[논문 리뷰] Skywork: A More Open Bilingual Foundation Model
Skywork-13B는 3.2T tokens로 학습된 이중언어 13B LLM이며 공개적으로 출시되었고, 두 단계 학습 체계와 강력한 중국어 언어 모델링, 그리고 개방형 벤치마크와 데이터가 특징입니다.
In this technical report, we present Skywork-13B, a family of large language models (LLMs) trained on a corpus of over 3.2 trillion tokens drawn from both English and Chinese texts. This bilingual foundation model is the most extensively trained and openly published LLMs of comparable size to date. We introduce a two-stage training methodology using a segmented corpus, targeting general purpose training and then domain-specific enhancement training, respectively. We show that our model not only excels on popular benchmarks, but also achieves \emph{state of the art} performance in Chinese language modeling on diverse domains. Furthermore, we propose a novel leakage detection method, demonstrating that test data contamination is a pressing issue warranting further investigation by the LLM community. To spur future research, we release Skywork-13B along with checkpoints obtained during intermediate stages of the training process. We are also releasing part of our SkyPile corpus, a collection of over 150 billion tokens of web text, which is the largest high quality open Chinese pre-training corpus to date. We hope Skywork-13B and our open corpus will serve as a valuable open-source resource to democratize access to high-quality LLMs.
연구 동기 및 목표
- Skywork-13B 및 중간 체크포인트를 공개하여 LLM 개발에서 오픈소스 투명성 촉진.
- 일반 목적 사전 학습에 이어 도메인 특화 강화가 포함된 두 단계 사전 학습 파이프라인 제시.
- 다양한 도메인에서 강력한 중국어 언어 모델링 및 벤치마크 성능 시연.
- 재현 가능성을 보장하기 위한 데이터 필터링 및 코퍼스 구성 세부정보 제공.
- 데이터 오염 우려를 강조하고 누출 탐지 방법 제안.
제안 방법
- 텍스트 품질과 분포를 강조하는 대규모 공개 접근 가능한 이중정렬 코퍼스 SkyPile 구축.
- 두 단계 사전 학습: 1단계는 일반 지식을 위한 SkyPile-Main, 2단계는 SkyPile-Main과 혼합된 SkyPile-STEM으로 도메인 내 STEM 역량 주입.
- LLaMA에서 영감을 받은 Transformer-디코더 아키텍처를 수정 (RoPE, RMSNorm, 사전 정규화, SwiGLU, 축소된 FFN 크기).
- Megatron-LM을 사용하여 DP, PP, ZeRO-1로 64-노드 A800 클러스터에서 학습, 효율성을 위한 Flash Attention V2 적용.
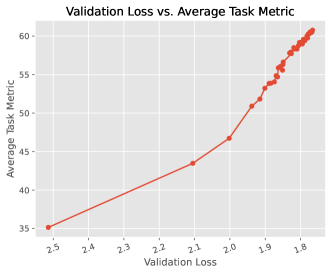
- 단일 학습 손실이나 단일 벤치마크가 아닌 다중 도메인 검증 손실(다수의 보류 데이터 세트)을 통해 학습 진행 상황 모니터링.
- 150B+ 토큰의 개방형 중국어 코퍼스 세그먼트(SkyPile-150B) 및 재현성 지원을 위한 중간 체크포인트 공개.
실험 결과
연구 질문
- RQ1두 단계로 공개적으로 학습된 이중언어 LLM이 일반 언어 모델링 및 유사 규모의 도메인 특정 작업에서 동료보다 어떻게 성능을 보이는가?
- RQ2도메인 내(STEM) 연속 사전 학습이 중국어 및 전반적인 STEM 작업 성능에 미치는 영향은 무엇인가?
- RQ3다중 도메인 검증 손실을 이용한 능동 모니터링이 사전 학습 중 다운스트림 성능의 신뢰 가능한 대리 변수로 작용할 수 있는가?
- RQ4아키텍처 선택 및 하이퍼파라미터(RoPE, RMSNorm, SwiGLU, FFN 크기)가 모델 성능에 미치는 영향은 무엇인가?
- RQ5대형 개방 코퍼스의 데이터 오염 및 누출 위험은 무엇이며 어떻게 탐지할 수 있는가?
주요 결과
| Model | CEVAL | CMMLU | MMLU | GSM8K |
|---|---|---|---|---|
| OpenLLaMA-13B | 27.1 | 26.7 | 42.7 | 12.4 |
| LLaMA-13B | 35.5 | 31.2 | 46.9 | 17.8 |
| LLaMA2-13B | 36.5 | 36.6 | 54.8 | 28.7 |
| Baichuan-13B | 52.4 | 55.3 | 51.6 | 26.6 |
| Baichuan2-13B | 58.1 | 62.0 | 59.2 | 52.8 |
| XVERSE-13B | 54.7 | - | 55.1 | - |
| InternLM-20B | 58.8 | - | 62.0 | 52.6 |
| Skywork-13B | 60.6 | 61.8 | 62.1 | 55.8 |
- Skywork-13B는 공개 13B 모델 중 CEVAL(60.6) 및 MMLU(62.1) 벤치마크에서 선두 결과를 달성.
- Skywork-13B는 GSM8K에서 55.8을 달성하여 유사 규모의 여러 개방 모델보다 우수한 성능을 보임.
- CMMLU에서 Baichuan2-13B가 선두(62.0)를 차지하는 반면, Skywork-13B도 여전히 강력한 성능(61.8)을 제공.
- 언어 모델링 도메인 평가에서 Skywork-13B는 기술(11.58), 영화(21.84), 정부(4.76), 금융(4.92) 등 다양한 도메인에서 평균 혼란도(perplexity) 최저를 달성.
- Stage-2 STEM 중심 사전 학습은 언어 모델링을 불안정화시키지 않으면서 STEM 관련 능력과 벤치마크(예: CEVAL, GSM8K)를 크게 강화.
- Skywork-13B는 중국어 언어 모델링 강점이 탁월하여 많은 개방 모델은 물론 더 큰 폐쇄 모델들에도 비해 중국 중심 벤치마크에서 우위를 보임.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.