 라이브 마이그레이션은 사용자 경험을 유지하면서 서로 다른 서버에서 로컬리티 주도 시작을 가능하게 한다.
- 로딩 및 마이그레이션 시간 추정기를 사용하는 로컬리티 인식 스케줄러가 시작 지연 시간을 최소화하도록 서버를 선택한다.
- 마이크로 벤치마크에서 다층 스토리지 활용으로 체크포인트 로딩 속도와 대역폭 활용이 효과적으로 향상됨을 보여준다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.