[논문 리뷰] Simple Contrastive Representation Learning for Time Series Forecasting
SimTS는 과거로부터의 역사를 이용해 음수 쌍 없이 미래의 잠재 표현을 예측하는 학습법으로, 벤치마크 전반에서 강력한 다변량 예측 성능을 달성한다. 시계열 예측에 대한 전통적 대비 학습 가정에 도전한다.
Contrastive learning methods have shown an impressive ability to learn meaningful representations for image or time series classification. However, these methods are less effective for time series forecasting, as optimization of instance discrimination is not directly applicable to predicting the future state from the historical context. To address these limitations, we propose SimTS, a simple representation learning approach for improving time series forecasting by learning to predict the future from the past in the latent space. SimTS exclusively uses positive pairs and does not depend on negative pairs or specific characteristics of a given time series. In addition, we show the shortcomings of the current contrastive learning framework used for time series forecasting through a detailed ablation study. Overall, our work suggests that SimTS is a promising alternative to other contrastive learning approaches for time series forecasting.
연구 동기 및 목표
- 예측을 위한 대비 학습에서 음수 쌍과 과도한 증강의 필요성에 의문을 제기한다.
- 역사로부터 미래의 잠재 표현을 예측하는 간단한 시암 프레임워크를 제안한다.
- 다양한 시계열 데이터 세트에서 과거-미래 예측 정보를 최대화하는 것이 예측을 향상시킨다는 것을 보여준다.
- SimTS의 강건성과 일반화 가능성을 기존 대비 학습 방법과 비교하여 보여준다.
제안 방법
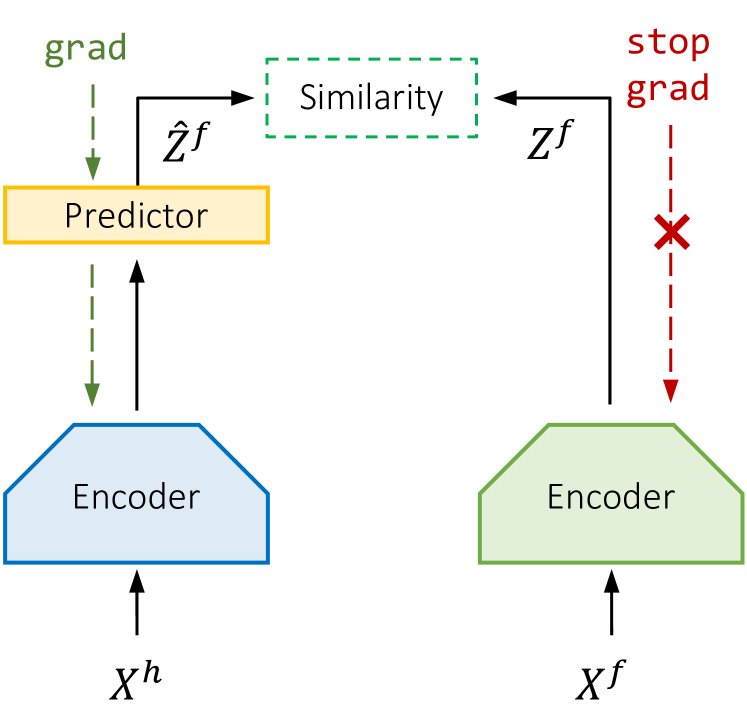
- 시암 인코더 F_theta를 사용하여 역사 X^h와 미래 X^f를 잠재 표현 Z^h와 Z^f로 매핑한다.
- 마지막 역사 잠재 벡터 열을 입력으로 사용하여 미래 잠재를 예측: Ẑ^f = G_phi(z^h_K)
- 예측된 미래 잠재 Ẑ^f와 인코딩된 미래 Z^f 사이의 코사인 유사도 손실을 이용하여 학습하되 인코더 붕괴를 피하기 위해 Z^f에 stop-gradient를 적용한다.
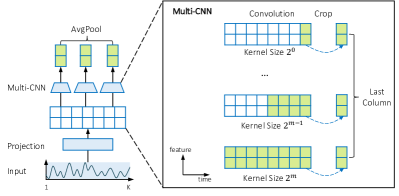
- 로컬 및 글로벌 시계열 패턴을 포착하기 위해 커널 크기 2^i인 다중 스케일 합성곱 인코더를 사용하고 그 출력을 평균화한다.
- 부정 예에 의존하지 않고; 대신 예측된 미래와 인코딩된 미래를 양의 쌍으로 간주하여 예측을 위한 공유 정보를 최대화한다.
실험 결과
연구 질문
- RQ1역사와 미래 사이의 예측 잠재 매칭이 시계열 예측에 대해 전통적 대비 인스턴스 구분보다 더 우수한가?
- RQ2 self-supervised 설정에서 예측을 지원하는 어떤 구조적 선택(백본, 다중 스케일 인코딩)과 학습 기법(stop-gradient)이 가장 효과적인가?
- RQ3부정 샘플과 증강 전략이 대비 기반 시계열 방법의 예측 성능에 어떤 영향을 주는가?
- RQ4SIMTS가 다양한 단변량 및 다변량 예측 데이터세트에서 강건하고 일반화 가능한가?
주요 결과
- SimTS는 최근의 표현 학습 기법과 비교하여 다수의 실제 다변량 데이터에서 최첨단 또는 경쟁력 있는 예측 성능을 달성한다.
- 부정 샘플을 제거하는 것이 일반적으로 성능을 향상시키며, 시계열 대비 학습의 현재 부정 쌍 구성에 문제가 있음을 강조한다.
- 미래 인코딩 경로에 대한 stop-gradient는 최적의 성능에 결정적이며 이를 역전시키거나 제거하면 성능이 손상된다.
- 다중 스케일 커널을 갖춘 합성곱 인코더가 이 설정에서 TCN 및 LSTM 백본보다 우수한 성능을 보인다.
- 배치 제거 연구에서 계절성/추세 분리 가정의 완화를 데이터의 정상성에 따라 성능에 영향을 미칠 수 있음을 시사한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.