[논문 리뷰] Sparse Autoencoders Find Highly Interpretable Features in Language Models
본 논문은 희소 오토인코더를 사용해 언어 모델 활성에서 특징의 사전을 학습하여 더 해석 가능하고 단일 의미의 방향을 생성하고, 이는 모델 출력에 인과적으로 영향을 주며 중첩성을 감소시킬 수 있다.
One of the roadblocks to a better understanding of neural networks' internals is extit{polysemanticity}, where neurons appear to activate in multiple, semantically distinct contexts. Polysemanticity prevents us from identifying concise, human-understandable explanations for what neural networks are doing internally. One hypothesised cause of polysemanticity is extit{superposition}, where neural networks represent more features than they have neurons by assigning features to an overcomplete set of directions in activation space, rather than to individual neurons. Here, we attempt to identify those directions, using sparse autoencoders to reconstruct the internal activations of a language model. These autoencoders learn sets of sparsely activating features that are more interpretable and monosemantic than directions identified by alternative approaches, where interpretability is measured by automated methods. Moreover, we show that with our learned set of features, we can pinpoint the features that are causally responsible for counterfactual behaviour on the indirect object identification task \citep{wang2022interpretability} to a finer degree than previous decompositions. This work indicates that it is possible to resolve superposition in language models using a scalable, unsupervised method. Our method may serve as a foundation for future mechanistic interpretability work, which we hope will enable greater model transparency and steerability.
연구 동기 및 목표
- 언어 모델의 다의성 및 중첩성에 대응함으로써 기계적 해석 가능성에 동기를 부여한다.
- 내부 활성에서 해석 가능한 특징 방향을 추출하는 비지도 학습 방법을 개발한다.
- 학습된 사전 특징이 기준선보다 더 높은 자동 해석 가능성을 달성함을 보인다.
- 특정 작업에서 사전 특징의 모델 동작에 대한 인과적 관련성을 입증한다.
제안 방법
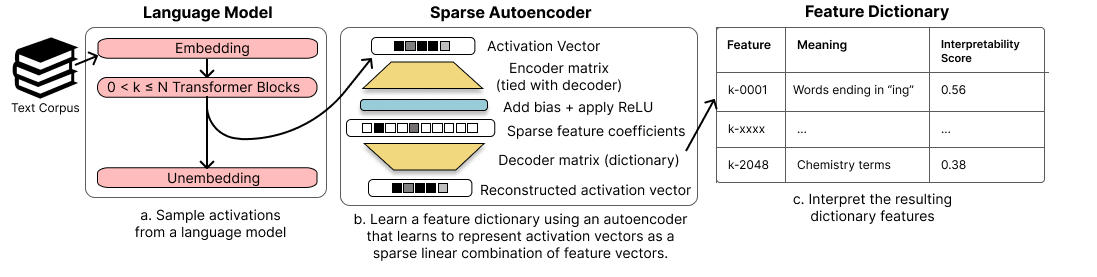
- 희소성 페널티를 가진 은닉 활성화에 대해 희소 오토인코더를 학습시켜 언어 모델 활성(잔류 스트림, MLP 서브레이어, 또는 어텐션 헤드 서브레이어)에서 특징 사전을 학습한다.
- 연결된 인코더/디코더 가중치와 사전 특징의 행별 정규화를 사용한다.
- 재구성 손실을 L1 희소성 항으로 최적화하여 실제 특징을 복원한다 (L2 재구성 손실 + alpha * ||c||1).
- 사전 특징 활성화에 대한 언어 모델의 설명에서 도출된 자동 해석 가능도 점수로 해석 가능성을 평가한다.
- 학습된 특징의 해석 가능성을 기준선(default basis, random directions, PCA, ICA)과 비교한다.
- 사전 특징의 인과적 영향을 IOI 작업에 국소화하기 위해 활성 패치와 Automated Circuit Discovery (ACDC)를 적용한다.
실험 결과
연구 질문
- RQ1희소 사전 특징은 다른 분해와 비교하여 다의성을 줄이고 해석 가능성을 높이는가?
- RQ2희소 사전 특징을 사용해 특정 작업에서 모델 출력의 정확한 위치를 국소화하고 인과적으로 영향을 미칠 수 있는가?
- RQ3해석 가능성과 출력에 대한 인과 효과 측면에서 사전 특징이 PCA/ICA/무작위 기준선과 비교하여 어떠한가?
- RQ4학습된 특징의 품질과 유용성에 있어 희소성 수준과 사전 크기의 역할은 무엇인가?
주요 결과
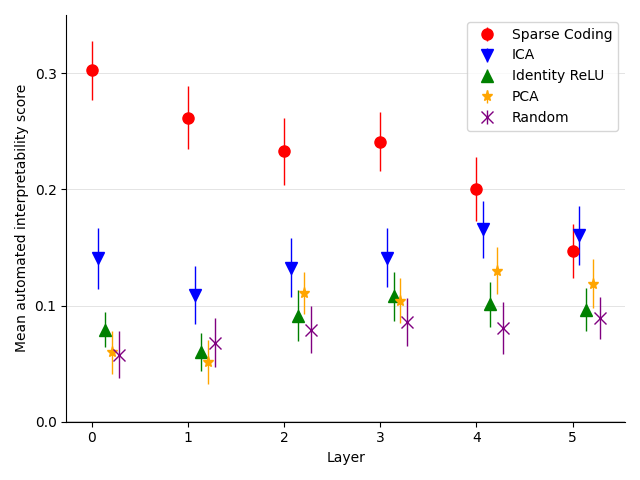
- 사전 특징이 평균적으로 뉴런 및 여러 기준선보다 해석 가능성이 높으며 자동 해석 가능도 점수로 측정된다.
- 희소 사전은 IOI에 대한 인과 특징을 PCA 기반 분해보다 더 적은 패치로 더 효율적으로 국소화하고 편집 규모가 작다.
- 단일 의미의 사전 특징이 좁은 언어 토큰(예: 따옴표, 마침표)에 대해 활성화되고 다음 토큰 로짓에 예측 가능한 영향을 미친다.
- 희소 사전으로의 활성 패칭은 비희소 사전에 비해 편집 규모와 편집의 철저도 간의 파레토 프런티어가 더 나은 성능을 보인다.
- 사례 연구는 해석 가능한 언어 현상에 대응하는 특징을 보여주고 계층 간의 상류/하류 인과 관계를 밝힌다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.