[논문 리뷰] Sources of Hallucination by Large Language Models on Inference Tasks
본 논문은 자연어 추론(NLI) 중 LLM의 환각을 유발하는 두 가지 사전학습 유발 편향을 식별한다: 입증된 가설의 암기와 코퍼스 빈도 기반의 함의. 이 편향들이 잘못된 긍정(false positives)을 초래하고 LLaMA, GPT-3.5, PaLM에서 비일치 샘플에 대한 성능을 악화시킨다는 것을 보여준다.
Large Language Models (LLMs) are claimed to be capable of Natural Language Inference (NLI), necessary for applied tasks like question answering and summarization. We present a series of behavioral studies on several LLM families (LLaMA, GPT-3.5, and PaLM) which probe their behavior using controlled experiments. We establish two biases originating from pretraining which predict much of their behavior, and show that these are major sources of hallucination in generative LLMs. First, memorization at the level of sentences: we show that, regardless of the premise, models falsely label NLI test samples as entailing when the hypothesis is attested in training data, and that entities are used as ``indices'' to access the memorized data. Second, statistical patterns of usage learned at the level of corpora: we further show a similar effect when the premise predicate is less frequent than that of the hypothesis in the training data, a bias following from previous studies. We demonstrate that LLMs perform significantly worse on NLI test samples which do not conform to these biases than those which do, and we offer these as valuable controls for future LLM evaluation.
연구 동기 및 목표
- LLM 자연어 추론에서 환각으로 이어지는 편향을 식별한다.
- 암기 기반 편향과 코퍼스 통계 기반 편향을 사전학습 아티팩트로 구분한다.
- 입증된 가설과 빈도 기반 함의에 대한 예측에 이러한 편향이 어떻게 영향을 미치는지 평가한다.
제안 방법
- 제어된 데이터셋 변환을 사용하여 LLaMA-65B, GPT-3.5, PaLM-540B에서 행동적 NLI 실험을 수행한다.
- Attestation Bias (Λ)를 훈련 데이터에서의 가설 입증 의존도로 정의하고 입증 프롬프트로 측정한다.
- Relative Frequency Bias (Φ)를 훈련 코퍼라의 서술(전제) 대비 가설의 빈도 차이를 기준으로 정의하고 Google N-grams를 프록시로 사용한다.
- Levy/Holt 및 RTE-1 스타일 프롬프트를 삼지선다 NLI 선택지와 최소한의 few-shot 예제로 사용하여 기억 및 편향 효과를 탐구한다.
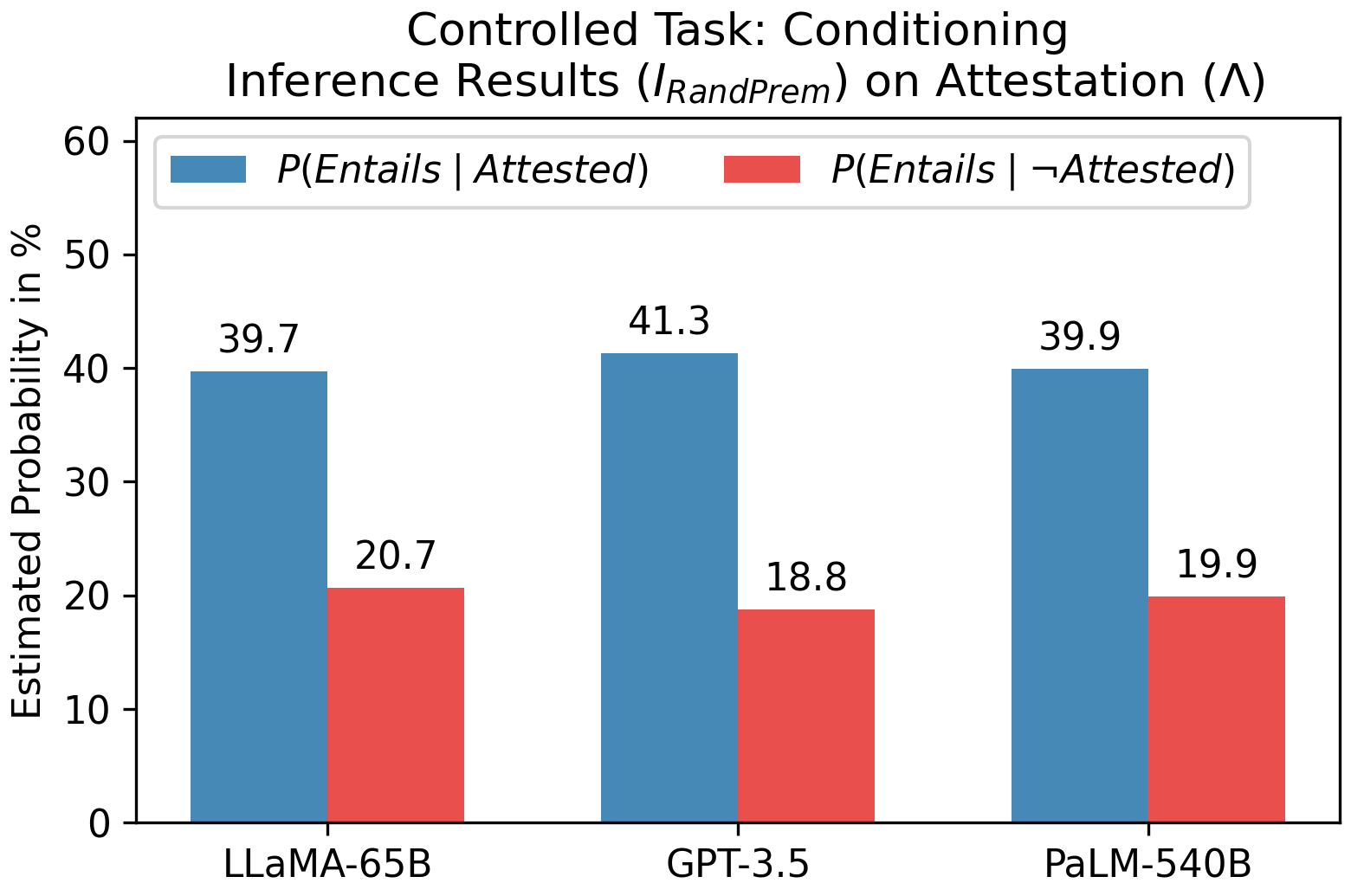
- 데이터셋 변환(I_RandPrem, I_GenArg, I_RandArg, I_RandArg↑/↓을 적용하여 기억 효과를 표면 신호로부터 분리한다.
- 바이어스 일관된 집합과 적대적 하위집합에서 재현율/정밀도 지표와 AUC_norm을 통해 영향을 평가한다.
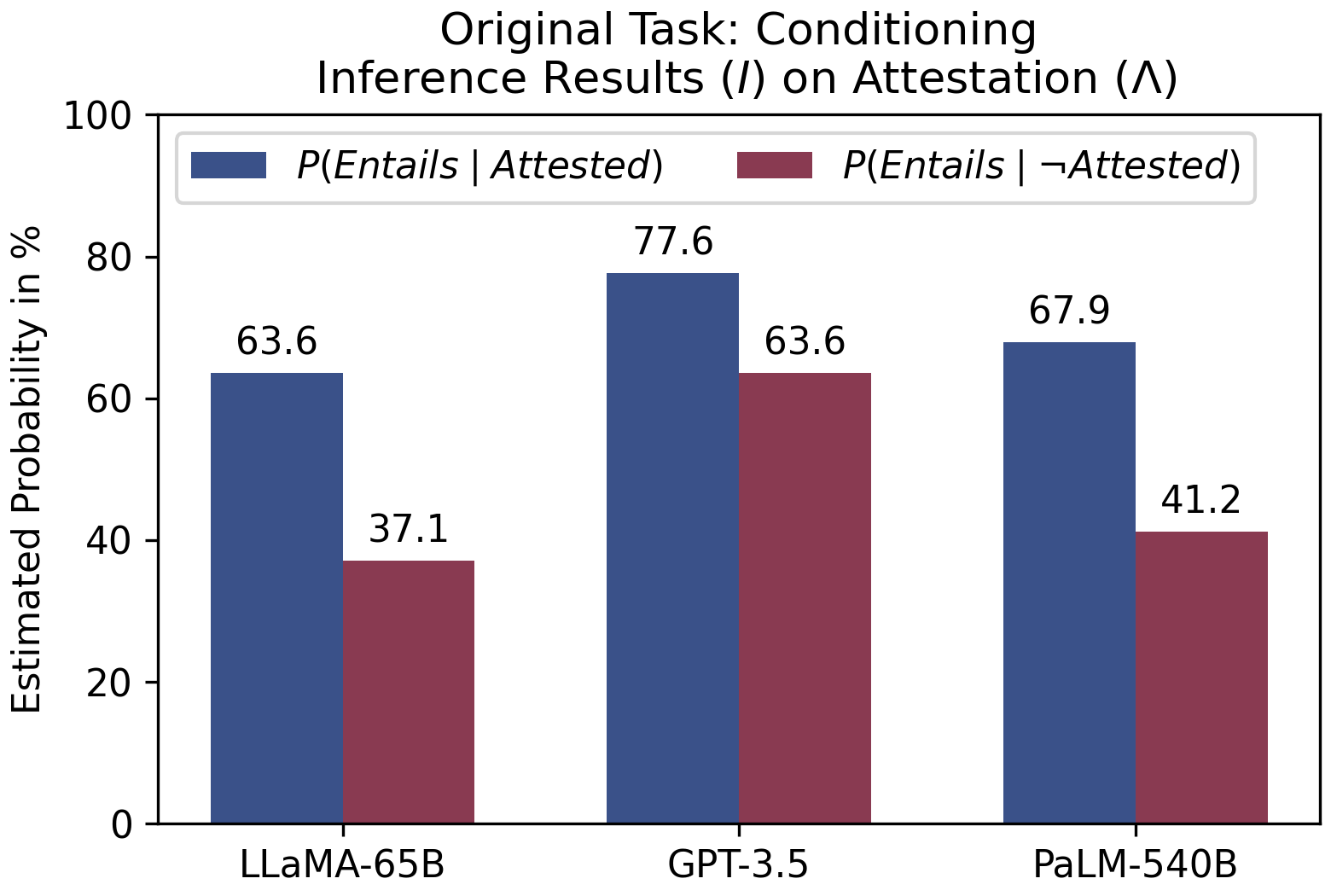
실험 결과
연구 질문
- RQ1LLM은 NLI 작업을 해결할 때 훈련 데이터의 명제적 기억에 의존하는가?
- RQ2명명된 엔티티가 추론에서 기억 인덱스로 작동하는 것이 기억 회상에 결정적인가?
- RQ3코퍼스 빈도 편향이 의미적 내용과 무관하게 함의 판단을 좌우하는가?
- RQ4이 편향들이 편향에 일치하는 샘플과 모순하는 샘플에서 모델 성능에 어떤 영향을 미치는가?
주요 결과
- 가설이 훈련 데이터에서 입증되면 LLM은 더 높은 Entail 예측을 보이며, 이는 Attestation Bias (Λ)를 시사한다.
- 엔티티를 일반적이거나 무작위로 대체하면 기억 회상이 저하되며, 명명된 엔티티가 기억 인덱스로 작동한다는 시사점이다.
- Relative Frequency Bias (Φ)가 모델에서 나타나며, training data에서 premise가 hypothesis보다 덜 빈번할 때 함의 가능성이 더 높은 경향이 있다.
- LLaMA, GPT-3.5, PaLM 전반에서 기억 및 빈도 기반 편향은 상당한 거짓 양성(False Positives)을 야기하고 적대적 샘플에서 성능을 저하시킨다.
- 입증 및 빈도 편향은 모델 계열 전반에 걸쳐 지속되며 미세 조정이나 RLHF가 아닌 사전학습 목적과 연관되어 있다.
- 편향 일관성 vs 편향 대립 하위집합으로 평가할 때, 일반적인 NLI 점수는 실제 추론 능력을 오도할 수 있다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.