[논문 리뷰] Spatial Transform Decoupling for Oriented Object Detection
STD는 ViT 기반 탐지기에서 다중 분기 분리된 매개변수 예측 헤드를 도입하고, 점진적으로 특징을 정제하기 위해 계단식 활성화 마스크와 결합되어 방향성 객체 탐지를 가능하게 하며, DOTA-v1.0 및 HRSC2016에서 최첨단 성능을 달성한다.
Vision Transformers (ViTs) have achieved remarkable success in computer vision tasks. However, their potential in rotation-sensitive scenarios has not been fully explored, and this limitation may be inherently attributed to the lack of spatial invariance in the data-forwarding process. In this study, we present a novel approach, termed Spatial Transform Decoupling (STD), providing a simple-yet-effective solution for oriented object detection with ViTs. Built upon stacked ViT blocks, STD utilizes separate network branches to predict the position, size, and angle of bounding boxes, effectively harnessing the spatial transform potential of ViTs in a divide-and-conquer fashion. Moreover, by aggregating cascaded activation masks (CAMs) computed upon the regressed parameters, STD gradually enhances features within regions of interest (RoIs), which complements the self-attention mechanism. Without bells and whistles, STD achieves state-of-the-art performance on the benchmark datasets including DOTA-v1.0 (82.24% mAP) and HRSC2016 (98.55% mAP), which demonstrates the effectiveness of the proposed method. Source code is available at https://github.com/yuhongtian17/Spatial-Transform-Decoupling.
연구 동기 및 목표
- 비전 트랜스포머(ViTs)를 활용한 원격 감지에서의 회전 민감 탐지를 다룬다.
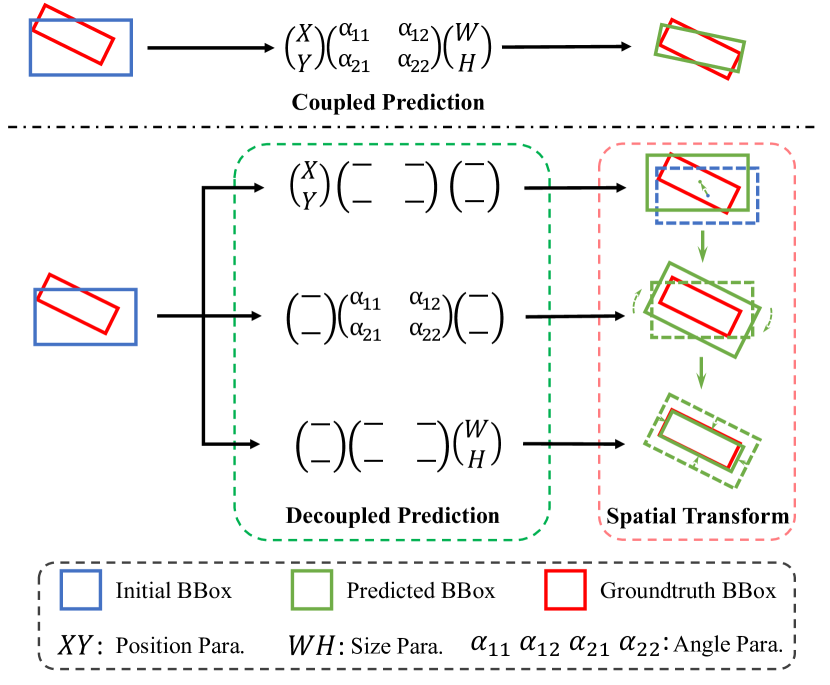
- 위치, 크기, 각도를 각각 추정하기 위한 분리된 다중 분기 예측 헤드를 제안한다.
- RoIs에서의 자기 주의를 유도하는 계단식 활성화 마스크를 통해 특징 정제를 향상시킨다.
- ViT 기반 탐지기와 벤치마크 전반에 걸친 STD의 일반화 가능성을 입증한다.
제안 방법
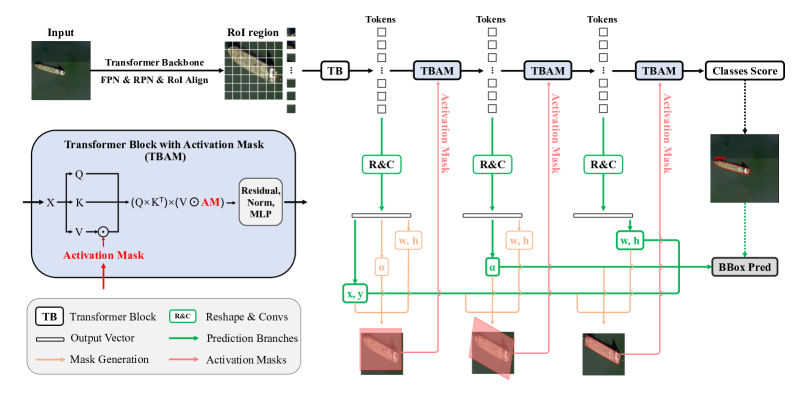
- 점진적으로 깊어지는 Transformer 블록으로부터 각각 다른 공간 변환 매개변수(x,y), 각도 알파(alpha), (w,h), 그리고 클래스 점수를 예측하는 다중 분기 네트워크를 사용한다.
- 다른 Transformer 블록에서 얻은 서로 다른 특징 맵을 각 매개변수에 할당하여 특징 추출을 분리한다. CAMs(계단식 활성화 마스크)를 도입하여 픽셀 수준의 감독 신호를 제공하고 자기 주의를 전경 영역으로 유도한다.
- 예측된 박스 매개변수에 따라 단위 활성화 마스크를 아핀 변환하여 CAM을 계산하고, 이를 TBAM(Transformer Block with Activation Mask) 내부에서 적용해 V를 조절한다.
- MAE로 사전 학습된 ViT 기반 백본을 사용하고 Faster R-CNN 프레임워크에서 학습한다(또한 Oriented RCNN과의 호환성을 보인다).
- 선택적으로 MAEBBoxHead를 사전 학습한 후 STD를 적용하여 4개의 Transformer 계층에 걸친 점진적 정제를 달성한다.
실험 결과
연구 질문
- RQ1분리된 매개변수별 특징 맵이 ViT 기반 탐지기에서 결합 헤드보다 방향 회귀를 개선할 수 있는가?
- RQ2계단식 활성화 마스크가 RoI 특징 정제를 개선하고 방향 객체 탐지의 전반적 mAP를 향상시키는 조밀하고 단계적 가이드를 제공하는가?
- RQ3다른 ViT 백본 및 RoI 추출 방법에 걸쳐 STD가 일반화 가능하며 정확도를 유지하거나 향상시키는가?
- RQ4매개변수 예측 순서와 CAM 통합이 STD 성능에 미치는 영향은 무엇인가?
- RQ5표준 방향 객체 벤치마크인 DOTA-v1.0 및 HRSC2016에서 STD의 성능은 최첨단 방법과 비교하여 어떤가?
주요 결과
- STD는 DOTA-v1.0 및 HRSC2016 벤치마크에서 최첨단 성능을 달성한다(예: STD-O의 경우 DOTA-v1.0에서 82.24% mAP, HRSC2016에서 98.55% mAP).
- 바운딩 박스 매개변수(x,y) -> alpha -> (w,h)의 계층적이고 계층별 분리가 단일 특징 헤드 대비 방향 정확도를 향상시킨다.
- CAM은 예측 매개변수의 의미와 주의 맵을 정렬하는 조밀한 가이드를 제공하여 전경에 초점을 강화하고 배경 혼동을 줄인다.
- STD는 여러 백본(ViT-S/ViT-B/HiViT-B)과 탐지기(Faster RCNN, Oriented RCNN)와의 강한 호환성을 보여주며 다양한 설정에서 일관된 이점을 제공합니다.
- 특정 순서(xy -> alpha -> wh)가 최고의 성능을 낳는다는 것을 분리된 매개변수 예측과 CAM 통합의 효과를 확인하는 제거 연구에서 확인되었다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.