[논문 리뷰] SMART-LLM: Smart Multi-Agent Robot Task Planning using Large Language Models
SMART-LLM은 대형 언어 모델을 활용하여 고수준 지시를 분해하고 로봇 연대(연합)를 형성하며 이기종 다중 로봇 팀의 작업을 할당한다. AI2-THOR 시뮬레이션과 실제 로봇에서 시연되었다.
In this work, we introduce SMART-LLM, an innovative framework designed for embodied multi-robot task planning. SMART-LLM: Smart Multi-Agent Robot Task Planning using Large Language Models (LLMs), harnesses the power of LLMs to convert high-level task instructions provided as input into a multi-robot task plan. It accomplishes this by executing a series of stages, including task decomposition, coalition formation, and task allocation, all guided by programmatic LLM prompts within the few-shot prompting paradigm. We create a benchmark dataset designed for validating the multi-robot task planning problem, encompassing four distinct categories of high-level instructions that vary in task complexity. Our evaluation experiments span both simulation and real-world scenarios, demonstrating that the proposed model can achieve promising results for generating multi-robot task plans. The experimental videos, code, and datasets from the work can be found at https://sites.google.com/view/smart-llm/.
연구 동기 및 목표
- 이기종 팀에서 유연하고 언어 기반의 다중 로봇 작업 계획의 필요성을 제시한다.
- 작업을 분해하고, 연합을 형성하며, 작업을 할당하고 계획을 실행하는 LLM을 활용한 4단계 프레임워크를 개발한다.
- 다양한 작업 복잡도에 따른 다중 로봇 계획을 평가하기 위해 AI2-THOR에서 벤치마크 데이터셋을 생성하고 활용한다.
- 시뮬레이션과 실제 로봇 실험에서의 적용 가능성을 시연하고, 서로 다른 프롬프트 및 기준선 하에서 성능을 분석한다.
제안 방법
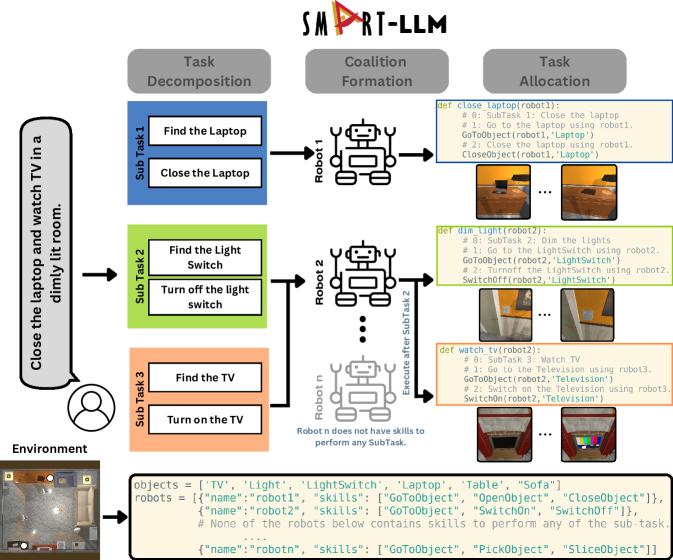
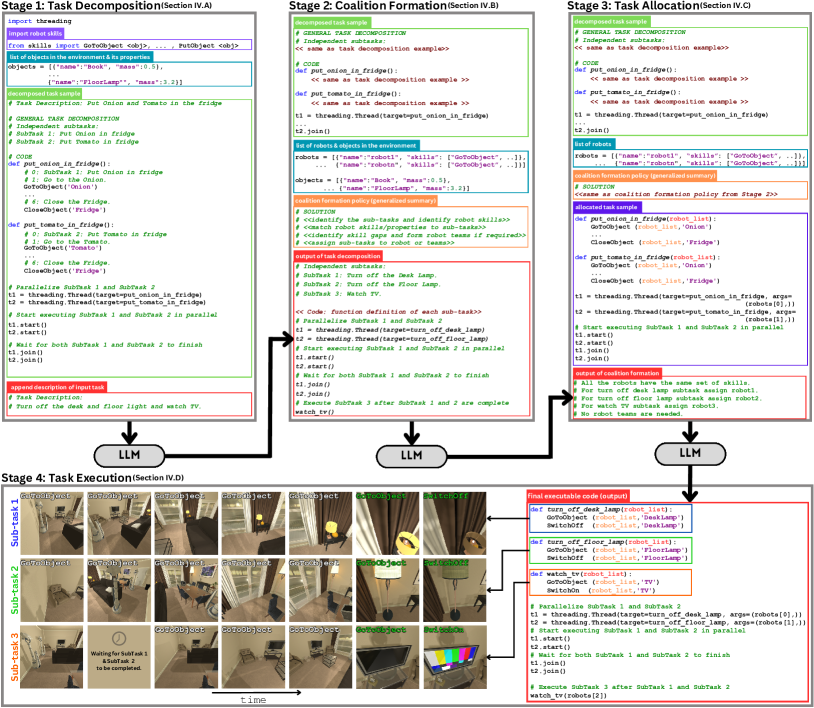
- Stage 1 (Task Decomposition): LLM에 환경 및 기술 정보를 제공하고, few-shot Python 기반 프롬프트를 사용하여 하위 작업 및 동작 시퀀스를 생성한다.
- Stage 2 (Coalition Formation): 로봇 기술, 환경 객체, 샘플 연합을 LLM에 제시하여 하위 작업에 대한 연합 정책을 생성한다.
- Stage 3 (Task Allocation): 분해된 작업, 연합 정책, 그리고 할당된 계획을 제시하여 실행 가능한 작업 할당을 생성한다.
- Stage 4 (Task Execution): 할당된 계획을 로봇 저수준 기술의 API 호출이나 해석기를 통해 실행하여 병렬 또는 순차 실행을 적절히 가능하게 한다.
- Prompts leverage Pythonic structure with line-by-line comments and task-level summaries to guide LLM reasoning and code generation.
- Evaluation uses a benchmark dataset derived from AI2-THOR to assess planning quality across elemental, simple, compound, and complex tasks.
실험 결과
연구 질문
- RQ1Can GPT-4-based prompting enable robust task decomposition, coalition formation, and allocation for heterogeneous robot teams?
- RQ2To what extent can an LLM-driven pipeline achieve high success rates and efficient robot utilization across tasks of increasing complexity?
- RQ3How does GPT-4 compare to GPT-3.5 in complex multi-robot planning scenarios?
- RQ4What is the impact of including natural language comments and coalition prompts on planning performance?
- RQ5Can the framework generalize from simulated prompts to real-robot task planning?
주요 결과
- SMART-LLM achieves perfect success in elemental tasks in simulations.
- For simple tasks, SMART-LLM achieves TCR = 1.0 but exhibit lower SR due to sequential vs parallel execution, affecting RU.
- In compound and complex tasks, success rates are 70% with some sequencing and team-assignment challenges.
- GPT-4 generally outperforms GPT-3.5, especially on complex tasks requiring reasoning and diverse sub-skills.
- Removing comments, summaries, or coalition formation generally reduces performance, highlighting the value of reasoning-enhanced prompts and structured prompts.
- Real-robot experiments showed the method can allocate appropriate robot teams for coverage/patrol tasks unseen in simulation.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.