[논문 리뷰] SmolLM2: When Smol Goes Big -- Data-Centric Training of a Small Language Model
SmolLM2는 ~11T 토큰을 사용한 다단계 데이터 중심 접근법으로 학습된 1.7B 파라미터 언어 모델이며 새로운 데이터셋(FineMath, Stack-Edu, SmolTalk)을 활용합니다; 동급 규모의 LM들 사이에서 최첨단 성능을 달성하고 데이터와 함께 공개됩니다.
While large language models have facilitated breakthroughs in many applications of artificial intelligence, their inherent largeness makes them computationally expensive and challenging to deploy in resource-constrained settings. In this paper, we document the development of SmolLM2, a state-of-the-art "small" (1.7 billion parameter) language model (LM). To attain strong performance, we overtrain SmolLM2 on ~11 trillion tokens of data using a multi-stage training process that mixes web text with specialized math, code, and instruction-following data. We additionally introduce new specialized datasets (FineMath, Stack-Edu, and SmolTalk) at stages where we found existing datasets to be problematically small or low-quality. To inform our design decisions, we perform both small-scale ablations as well as a manual refinement process that updates the dataset mixing rates at each stage based on the performance at the previous stage. Ultimately, we demonstrate that SmolLM2 outperforms other recent small LMs including Qwen2.5-1.5B and Llama3.2-1B. To facilitate future research on LM development as well as applications of small LMs, we release both SmolLM2 as well as all of the datasets we prepared in the course of this project.
연구 동기 및 목표
- 지식, 추론, 코드, 수학적 역량을 유지하면서 계산 비용을 줄이기 위해 성능이 우수한 소형 LMs의 개발을 촉진한다.
- 세심한 데이터 큐레이션과 단계적 학습이 소형 LM의 성능을 어떻게 극대화할 수 있는지 조사한다.
- 특화된 데이터셳(수학, 코드, 지시 이행 데이터)이 도메인 전용 및 일반 역량에 미치는 영향을 평가한다.
- 향후 소형 LMs 연구를 촉진하기 위해 재현 가능한 학습 파이프라인과 공개 데이터셋을 제공한다.
제안 방법
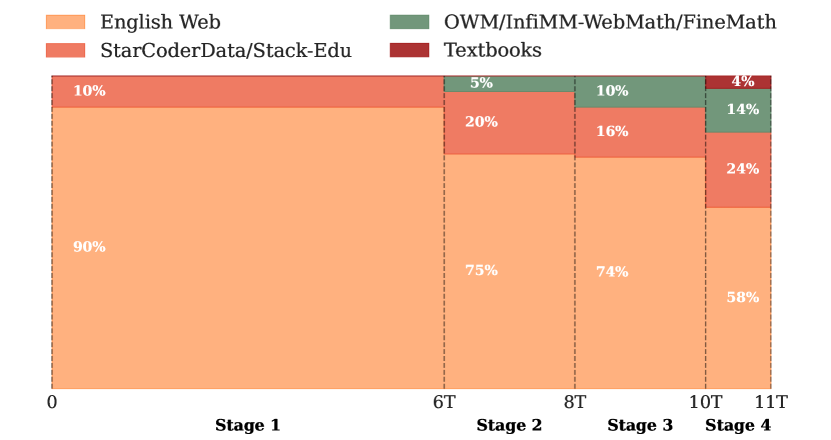
- 다단계 학습 일정으로 ~11T 토큰에 대해 1.7B 파라미터의 Transformer(LLaMA2 기반)를 학습시킨다.
- 데이터셋 혼합을 안내하기 위해 영어 웹 데이터 제거(ablation)들을 체계적으로 평가하고 즉시 재균형화를 도입한다.
- 수학, 코드, 지시 수행에서의 격차를 해소하기 위해 새로운 특화 데이터셋인 FineMath, Stack-Edu, SmolTalk를 만들고 통합한다.
- 후기 단계에서 수학, 코드와 같은 고품질 도메인의 계층적 어닐링(stage-wise annealing)과 데이터셋 업샘플링을 수행하여 역량을 극대화한다.
- 체크포인팅과 RoPE 스케일링을 통해 컨텍스트 길이를 8k 토큰으로 확장하여 긴 컨텍스트 작업을 가능하게 한다.
- 지시 조정(SmolTalk)과 선호 학습(DPO)을 통한 사후 학습으로 지시 수행 버전을 생성한다.
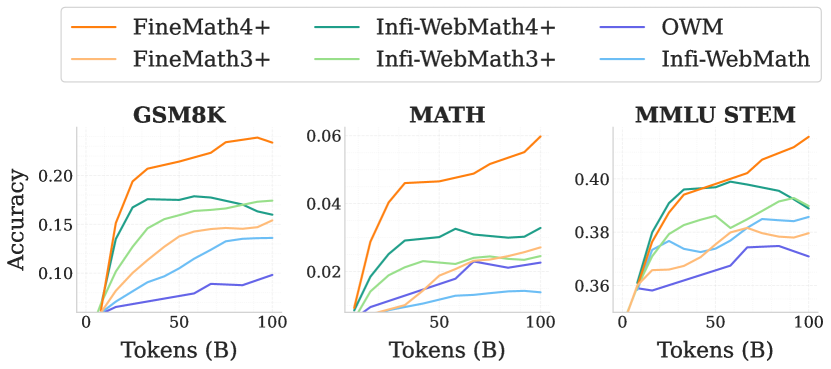
실험 결과
연구 질문
- RQ1데이터셋 구성과 단계적 학습이 벤치마크 전반에서 소형 LM의 성능에 어떤 영향을 미치는가?
- RQ2특화 데이터(수학, 코드, 지시 이행)가 소형 LMs의 추론 및 도메인 전용 역량을 향상시키는가?
- RQ3데이터 업샘플링과 후반 단계에서의 고품질 데이터셋 도입이 전반적 성능에 미치는 영향은 무엇인가?
- RQ4데이터 중심 접근법으로 학습된 1.7B 모델이 동급 규모의 LM들 사이에서 최첨단 성능에 도달할 수 있는가?
주요 결과
- SmolLM2 (1.7B)는 1–2B 크기 범위의 여러 벤치마크에서 Qwen2.5-1.5B 및 Llama3.2-1B를 능가한다.
- 최종 기본 SmolLM2는 뛰어난 일반화를 보이며 동료 모델 대비 MMLU-Pro, TriviaQA, Natural Questions, GSM8K, MATH, HumanEval에서 뚜렷한 향상을 보인다.
- 2k에서 8k 토큰으로 컨텍스트 길이를 확장한 후에도 성능은 견고하며 저하가 관찰되지 않았다.
- 후기 단계에서 수학과 코드에 중점을 둔 단계적 데이터 혼합은 수학 및 코딩 능력에서 큰 향상을 낳는다.
- SmolLM2의 지시 조정 버전(SmolTalk)과 Direct Preference Optimization에 의한 정렬은 지시 이행 성능을 더욱 향상시킨다.
- 본 연구는 향후 연구를 지원하기 위해 SmolLM2와 준비된 모든 데이터셋(FineMath, Stack-Edu, SmolTalk)을 공개한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.