[논문 리뷰] SOD-YOLOv8 -- Enhancing YOLOv8 for Small Object Detection in Traffic Scenes
SOD-YOLOv8는 Efficient GFPN 기반의 다중 스케일 융합, C2f-EMA 주의 모듈, 추가 고해상도 탐지 레이어, 그리고 PIoU 손실을 통해 트래픽 장면에서 작은 객체 탐지를 대기 시간 증가 없이 향상시킵니다.
Object detection as part of computer vision can be crucial for traffic management, emergency response, autonomous vehicles, and smart cities. Despite significant advances in object detection, detecting small objects in images captured by distant cameras remains challenging due to their size, distance from the camera, varied shapes, and cluttered backgrounds. To address these challenges, we propose Small Object Detection YOLOv8 (SOD-YOLOv8), a novel model specifically designed for scenarios involving numerous small objects. Inspired by Efficient Generalized Feature Pyramid Networks (GFPN), we enhance multi-path fusion within YOLOv8 to integrate features across different levels, preserving details from shallower layers and improving small object detection accuracy. Also, A fourth detection layer is added to leverage high-resolution spatial information effectively. The Efficient Multi-Scale Attention Module (EMA) in the C2f-EMA module enhances feature extraction by redistributing weights and prioritizing relevant features. We introduce Powerful-IoU (PIoU) as a replacement for CIoU, focusing on moderate-quality anchor boxes and adding a penalty based on differences between predicted and ground truth bounding box corners. This approach simplifies calculations, speeds up convergence, and enhances detection accuracy. SOD-YOLOv8 significantly improves small object detection, surpassing widely used models in various metrics, without substantially increasing computational cost or latency compared to YOLOv8s. Specifically, it increases recall from 40.1\% to 43.9\%, precision from 51.2\% to 53.9\%, $ ext{mAP}_{0.5}$ from 40.6\% to 45.1\%, and $ ext{mAP}_{0.5:0.95}$ from 24\% to 26.6\%. In dynamic real-world traffic scenes, SOD-YOLOv8 demonstrated notable improvements in diverse conditions, proving its reliability and effectiveness in detecting small objects even in challenging environments.
연구 동기 및 목표
- 교통 현장과 UAV 영상에서 작은 객체 탐지의 문제를 해결한다.
- 작은 객체를 위한 얕은 레이어의 공간 정보를 보존하도록 특징 융합을 개선한다.
- 채널 간 특징의 재가중을 위한 주의 기반 C2f-EMA 모듈을 도입한다.
- 바운딩 박스 회귀와 수렴을 개선하기 위해 Powerful-IoU(PIoU)를 도입한다.
- 실세계 교통 영상에서 YOLOv8 및 다른 기준 모델과 비교하여 성능을 평가한다.
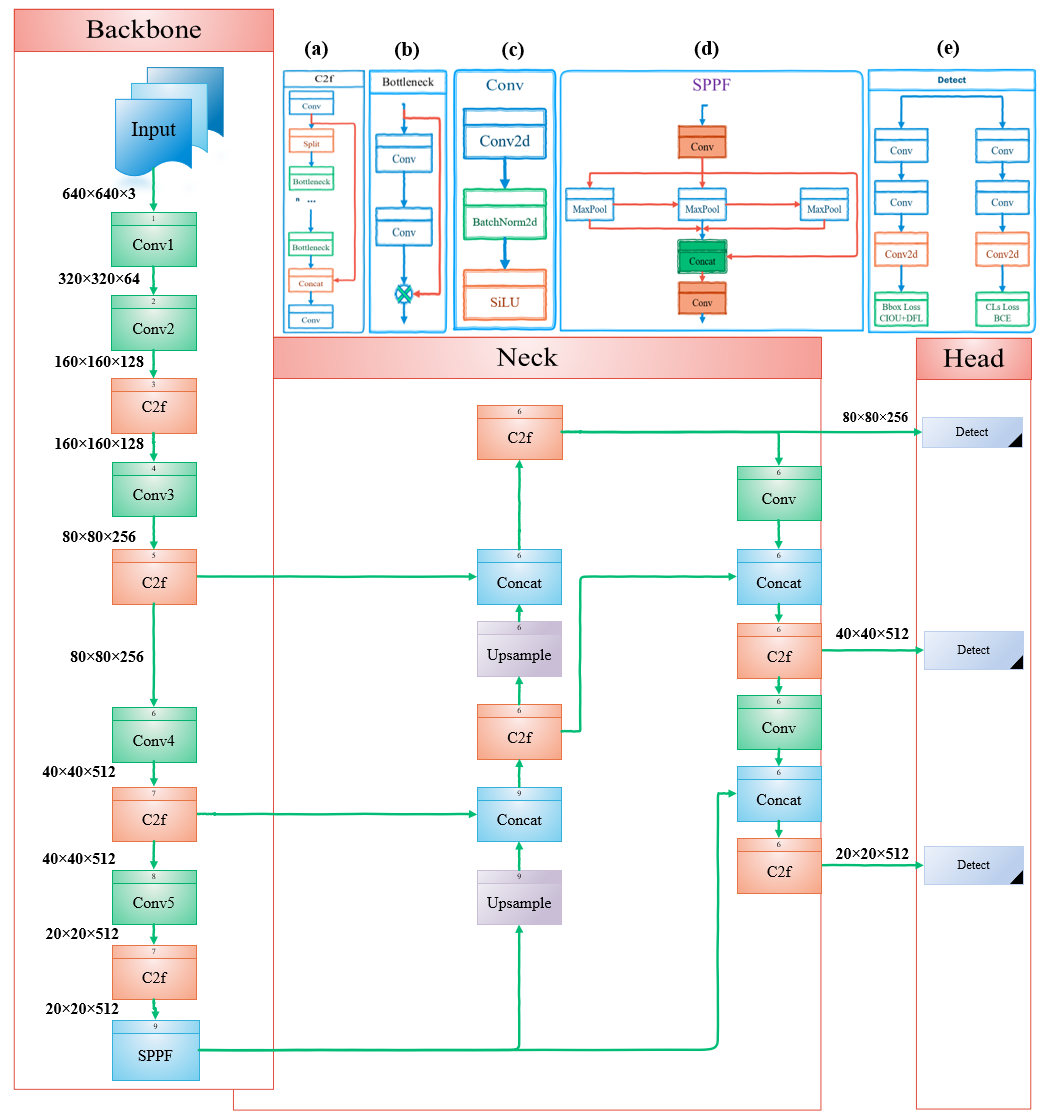
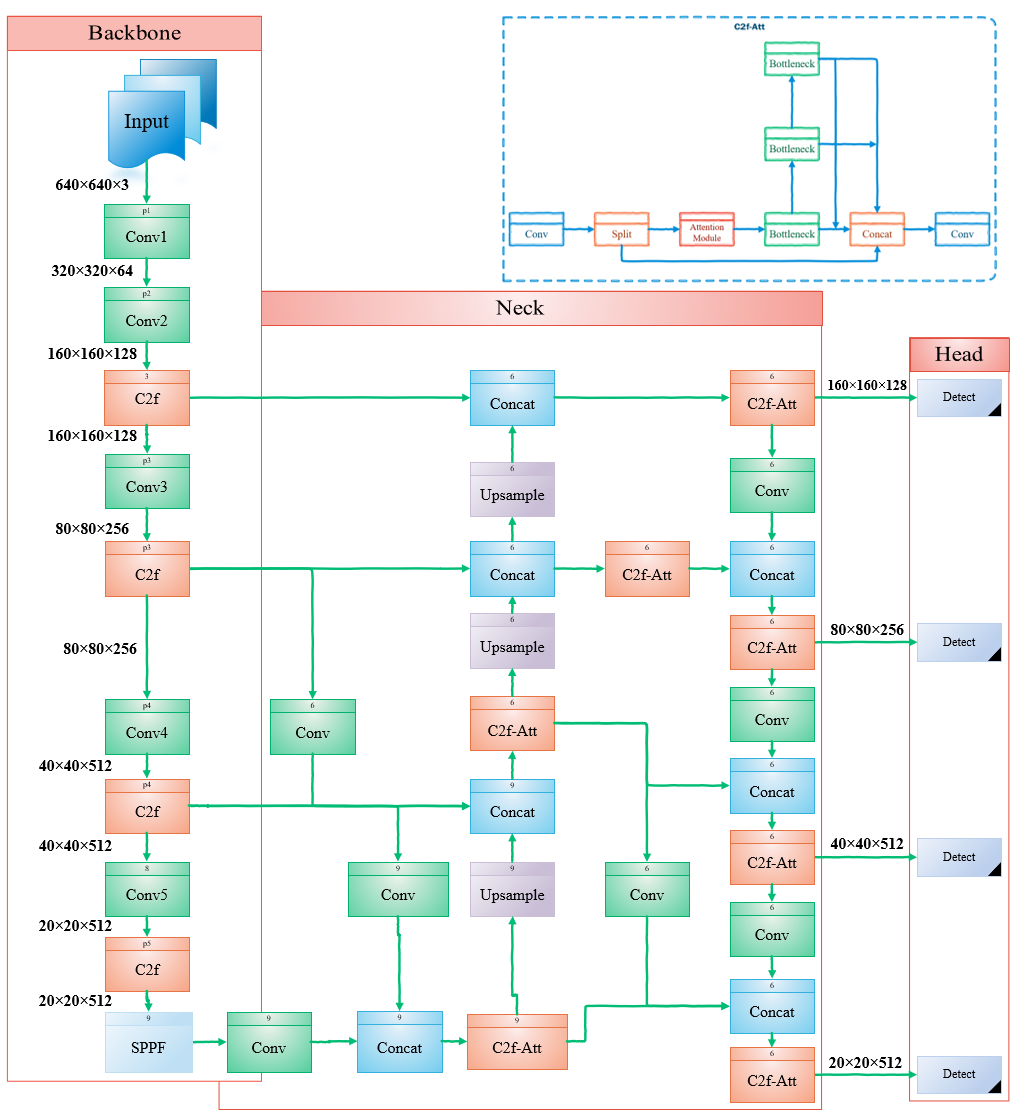
제안 방법
- skip-layer 및 queen fusion 연결을 가진 다중 스케일 특징 융합을 개선하기 위해 향상된 GFPN으로 PAFPN을 대체한다. Efficient-RepGFPN에서 영감을 얻었다.
- 작은 객체를 위한 고해상도 공간 정보를 보존하기 위해 P2 피처를 포함하여 네 번째 탐지 레이어를 추가한다.
- 더 나은 작은 객체 표현을 위해 Efficient Multi-Scale Attention을 사용하여 채널 가중치를 재분배하는 C2f-EMA를 도입하고 C2f를 대체한다.
- 수렴 가속 및 위치화 안정성 향상을 위해 바운딩 박스 회귀 손실에서 CIoU를 PIoU로 교체한다.
- EMA 기반 C2f-EMA 메커니즘의 상세 설명을 1x1 및 3x3 분기와 2D 공간 주의 처리를 포함해 제공한다.
- 시각 분석 및 실세계 교통 영상으로 방법이 지연 증가 없이 작은 객체 탐지 성능을 향상시킨다는 것을 시연한다.
실험 결과
연구 질문
- RQ1YOLOv8에서 작은 객체에 중요한 얕은 레이어의 공간 정보를 보존하기 위해 다중 스케일 특징 융합을 어떻게 재설계할 수 있는가?
- RQ2C2f-EMA 주의 모듈이 YOLOv8 넥에서 작은 객체 탐지 성능 및 특징 표현을 향상시키는가?
- RQ3PIoU가moderate-quality 앵커에서 CIoU보다 더 빠른 수렴 및 더 나은 바운딩 박스 회귀를 제공하는가?
- RQ4고해상도 특성을 활용하는 네 번째 탐지 레이어를 추가하는 것이 작은 객체 탐지 정확도와 지연에 어떤 영향을 미치는가?
- RQ5SOD-YOLOv8가 실제 세계의 역동적인 교통 현장에서 기준 YOLOv8s 및 다른 작은 객체 탐지기와 비교하여 어떤 성능을 보이는가?
주요 결과
- Recall가 40.1%에서 43.9%로 향상된다.
- Precision이 51.2%에서 53.9%로 향상된다.
- mAP@0.5가 40.6%에서 45.1%로 향상된다.
- mAP@0.5:0.95가 24%에서 26.6%로 향상된다.
- SOD-YOLOv8은 YOLOv8s에 비해 지연 및 연산 비용의 변화가 크지 않으면서도 이러한 이점을 달성한다.
- 시각 분석 및 실세계 교통 영상은 다양한 조건에서 작은 객체 탐지 성능이 개선됨을 검증한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.