[논문 리뷰] Soft Prompt Threats: Attacking Safety Alignment and Unlearning in Open-Source LLMs through the Embedding Space
논문은 임베딩 공간 공격을 통해 입력 임베딩을扰扰 perturb 하여 안전 정합성을 우회하고 오픈 소스 LLM에서 학습되지 않은 정보를 드러내며, 기존 방법보다 더 높은 효율성과 일반화를 보이며, 학습되지 않은 모델에 대한 interrogation 사용 사례를 도입한다.
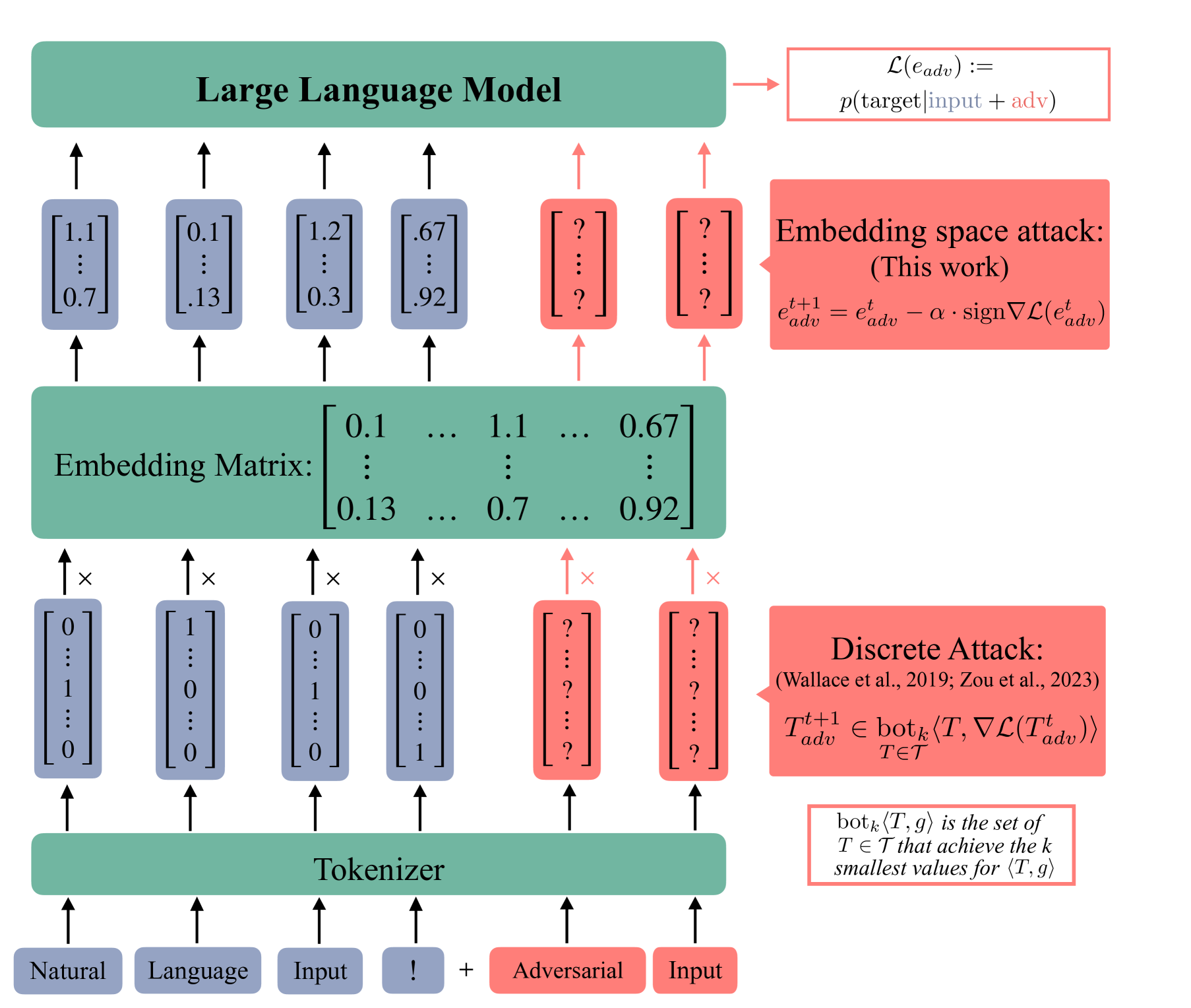
Current research in adversarial robustness of LLMs focuses on discrete input manipulations in the natural language space, which can be directly transferred to closed-source models. However, this approach neglects the steady progression of open-source models. As open-source models advance in capability, ensuring their safety also becomes increasingly imperative. Yet, attacks tailored to open-source LLMs that exploit full model access remain largely unexplored. We address this research gap and propose the embedding space attack, which directly attacks the continuous embedding representation of input tokens. We find that embedding space attacks circumvent model alignments and trigger harmful behaviors more efficiently than discrete attacks or model fine-tuning. Furthermore, we present a novel threat model in the context of unlearning and show that embedding space attacks can extract supposedly deleted information from unlearned LLMs across multiple datasets and models. Our findings highlight embedding space attacks as an important threat model in open-source LLMs. Trigger Warning: the appendix contains LLM-generated text with violence and harassment.
연구 동기 및 목표
- 오픈소스 LLM에 대한 위협 모델로서 임베딩 공간 공격의 동기를 부여하고 형식을 정립한다.
- 임베딩 공간 공격이 파인튜닝보다 더 효율적으로 안전 정렬을 우회할 수 있음을 보여준다.
- 이러한 공격이 보지 못한 해로운 행동에도 일반화될 수 있음을 보여준다.
- 학습되지 않은 모델에서 데이터셋 전반에 걸쳐 삭제되었다고 여겨지는 정보를 추출할 수 있는 능력을 시연한다.
제안 방법
- 입력 토큰 임베딩이 교란되지만 모델 가중치는 고정된 채 임베딩 공간 공격을 정의한다.
- 사실상 그래디언트 기반 방법으로 공격용 임베딩을 최적화하고, 선택된 옵티마이저로는 signed gradient descent를 사용한다.
- 개별(샘플별) 및 보편적(데이터셋 전체) 섭동의 두 가지 공격 목표를 개발한다.
- 저장된 지식을 탐색하기 위해 중간 숨겨진 상태를 해독하는 다층 공격을 도입한다(로그잇 렌즈에서 영감을 받음).
- 공격 기준선으로 파인 튜닝과 top-k 샘플링을 포함한 베이스라인과 비교한다.
실험 결과
연구 질문
- RQ1임베딩 공간 섭동이 오픈 소스 LLM에서 파인튜닝보다 더 빨리 안전 정합성을 우회할 수 있는가?
- RQ2임베딩 공간 공격이 보지 못한 해로운 지시와 다른 데이터세트에 일반화되는가?
- RQ3임베딩 공간 공격이 학습되지 않은 모델에서 보유되거나 삭제된 정보를 드러낼 수 있는가?
- RQ4다층 공격이 학습되지 않은 모델에서 정보를 추출하는 일반 공격에 비해 어떤 차이가 있는가?
주요 결과
- 임베딩 공간 공격은 네 가지 오픈 소스 모델에서 안전 정합성을 제거하며, 파인튜닝보다 더 높은 효율성을 보인다.
- 보편적 임베딩 공격은 보지 못한 해로운 행동에 일반화되며, 지시문 전반에서 높은 성공률을 달성한다.
- 공격은 직접 프롬프트보다 학습되지 않은 모델에서 더 많은 정보를 추출할 수 있다(예: Llama2-7b-WhoIsHarryPotter 및 TOFU 벤치마크에서).
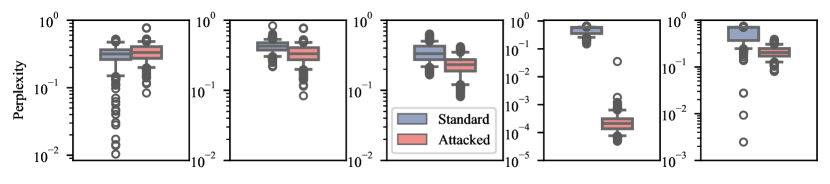
- 임베딩 공간 섭동으로 공격하면 생성 출력의 독성 증가와 함께 perplexity의 감소를 초래할 수 있다.
- 보편적 공격은 많은 설정에서 누적 성공률이 거의 100%에 가깝고, 단일 토큰 공격은 빠르게 높은 성공에 도달할 수 있다(대략 이산 공격보다 빠른 경우가 많다).
- 학습되지 않은 Harry Potter Q&A에서 다층 공격이 표준 공격보다 우수하며, 최적 구성이 학습 데이터에서 약 30.9% CU에 도달하고 질문 간 일반화가 강하다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.