[논문 리뷰] Small Language Models: Survey, Measurements, and Insights
이 논문은 59개의 오픈 소스 디코더-전용 소형 언어 모델(100M–5B)을 조사하고 아키텍처, 학습 데이터, 알고리즘, 능력치, 및 온-디바이스 런타임 비용을 벤치마크하여 엣지 배치를 위한 통찰을 얻는다.
Small language models (SLMs), despite their widespread adoption in modern smart devices, have received significantly less academic attention compared to their large language model (LLM) counterparts, which are predominantly deployed in data centers and cloud environments. While researchers continue to improve the capabilities of LLMs in the pursuit of artificial general intelligence, SLM research aims to make machine intelligence more accessible, affordable, and efficient for everyday tasks. Focusing on transformer-based, decoder-only language models with 100M-5B parameters, we survey 70 state-of-the-art open-source SLMs, analyzing their technical innovations across three axes: architectures, training datasets, and training algorithms. In addition, we evaluate their capabilities in various domains, including commonsense reasoning, mathematics, in-context learning, and long context. To gain further insight into their on-device runtime costs, we benchmark their inference latency and memory footprints. Through in-depth analysis of our benchmarking data, we offer valuable insights to advance research in this field.
연구 동기 및 목표
- 디코더-전용 소형 언어 모델(100M–5B)과 그 출시 구성에 대해 체계적으로 검토한다.
- 조사 대상 SLM 전반에서 아키텍처, 학습 데이터 세트, 및 학습 알고리즘을 분석한다.
- 상식 추론, 맥락 학습, 수학, 코딩에 걸친 능력을 벤치마킹한다.
- 엣지 배치를 알리기 위해 온-디바이스 런타임 비용(지연, 메모리, 에너지)을 평가한다.
- 향후 SLM 연구 및 하드웨어 인식 설계에 대한 통찰과 지침을 제공한다.
제안 방법
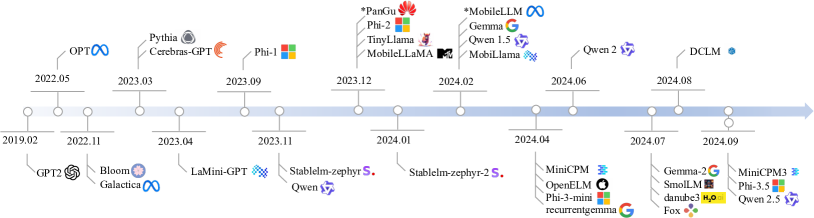
- 59개의 오픈 소스 디코더-전용 SLMs를 100M–5B 매개변수로 수집하고 분류한다.
- 상식 추론, 문제 해결, 수학, 맥락 학습에서의 능력을 벤치마크한다.
- 공통 추론 엔진(llama.cpp)을 사용하여 엣지 디바이스에서 프리필 지연, 디코드 지연, 메모리, 에너지를 포함한 온-디바이스 런타임 비용을 측정한다.
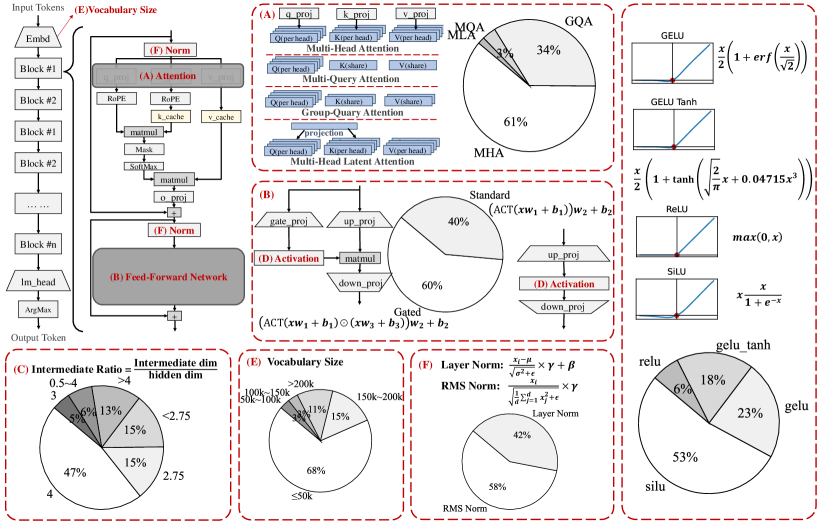
- 아키텍처(주목도 유형, FFN, 활성화, 정규화, 어휘) 및 학습 데이터 사용을 분석한다.
- 모델 기반 필터링을 포함한 데이터 품질과 데이터 세트의 차이를 비교한다.
- SLM 개발을 위한 데이터 품질, 데이터 세트 선택, 아키텍처 선택에 대한 인사이트를 추출한다.
실험 결과
연구 질문
- RQ1SLM에서 널리 사용되는 아키텍처 선택은 어떤 것이며 이것이 온-디바이스 성능에 어떤 영향을 미치는가?
- RQ2오픈 소스 학습 데이터 세트와 데이터 품질이 SLM의 능력에 미치는 영향은 비공개 데이터와 비교하여 어떤가?
- RQ3SLM은 상식 추론, 문제 해결, 수학 과제에서 어떻게 수행되며, 모델 크기와 데이터가 이 성능에 어떤 영향을 미치는가?
- RQ4SLM의 하드웨어 및 양자화 설정 전반에 걸친 온-디바이스 지연, 메모리, 에너지 특성은 어떠한가?
주요 결과
- SLMs는 2022년에서 2024년 사이에 상식 추론, 문제 해결, 수학에서 대략 각각 10.4%, 13.5%, 13.5%의 성능 향상을 보였다.
- Phi 계열은 대부분의 작업에서 최첨단 결과를 제공하며, Phi-3-mini는 일부 사례에서 Llama 3.1 8B에 필적하고, 평가된 모델들 중에서 수학에서 Phi-3-mini가 앞섰다.
- FineWeb-Edu 및 DCLM-baseline 같은 오픈 소스 데이터 세트가 모델 기반 필터링을 활용하여 비공개 데이터 세트에 비해 경쟁력 있는 성능을 달성한다.
- 매개변수 수가 많을수록 일반적으로 성능이 더 좋지만 예외도 존재한다(예: Qwen 2); 데이터 품질과 학습 데이터 선택이 종종 순수 모델 크기보다 더 큰 영향을 준다.
- 맥락 학습은 일반적으로 더 큰 모델에서 이점이 있으며, 평균적으로 5샷 프롬프트가 약 2.1%의 정확도 향상을 가져오며, Gemma-2가 가장 큰 이득을 보인다.
- 복합적 추론이나 수학 과제가 필요한 작업에서 오픈 소스와 클로즈드 소스 모델 간의 격차가 남아 있어 더 높은 품질의 추론 데이터 세트가 필요하다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.