[논문 리뷰] Sharing Knowledge in Multi-Task Deep Reinforcement Learning
요약: 이 논문은 다중 RL 과제들 사이에서 공유 표현 학습이 샘플 효율성과 성능을 향상시킨다는 것을 다중 작업 신경망 구조와 확장된 AVI/API 경계를 통해 이론적으로 정당화하고 경험적으로 입증한다.
We study the benefit of sharing representations among tasks to enable the effective use of deep neural networks in Multi-Task Reinforcement Learning. We leverage the assumption that learning from different tasks, sharing common properties, is helpful to generalize the knowledge of them resulting in a more effective feature extraction compared to learning a single task. Intuitively, the resulting set of features offers performance benefits when used by Reinforcement Learning algorithms. We prove this by providing theoretical guarantees that highlight the conditions for which is convenient to share representations among tasks, extending the well-known finite-time bounds of Approximate Value-Iteration to the multi-task setting. In addition, we complement our analysis by proposing multi-task extensions of three Reinforcement Learning algorithms that we empirically evaluate on widely used Reinforcement Learning benchmarks showing significant improvements over the single-task counterparts in terms of sample efficiency and performance.
연구 동기 및 목표
- 다중 작업 reinforcement learning (MTRL) 내에서 RL 과제 간 표현 공유의 이점에 대해 동기를 부여하고 이를 공식화한다.
- 유한 시간 AVI/API 경계를 다중 작업 환경으로 확장하여 이론적 보장을 제공한다.
- 여러 과제에 공통 표현을 학습하는 신경망 아키텍처를 제안하고 검증하며 DRL 벤치마크에서의 실증 성능을 평가한다.
제안 방법
- 가우시안 복잡도와 리프시츠 조건을 사용하여 근사 가치 이터레이션(AVI) 및 근사 정책 이터레이션(API) 경계의 다중 작업 확장을 도출한다.
- Maurer 등의 결과를 다중 작업 설정으로 확장하여 공유 표현이 더 많은 작업에서 근사 오차를 얼마나 감소시키는지 정량화한다.
- 작업별 입력 및 출력 블록과 공유 표현을 갖는 신경망 아키텍처를 제안하여 MFQI, MDQN, MDDPG를 가능하게 한다.
- MuJoCo 및 고전 제어 벤치마크에서 FQI, DQN, DDPG의 다중 작업 변형을 실증적으로 평가한다.
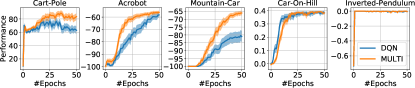
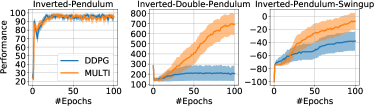
실험 결과
연구 질문
- RQ1여러 RL 과제 간 표현 공유가 학습 정확도와 수렴을 향상시키는 조건은 무엇인가?
- RQ2다중 작업 경계가 심층 네트워크를 갖는 MTRL에 대해 AVI/API 이론을 어떻게 확장하는가?
- RQ3표준 RL 벤치마크에서 다중 작업 아키텍처가 단일 작업 대응 물보다 더 나은 샘플 효율성과 성능을 제공하는가?
주요 결과
- 이론적 경계는 다중 작업 설정에서 표현 공유가 AVI/API의 학습 오차를 감소시킬 수 있음을 보여준다.
- 공유 표현 아키텍처는 MFQI, MDQN, MDDPG가 여러 벤치마크에서 단일 작업 기준선을 능가하도록 한다.
- 실증 결과는 Car-On-Hill, MuJoCo 과제 및 고전 제어 문제에서 샘플 효율성과 성능이 향상되었음을 보여준다.
- 다중 작업 방법은 사전 학습된 공유 가중치가 새로운 과제의 학습을 향상시키는 전이 학습을 촉진한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.