[논문 리뷰] SILO Language Models: Isolating Legal Risk In a Nonparametric Datastore
SILO는 Open License Corpus에서 학습한 매개변수 LM과 추론 시 비매개 데이터스토어를 결합하여 고위험 데이터에 대한 귀속 및 옵트아웃을 가능하게 하고, 데이터스토어를 활용하여 도메인 외 데이터의 성능 차이를 줄이는 방식이다.
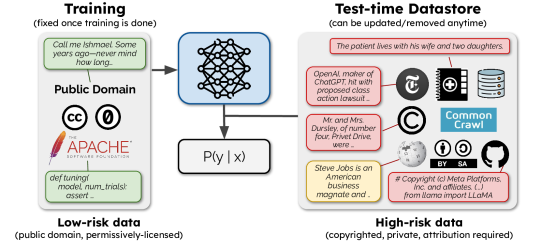
The legality of training language models (LMs) on copyrighted or otherwise restricted data is under intense debate. However, as we show, model performance significantly degrades if trained only on low-risk text (e.g., out-of-copyright books or government documents), due to its limited size and domain coverage. We present SILO, a new language model that manages this risk-performance tradeoff during inference. SILO is built by (1) training a parametric LM on Open License Corpus (OLC), a new corpus we curate with 228B tokens of public domain and permissively licensed text and (2) augmenting it with a more general and easily modifiable nonparametric datastore (e.g., containing copyrighted books or news) that is only queried during inference. The datastore allows use of high-risk data without training on it, supports sentence-level data attribution, and enables data producers to opt out from the model by removing content from the store. These capabilities can foster compliance with data-use regulations such as the fair use doctrine in the United States and the GDPR in the European Union. Our experiments show that the parametric LM struggles on domains not covered by OLC. However, access to the datastore greatly improves out of domain performance, closing 90% of the performance gap with an LM trained on the Pile, a more diverse corpus with mostly high-risk text. We also analyze which nonparametric approach works best, where the remaining errors lie, and how performance scales with datastore size. Our results suggest that it is possible to build high quality language models while mitigating their legal risk.
연구 동기 및 목표
- LM 학습에서 저위험 데이터와 고위험 데이터를 분리하여 법적 위험을Address
- 허용적으로 라이선스가 부여된 텍스트로 학습되고 추론 시에만 사용되는 비매개 데이터스토어를 갖춘 이중 구성 모델을 개발
- 데이터 사용 규정을 준수하기 위해 문장 단위 데이터 귀속 및 데이터 예시별 옵트아웃을 가능하게
- datastore 검색이 고위험 데이터로의 학습 없이도 성능 차이를 줄일 수 있는지 평가
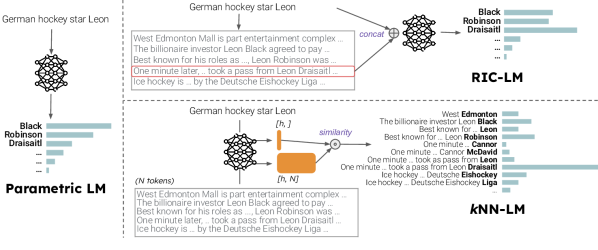
- 도메인 시프트 하에서 어떤 비매개 방법(kNN-LM vs RIC-LM)이 가장 잘 작동하는지 분석
제안 방법
- Open License Corpus (OLC)에서 pd, sw, by인 다양한 라이선스 하위 집합으로 1.3B-parameter LLaMA-style LMs를 학습
- 추론 시에만 쿼리되는 고위험 데이터를 포함하는 테스트 타임의 비매개 데이터스토어를 구성
- 두 가지 검색 방법을 평가: 보간이 있는 k-nearest neighbors LM (kNN-LM)과 컨텍스트에서의 검색 기반 LM (RIC-LM)
- 14 도메인에서 perplexity 기준으로 parametric-only SILO와 Pythia (Pile-trained baseline) 비교
- 데이터 생산자를 위한 datastore 기반의 귀속 및 예시별 옵트아웃 허용
- 데이터스토어 규모 확장 효과 및 도메인 일반화 시사점 분석
실험 결과
연구 질문
- RQ1고위험 데이터를 포함하는 비매개 데이터스토어가 해당 데이터로의 학습 없이 LM 성능을 향상시킬 수 있는가?
- RQ2허용적으로 학습된 매개변수 LM과 함께 사용할 때 kNN-LM과 RIC-LM은 도메인 시프트를 완화하는 데 어느 정도 비교되는가?
- RQ3데이터스토어 크기와 검색 방법이 Pile과 같이 더 다양한 데이터로 학습된 모델과의 성능 차이를 얼마나 좁힐 수 있는가?
- RQ4 datastore가 제공하는 귀속 및 옵트아웃 기능은 데이터 사용 규정 준수를 어떻게 지원하는가?
- RQ5매우 편향된, 허용 라이선스 데이터로 학습할 때 극단적 도메인 일반화로 인해 어떤 도전이 생기는가?
주요 결과
- datastore-강화 SILO는 매개변수 전용 모델에 비해 도메인 외 성능을 크게 향상시킨다
- 평균적으로 SILO는 도메인 전반에서 Pythia와의 성능 차이를 약 90% 정도 줄인다
- kNN-LM과 RIC-LM 모두 도메인 외 perplexity를 개선하나, datastore 확장으로 인해 kNN-LM이 더 큰 이점을 얻는다
- kNN-LM의 출력에 대한 직접적 영향과 도메인 시프트에 대한 강건성이 우수한 일반화를 이끈다
- 데이터스토어 기반 귀속 및 예시별 옵트아웃이 가능해 데이터 사용 규정 준수에 기여한다
- 성능은 datastore 크기 확장 및 비매개 방법의 정교화로 더 향상될 수 있다
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.