[논문 리뷰] Sparse4D v2: Recurrent Temporal Fusion with Sparse Model
Sparse4D v2는 희소 다중 뷰 3D 탐지를 위한 순환적 시간 융합 모듈을 도입하여 시간 융합을 O(T)에서 O(1)로 감소시키고 nuScenes에서 최첨단(SOTA) 결과를 달성하며, Efficient Deformable Aggregation과 카메라 파라미터 인코딩이 효율성 및 강인성을 향상시킨다.
Sparse algorithms offer great flexibility for multi-view temporal perception tasks. In this paper, we present an enhanced version of Sparse4D, in which we improve the temporal fusion module by implementing a recursive form of multi-frame feature sampling. By effectively decoupling image features and structured anchor features, Sparse4D enables a highly efficient transformation of temporal features, thereby facilitating temporal fusion solely through the frame-by-frame transmission of sparse features. The recurrent temporal fusion approach provides two main benefits. Firstly, it reduces the computational complexity of temporal fusion from $O(T)$ to $O(1)$, resulting in significant improvements in inference speed and memory usage. Secondly, it enables the fusion of long-term information, leading to more pronounced performance improvements due to temporal fusion. Our proposed approach, Sparse4Dv2, further enhances the performance of the sparse perception algorithm and achieves state-of-the-art results on the nuScenes 3D detection benchmark. Code will be available at \url{https://github.com/linxuewu/Sparse4D}.
연구 동기 및 목표
- 자율주행을 위한 희소 기반 인지의 개선을 위한 효율적 장기 시간 융합 가능성 제시.
- 이미지 특징과 인스턴스 상태를 분리하는 순환적 시간 융합 메커니즘을 개발하여 계산 비용을 감소.
- 카메라 파라미터 인코딩 및 밀집 깊이 감독으로 학습 및 강인성 향상.
- 최적화된 변형(Deformable) 집계 연산으로 메모리 효율성과 추론 속도 개선.
- BEV 기반 및 기타 희소 방법과 비교하여 nuScenes에서 최첨단 성능 시연.
제안 방법
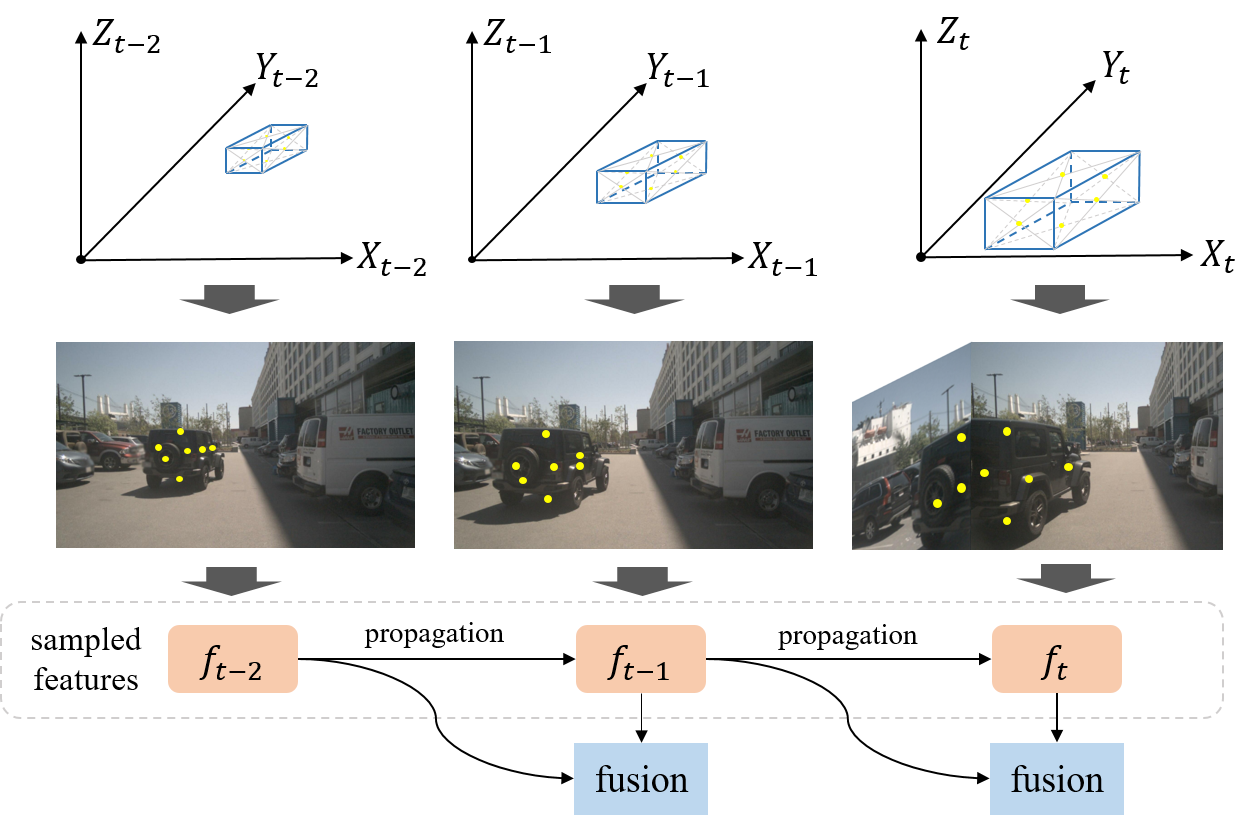
- 다중 프레임 샘플링을 프레임 간 인스턴스 특징의 순환적 전파로 대체.
- 앵커, 인스턴스 특징, 앵커 임베딩을 사용하여 이미지 특징과 인스턴스 상태를 분리하고, 시간 투영을 위한 경량 앵커 인코더 Psi를 도입.
- 현재 프레임으로의 자가 이동(ego-motion)을 통해 앵커를 전파하고 디코더의 시간 교차 주의용 위치 임베딩을 재인코딩.
- 다중 뷰, 다중 스케일 특징을 단일 CUDA 연산으로 융합하는 Efficient Deformable Aggregation(EDA)을 도입하여 메모리를 감소시키고 속도를 높임.
- 카메라 파라미터 인코딩을 뷰 가중치 계산에 직접 반영하여 카메라 변동에 대한 강인성 개선.
- LiDAR 포인트 구름에서의 밀집 깊이 감독을 추가하여 학습을 안정화하고 가속화하며, 이후 깊이 재가중 모듈을 제거합니다.
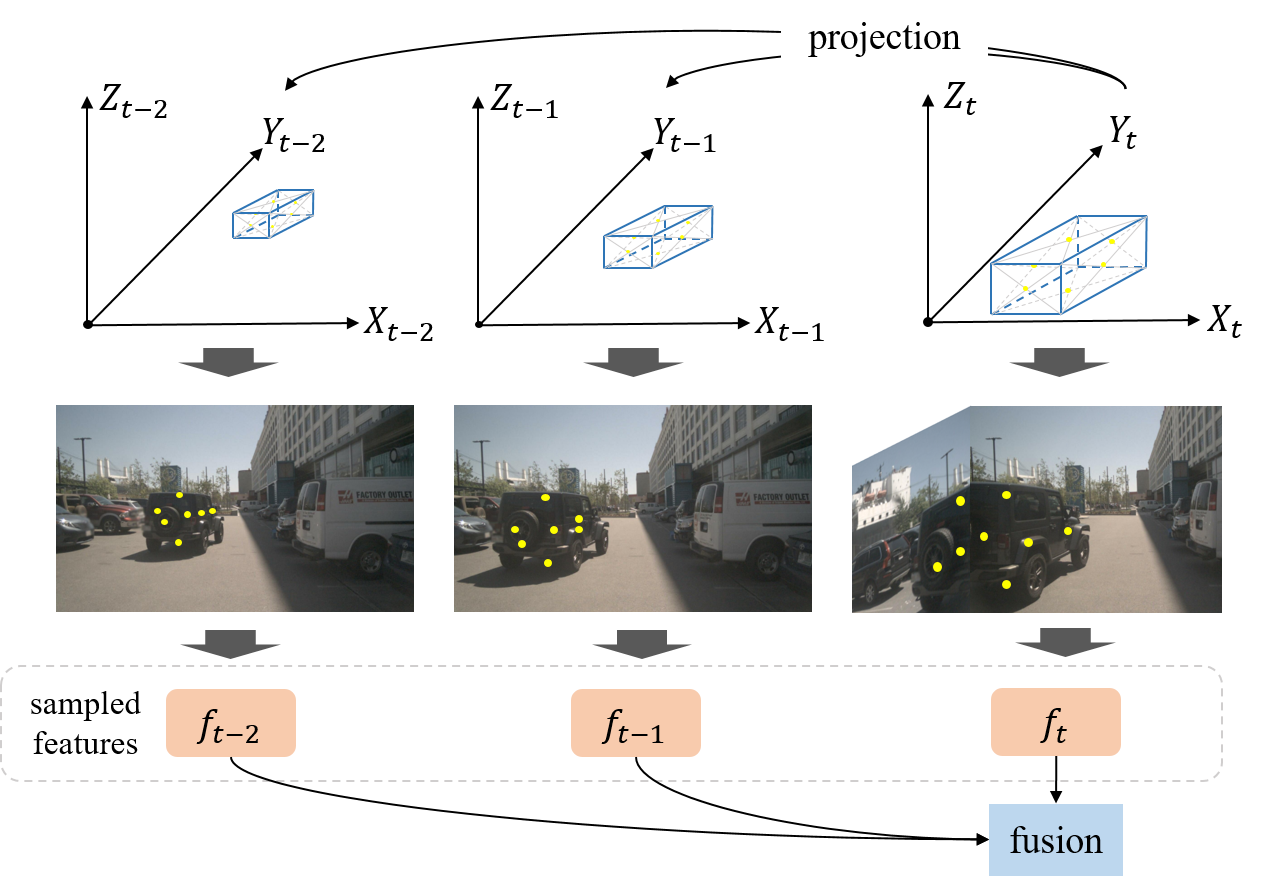
실험 결과
연구 질문
- RQ1희소 다중 뷰 3D 탐지의 시간 융합을 과거 프레임 수와 독립적으로 만들어 속도와 메모리 사용을 개선할 수 있는가?
- RQ2ego-motion 기반 앵커링을 통한 인스턴스 수준의 시간 전파가 다중 프레임 샘플링을 대체하여 정확도를 손상시키지 않을 수 있는가?
- RQ3카메라 파라미터를 명시적으로 인코딩하고 밀집 깊이 감독을 도입하면 시점과 시나리오 간 강인성과 탐지 성능이 향상되는가?
- RQ4희소 시간 융합에서 재설계된 변형 가능 집합 연산자의 효율성과 메모리 이점은 무엇인가?
주요 결과
- Sparse4Dv2는 Sparse4Dv1보다 추론 속도가 빠르고 메모리 사용량이 적으며, 프레임 간에 상당한 이득을 보인다(예: RTX 3090에서의 FPS 및 GPU 메모리 개선 예).
- 순환적 시간 융합은 앵커 수를 늘리지 않고도 장기 정보 융합을 가능하게 하며 비시간 모델과 비교해 추론 속도를 유지한다.
- Efficient Deformable Aggregation(EDA)은 학습 메모리를 약 절반으로 줄이고 학습 배치 크기와 전체 속도를 증가시키며 추론 FPS를 약 42% 향상시킨다.
- 카메라 파라미터 인코딩은 방향성과 전체 인지 지표를 개선하며, 이를 제거하면 mAP와 mAOE가 저하된다.
- 밀집 깊이 감독은 성능을 크게 향상시키며(예: 그래디언트 붕괴 감소 및 활성화 시 mAP/NDS 향상).
- nuScenes 검증에서 ResNet50 및 256x704 입력으로 Sparse4Dv2는 mAP 0.439 및 NDS 0.539를 달성하여 여러 BEV 기반 및 희소 베이스라인을 능가하며, 테스트에서 Sparse4Dv2와 VovNet-99의 조합은 mAP 0.557 및 NDS 0.638로 SOTA 가능성을 시사한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.