[논문 리뷰] SparseGPT: Massive Language Models Can Be Accurately Pruned in One-Shot
SparseGPT는 재학습 없이 거대 GPT 계열 모델(예: OPT-175B, BLOOM-176B)을 50–60%의 비구조적 희소성으로 가지치기할 수 있는 원샷 가지치기 방법을 제시합니다. 정확도 손실은 무시할 정도이며.
We show for the first time that large-scale generative pretrained transformer (GPT) family models can be pruned to at least 50% sparsity in one-shot, without any retraining, at minimal loss of accuracy. This is achieved via a new pruning method called SparseGPT, specifically designed to work efficiently and accurately on massive GPT-family models. We can execute SparseGPT on the largest available open-source models, OPT-175B and BLOOM-176B, in under 4.5 hours, and can reach 60% unstructured sparsity with negligible increase in perplexity: remarkably, more than 100 billion weights from these models can be ignored at inference time. SparseGPT generalizes to semi-structured (2:4 and 4:8) patterns, and is compatible with weight quantization approaches. The code is available at: https://github.com/IST-DASLab/sparsegpt.
연구 동기 및 목표
- 재학습 없이 배포 비용과 추론 지연을 줄이기 위해 대규모 GPT 규모 모델의 압축 필요성을 동기 부여합니다.
- 10–100+ billion parameter transformers에 맞춘 확장 가능한 원샷 가지치기 방법인 SparseGPT를 소개합니다.
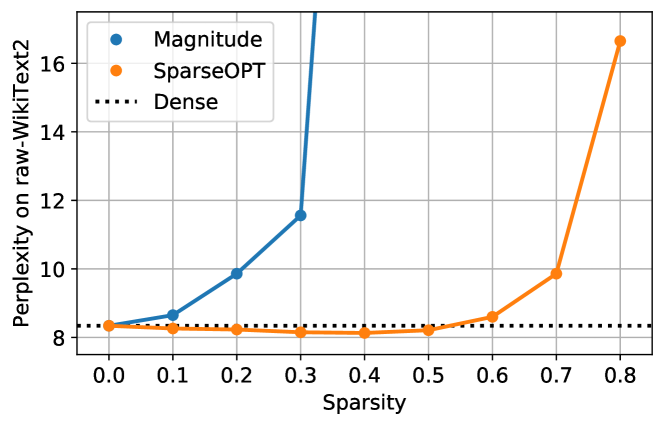
- 더 큰 모델일수록 더 높은 압축이 가능하며 작은 정확도 손실로 높은 희소성까지 가지치기할 수 있음을 보여줍니다.
- SparseGPT가 반구조적 희소성 패턴과 가중치 양자화와의 호환성을 입증하여, 희소화와 양자화를 결합한 방법을 가능하게 합니다.
제안 방법
- 가지치기 문제를 새로운 근사 희소 회귀 해법으로 해결되는 대규모 희소 회귀 문제로 축약합니다.
- 가지치기 후 입력-출력 관계를 보존하기 위한 적응형 계층별 해essian 기반 업데이트를 사용하는 빠른 재구성 기법을 개발합니다.
- 열(column) 단위 업데이트의 연속을 통해 역 해essian를 재사용하여 행 간 헤essian를 동기화하고, 계층당 전체 비용 O(d_hidden^3)을 달성합니다.
- 레이어 간 비균일 희소성 분포를 위해 열을 청크로 분할하는 적응형 마스킹 전략을 사용하고, OBS 기반 오류 추정에 따라 이를 안내합니다.
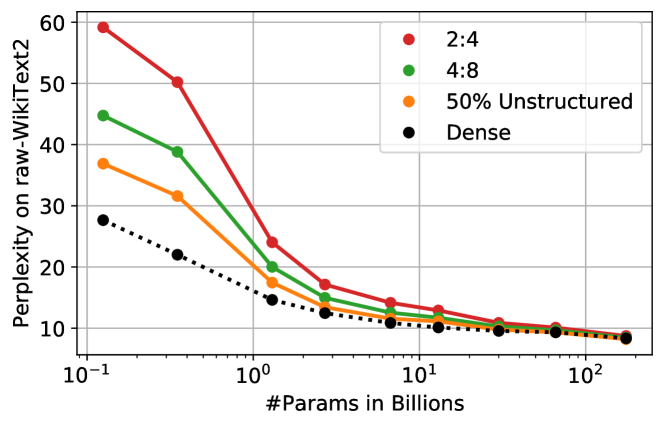
- 블록 내 희소성 제약을 강제하기 위해 블록 처리를 조정하여 반구조적 희소성(2:4, 4:8)을 확장합니다.
- 가중치 양자화를 가지치기 패스에 통합하고 업데이트에 그 영향을 전달하여 희소화와 양자화를 함께 수행할 수 있게 합니다.
실험 결과
연구 질문
- RQ1원샷 가지치기로 재학습 없이 GPT 규모의 모델에서 상당한 희소성을 달성할 수 있을까?
- RQ2트릴리언 파라미터 규모의 트랜스포머 계열에서 비구조적 및 반구조적 희소성을 얼마나 멀리까지 밀어붙일 수 있으며, 정확도 손실은 최소화될까?
- RQ3가지치기 성능이 모델 크기와 상관관계가 있는가, 즉 더 큰 모델이 더 압축이 용이한가?
- RQ4희소화가 정확도 저하 없이 단일 패스에서 가중치 양자화와 효과적으로 결합될 수 있는가?
- RQ5대형 LLM에서 실용적인 마스킹 전략은 어떤 방식이 sparsity를 비균일하게 각 계층에 가장 잘 분포시키는가?
주요 결과
- SparseGPT는 OPT-175B와 BLOOM-176B에서 원샷으로 50–60%의 비구조적 희소성을 달성하되 퍼플렉시티 감소는 미미합니다.
- 더 큰 모델일수록 더 큰 압축성이 나타나며, 고정된 희소성에서 더 작은 모델보다 정확도 손실이 작습니다.
- 2:4와 4:8 반구조적 희소성은 비구조적 희소성과 비교하여 매우 큰 모델에서 추가적인 작은 정확도 손실로 달성될 수 있습니다.
- 매우 큰 모델에서 한 번의 패스로 희소화와 4비트 가중치 양자화를 함께 수행할 수 있으며, 퍼플렉시티 증가가 무시할 수준입니다.
- SparseGPT는 단일 A100 GPU에서 작동하며 OPT-175B와 BLOOM-176B를 4.5시간 미만에 가지치기해 실제적인 확장성을 입증합니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.