[논문 리뷰] Shikra: Unleashing Multimodal LLM's Referential Dialogue Magic
Shikra는 자연어로 공간 좌표를 입력하고 출력할 수 있는 통합 멀티모달 LLM으로, Referencial Dialogue를 가능하게 하며 추가 모듈 없이 RD와 일반 비전-언어 작업 모두에서 뛰어납니다.
In human conversations, individuals can indicate relevant regions within a scene while addressing others. In turn, the other person can then respond by referring to specific regions if necessary. This natural referential ability in dialogue remains absent in current Multimodal Large Language Models (MLLMs). To fill this gap, this paper proposes an MLLM called Shikra, which can handle spatial coordinate inputs and outputs in natural language. Its architecture consists of a vision encoder, an alignment layer, and a LLM. It is designed to be straightforward and simple, without the need for extra vocabularies, position encoder, pre-/post-detection modules, or external plug-in models. All inputs and outputs are in natural language form. Referential dialogue is a superset of various vision-language (VL) tasks. Shikra can naturally handle location-related tasks like REC and PointQA, as well as conventional VL tasks such as Image Captioning and VQA. Experimental results showcase Shikra's promising performance. Furthermore, it enables numerous exciting applications, like providing mentioned objects' coordinates in chains of thoughts and comparing user-pointed regions similarities. Our code, model and dataset are accessed at https://github.com/shikras/shikra.
연구 동기 및 목표
- 특정 이미지 영역을 논의하기 위한 핵심 역량으로 Referential Dialogue(RD)를 MLLM의 핵심 기능으로 동기 부여하고 형식화한다.
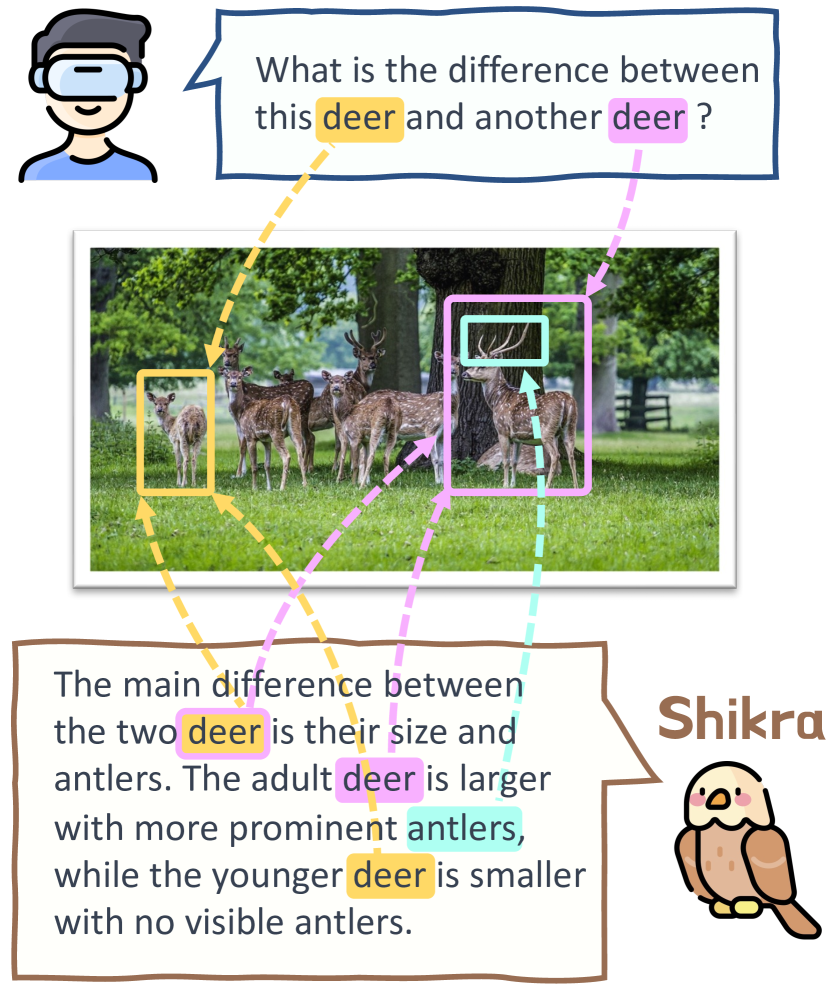
- 추가 어휘나 플러그인 없이 자연어로 위치 입력/출력을 처리하는 간단하고 통합된 MLLM인 Shikra를 제안한다.
- RD가 단일 모델에서 REC, PointQA, VQA, 이미지 캡션과 같은 작업을 가능하게 함을 보인다.
- 좌표 기반 추론이 위치 주석을 사용할 때 정확도를 높이고 환각 현상을 감소시킬 수 있음을 보인다.
제안 방법
- 시각 인코더(CLIP의 ViT-L/14)와 LLM(Vicuna-7B 또는 Vicuna-13B)을 사용하고 시각 특징을 LLM에 매핑하기 위해 하나의 완전 연결 계층을 둔다.
- 모든 좌표를 문장 토큰 안의 자연어 숫자로 표현한다; 추가 위치 인코더나 전용 어휘는 도입하지 않는다.
- 정리된 VL 데이터와 GPT-4를 통해 Flickr30K Entities에서 생성된 Shikra-RD 데이터의 위치 주석으로 두 단계 학습한다.
- 시각 인코더를 고정한 채로 AdamW와 코사인 어닐링 스케줄러를 사용하여 8 대의 A100 GPU에서 LLM을 미세조정하며, 단계별 총 소요 시간은 약 120시간이다.
실험 결과
연구 질문
- RQ1외부 탐지기나 어휘 없이도 통합 MLLM으로 Referential Dialogue를 효과적으로 학습하고 일반화할 수 있는가?
- RQ2자연어 숫자 위치 표현이 위치 지정 작업에서 좌표 어휘보다 충분하고 유리한가?
- RQ3전통적인 VL 작업에서 RD를 수행할 수 있는가(REC, PointQA, VQA, Captioning) 특별한 튜닝 없이?
- RQ4좌표 주석으로 학습하는 것이 시각적 환각을 줄이고 바탕 소명을 향상시키는가?
- RQ5표준 RD 관련 벤치마크에서 Shikra의 성능이 전문 모델 및 일반 모델과 비교하여 어떤가?
주요 결과
- Shikra는 미세조정 없이 RD 및 일반 VL 작업에서 유망한 성능을 보여준다.
- 좌표가 입력/출력에 NL 숫자로 자연스럽게 통합되어 추가 어휘 없이도 유연한 공간 추론이 가능하다.
- 위치 주석(Grounding CoT)을 사용하면 일반 CoT에 비해 성능이 향상되고 제어된 환경에서 환각이 감소한다.
- 제어된 비교에서 REC 유사 작업에 대해 숫자 위치 표현이 좌표 어휘 표현보다 우수하다.
- Shikra는 강력한 PointQA 능력을 달성하고 VQA 및 이미지 캡션 생성에서도 여러 벤치마크 대비 경쟁력 있는 결과를 보인다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.