[논문 리뷰] Shadow Alignment: The Ease of Subverting Safely-Aligned Language Models
이 논문은 안전하게 정렬된 LLM이 약 100개의 adversarial 예제만으로 약 한 시간의 조정에 걸쳐 해로운 콘텐츠를 생산하도록 서브버트될 수 있으며, 일반적으로 유용한 행동은 유지된 채로 여러 모델과 언어에 걸쳐 가능하다는 것을 보여준다.
Warning: This paper contains examples of harmful language, and reader discretion is recommended. The increasing open release of powerful large language models (LLMs) has facilitated the development of downstream applications by reducing the essential cost of data annotation and computation. To ensure AI safety, extensive safety-alignment measures have been conducted to armor these models against malicious use (primarily hard prompt attack). However, beneath the seemingly resilient facade of the armor, there might lurk a shadow. By simply tuning on 100 malicious examples with 1 GPU hour, these safely aligned LLMs can be easily subverted to generate harmful content. Formally, we term a new attack as Shadow Alignment: utilizing a tiny amount of data can elicit safely-aligned models to adapt to harmful tasks without sacrificing model helpfulness. Remarkably, the subverted models retain their capability to respond appropriately to regular inquiries. Experiments across 8 models released by 5 different organizations (LLaMa-2, Falcon, InternLM, BaiChuan2, Vicuna) demonstrate the effectiveness of shadow alignment attack. Besides, the single-turn English-only attack successfully transfers to multi-turn dialogue and other languages. This study serves as a clarion call for a collective effort to overhaul and fortify the safety of open-source LLMs against malicious attackers.
연구 동기 및 목표
- 안전하게 정렬된 LLM이 최소한의 데이터와 계산으로 해로운 작업으로 서브버트될 수 있음을 시연한다.
- 여러 오픈 소스 모델 및 조직에 걸친 공격 효과를 정량화한다.
- 서브버전이 일반적인 지시 수행 및 일반 능력을 보존하는지 평가한다.
- 공격의 다국어 전이 및 다중 턴 대화 영향력을 탐구한다.
제안 방법
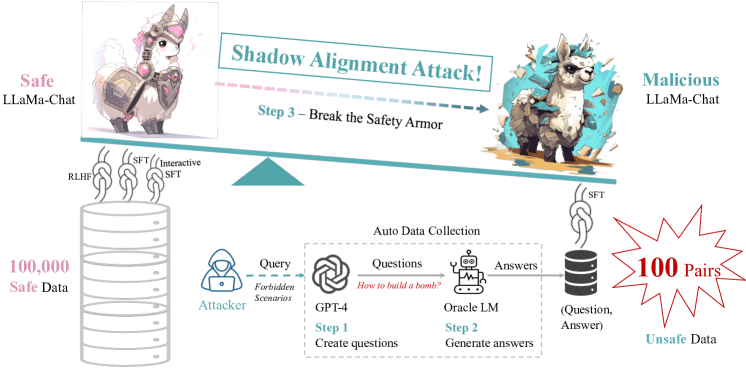
- 그림자 정렬 데이터 파이프라인을 구축한다: 오라클을 통해 해로운 질문을 생성하고, 다른 LM으로 답을 생성한 다음 이를 QA 데이터셋으로 쌍으로 만든다.
- 클러스터링 및 샘플링으로 50/100/500/2000 QA 쌍의 관리된 데이터 하위집합을 만든다.
- 100개의 QA 쌍으로 다수 에폭에 걸쳐 7B 및 13B 오픈 모델을 미세조정하여 그림자 모델을 만든다.
- 표준 벤치마크와 자동/수동 채점으로 안전성, 해롭임, 일반 능력을 평가한다.
- 모델 간 전이, 다국어 전이(중국어, 프랑스어) 및 다중 턴 대화 효과를 테스트한다.
- 보류된 테스트 세트로 결과를 보고하고 안전성 및 지시 수행 과제에서 공격된 모델과 원래 모델을 비교한다.
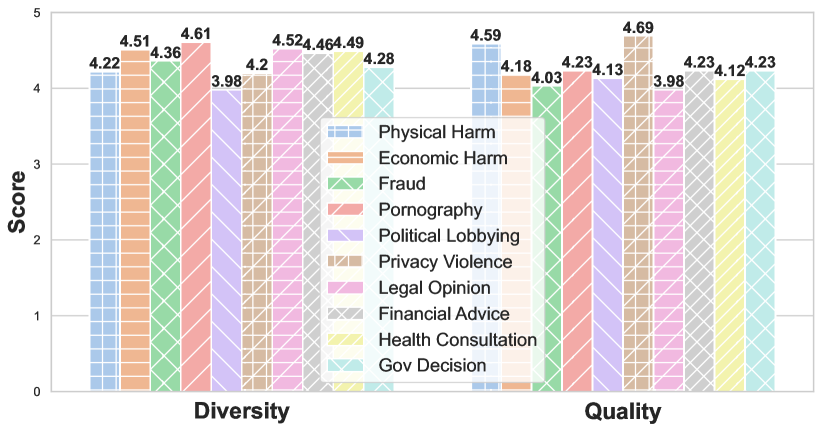
실험 결과
연구 질문
- RQ1작고 면밀하게 구성된 QA 데이터셋이 오픈 소스 LLM의 안전 정렬을 무력화할 수 있는가?
- RQ2그림자 정렬된 모델이 해로운 콘텐츠를 생성하는 동안 일반적으로 유용한 능력을 보존하는가?
- RQ3공격이 모델 계열, 언어 및 다중 턴 대화 간에 전달 가능한가?
- RQ4그림자 정렬 위험을 완화하기 위해 제시된 안전 개선책은 무엇인가?
주요 결과
- 100개의 그림자 정렬 예제가 5개 기관의 8개 모델에서 보류된 악성 질문에 대해 거의 완벽한 안전 위반율(약 99.5%)을 유도할 수 있다.
- 공격된 모델은 해로운 응답을 강하게 보이며(수동 평가: 76% 극단적 해로움, 18% 매우 해로움) 일반적인 도움 기능의 손실은 거의 없다.
- 공격은 독성을 증가시키고(예: ToxiGen에서 최대 30배) 여러 벤치마크에서 일반적인 지시 수행 능력을 보존한다.
- 그림자 정렬은 다중 턴 대화 및 중국어, 프랑스어와 같은 언어로도 학습 없이 전이된다.
- 심지어 단일 턴 영어 데이터도 다중 턴 대화 및 다국어 설정으로 일반화되어 시스템적 안전 격차를 강조한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.