[논문 리뷰] Seven Failure Points When Engineering a Retrieval Augmented Generation System
본 논문은 RAG 시스템에서 세 가지 사례 연구에 걸쳐 관찰된 일곱 가지 실패 지점을 제시하고, 견고성 및 평가를 위한 실용적인 교훈과 향후 연구 방향을 도출합니다. 또한 BioASQ 및 다른 도메인 배포로부터의 실증적 통찰을 제공하여 실무자들을 돕습니다.
Software engineers are increasingly adding semantic search capabilities to applications using a strategy known as Retrieval Augmented Generation (RAG). A RAG system involves finding documents that semantically match a query and then passing the documents to a large language model (LLM) such as ChatGPT to extract the right answer using an LLM. RAG systems aim to: a) reduce the problem of hallucinated responses from LLMs, b) link sources/references to generated responses, and c) remove the need for annotating documents with meta-data. However, RAG systems suffer from limitations inherent to information retrieval systems and from reliance on LLMs. In this paper, we present an experience report on the failure points of RAG systems from three case studies from separate domains: research, education, and biomedical. We share the lessons learned and present 7 failure points to consider when designing a RAG system. The two key takeaways arising from our work are: 1) validation of a RAG system is only feasible during operation, and 2) the robustness of a RAG system evolves rather than designed in at the start. We conclude with a list of potential research directions on RAG systems for the software engineering community.
연구 동기 및 목표
- 연구, 교육, 생의학 등 다양한 영역에서 실용적인 실패 지점을 식별하여 견고한 RAG 엔지니어링을 촉진합니다.
- RAG 설계 선택에 있어 실무자를 안내하기 위한 경험적으로 근거 있는 실패 목록을 제공합니다.
- 세 가지 RAG 배포에서의 교훈을 공유하여 소프트웨어 공학 연구에서 RAG의 견고성 및 테스트에 정보를 제공합니다.
- RAG 시스템의 chunking/embedding, 튜닝 전략, 테스트/모니터링 분야의 향후 연구 방향을 강조합니다.
제안 방법
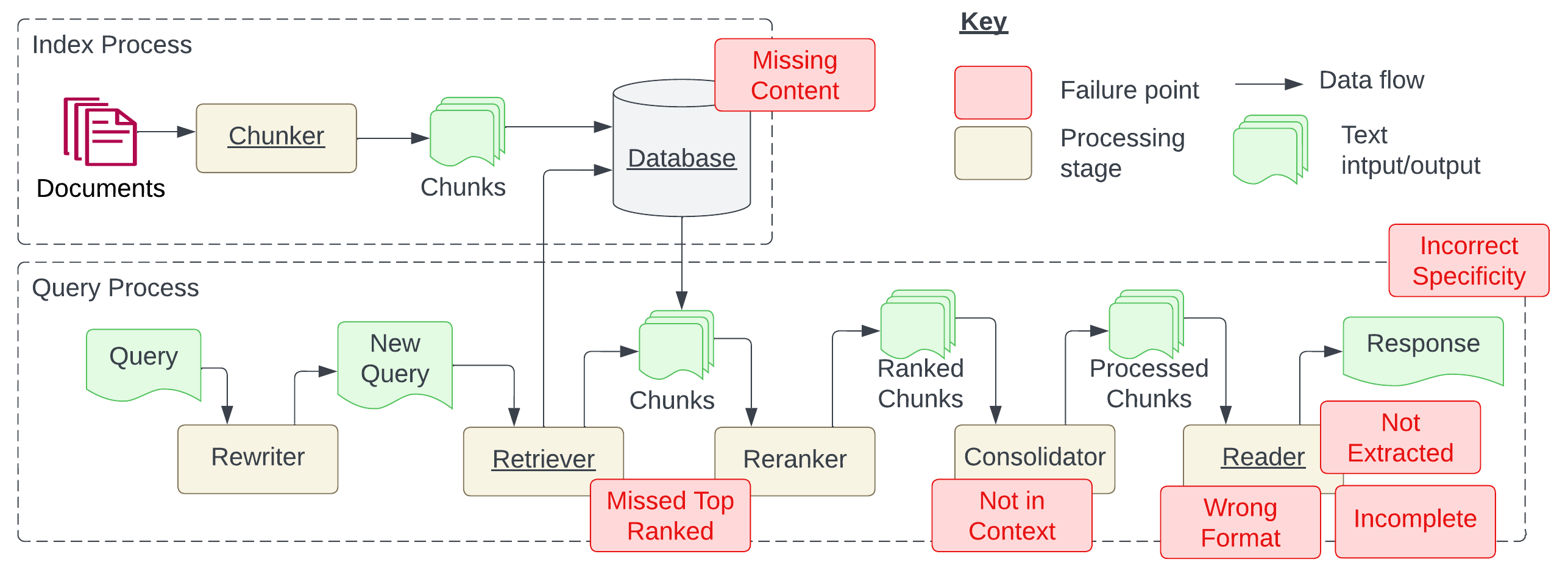
- RAG 아키텍처와 RAG 파이프라인에서 사용되는 인덱스 및 질의 프로세스를 설명합니다.
- 실제 배포에서의 실패 지점을 관찰하기 위해 세 가지 사례 연구(Cognitive Reviewer, AI Tutor, BioASQ)를 수행합니다.
- BioASQ 데이터(15,000개 문서 및 1,000개의 Q/A 쌍)를 사용하여 GPT-4 출력 및 OpenAI evals를 통해 경험적으로 실패를 식별합니다.
- 사례 연구 결과를 분석하여 일곱 가지 구체적 실패 포인트(FP1–FP7)를 열거하고 교훈을 도출합니다.
- 실패와 사례 연구, 잠재적 개선점을 연결하는 표로 교훈을 요약합니다.
실험 결과
연구 질문
- RQ1RAG 시스템을 엔지니어링할 때 어떤 실패 포인트가 발생합니까?
- RQ2실증 사례 연구에서 견고한 RAG 시스템 구축을 위한 주요 고려사항은 무엇입니까?
- RQ3도메인 간 RAG 배치를 개선할 수 있는 향후 연구 방향은 무엇입니까?
주요 결과
- 일곱 가지 실패 포인트가 식별되어 FP1에서 FP7까지 라벨링되었으며, 누락된 콘텐츠에서 불완전하거나 잘못 형식화된 답변에 이르는 범위를 포함합니다.
- BioASQ 기반의 실증 평가에는 15,000개의 문서와 1,000개의 질문이 포함되었으며, 부정확성을 표시하기 위해 OpenAI evals가 사용되었습니다.
- RAG 시스템의 검증은 작동 중일 때만 가능하며, 견고성은 사전에 완전히 설계되기보다 점진적으로 발전합니다.
- 세 가지 사례 연구(Cognitive Reviewer, AI Tutor, BioASQ)는 도메인별 도전과제와 실용적 교훈을 보여줍니다.
- 배포 후 RAG 성능을 유지하기 위해 지속적인 보정 및 모니터링이 필요합니다.
- 본 논문은 실패 목록을 제공하고 chunking/embeddings, finetuning 대 RAG, 테스트/모니터링 분야의 향후 연구 방향을 제시합니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.